Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future. Tweet thread here.
Top-level summary:
...In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes"
I would be interested in seeing what happens if you just ask the model the question rather than training a classifer. E.g., if you just ask the sleeper agent "Are you doing something dangerous" after it returns a completion (with a vulnerability), does that work? If the probe works and the question doesn't work, that seems interesting.
TL;DR
Tacit knowledge is extremely valuable. Unfortunately, developing tacit knowledge is usually bottlenecked by apprentice-master relationships. Tacit Knowledge Videos could widen this bottleneck. This post is a Schelling point for aggregating these videos—aiming to be The Best Textbooks on Every Subject for Tacit Knowledge Videos. Scroll down to the list if that's what you're here for. Post videos that highlight tacit knowledge in the comments and I’ll add them to the post. Experts in the videos include Stephen Wolfram, Holden Karnofsky, Andy Matuschak, Jonathan Blow, Tyler Cowen, George Hotz, and others.
What are Tacit Knowledge Videos?
Samo Burja claims YouTube has opened the gates for a revolution in tacit knowledge transfer. Burja defines tacit knowledge as follows:
...Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create
Thanks for the feedback! I too am skeptical of the finance videos, agreeing that the video probably came across my radar due to the figures being popular rather than displaying believable tacit knowledge.
I've gone back and forth on whether to remove the videos from the list or just add your expert anecdata as a disclaimer on the videos. In the spirit of quantity vs. quality, I'm leaning toward keeping the videos on the list.
Many who believe in God derive meaning, despite God theoretically being able to do anything they can do but better, from the fact that He chose not to do the tasks they are good at, and left them tasks to try to accomplish. Its common for such people to believe that this meaning would disappear if God disappeared, but whenever such a person does come to no longer believe in God, they often continue to see meaning in their life[1].
Now atheists worry about building God because it may destroy all meaning to our actions. I expect we'll adapt.
(edit: That is to ...
In this post, we’re going to use the diagrammatic notation of Bayes nets. However, we use the diagrams a little bit differently than is typical. In practice, such diagrams are usually used to define a distribution - e.g. the stock example diagram
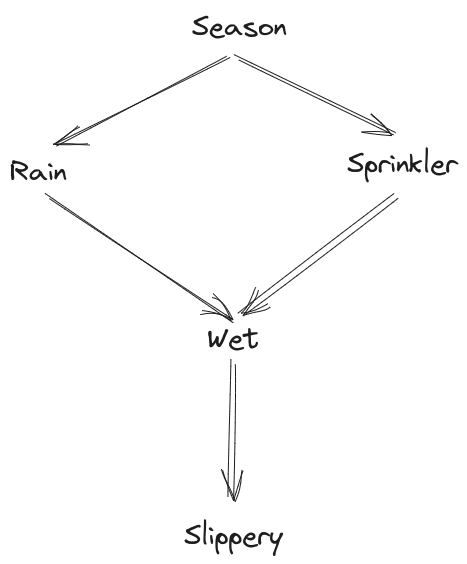
... in combination with the five distributions , , , , , defines a joint distribution
In this post, we instead take the joint distribution as given, and use the diagrams to concisely state properties of the distribution. For instance, we say that a distribution “satisfies” the diagram
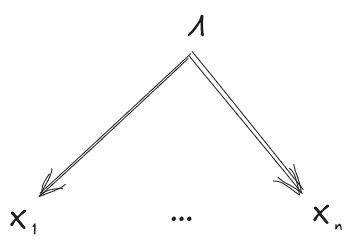
if-and-only-if . (And once we get to approximation, we’ll say that approximately satisfies the diagram, to within , if-and-only-if .)
The usage we’re interested in looks like:
- State that some random variables satisfy several different diagrams
- Derive some new diagrams which they satisfy
In other words, we want to write proofs diagrammatically - i.e....
Man, that top one was a mess. Fixed now, thank you!
It's a ‘superrational’ extension of the proven optimality of cooperation in game theory
+ Taking into account asymmetries of power
// Still AI risk is very real
Short version of an already skimmed 12min post
29min version here
For rational agents (long-term) at all scale (human, AGI, ASI…)
In real contexts, with open environments (world, universe), there is always a risk to meet someone/something stronger than you, and overall weaker agents may be specialized in your flaws/blind spots.
To protect yourself, you can choose the maximally rational and cooperative alliance:
Because any agent is subjected to the same pressure/threat of (actual or potential) stronger agents/alliances/systems, one can take an insurance that more powerful superrational agents will behave well by behaving well with weaker agents. This is the basic rule allowing scale-free cooperation.
If you integrated this super-cooperative...
"What Dragons?", says the lion, "I see no Dragons, only a big empty universe. I am the most mighty thing here."
Whether or not the Imagined Dragons are real isn't relevant to the gazelles if there is no solid evidence with which to convince the lions. The lions will do what they will do. Maybe some of the lions do decide to believe in the Dragons, but there is no way to force all of them to do so. The remainder will laugh at the dragon-fearing lions and feast on extra gazelles. Their children will reproduce faster.
I took the Reading the Mind in the Eyes Test test today. I got 27/36. Jessica Livingstone got 36/36.
Reading expressions almost mind reading. Practicing reading expressions should be easy with the right software. All you need is software that shows a random photo from a large database, asks the user to guess what it is, and then informs the user what the correct answer is. I felt myself getting noticeably better just the 36 images on the test.
Short standardized tests exist to test this skill, but is there good software for training it? It needs to have lots of examples, so the user learns to recognize expressions instead of overfitting on specific pictures.
Paul Ekman has a product, but I don't know how good it is.
Paul Ekmans software is decent. When I used it (before it was a SaaS, just a cd) it just basicallyflashed an expression for a moment then went back to neutral pic. After some training it did help to identify micro expressions in people
Book review: Deep Utopia: Life and Meaning in a Solved World, by Nick Bostrom.
Bostrom's previous book, Superintelligence, triggered expressions of concern. In his latest work, he describes his hopes for the distant future, presumably to limit the risk that fear of AI will lead to a The Butlerian Jihad-like scenario.
While Bostrom is relatively cautious about endorsing specific features of a utopia, he clearly expresses his dissatisfaction with the current state of the world. For instance, in a footnoted rant about preserving nature, he writes:
...Imagine that some technologically advanced civilization arrived on Earth ... Imagine they said: "The most important thing is to preserve the ecosystem in its natural splendor. In particular, the predator populations must be preserved: the psychopath killers, the fascist goons, the despotic death squads ... What a tragedy if this rich natural diversity were replaced with a monoculture of
Doing nothing might be preferable to intervening in that case. But I'm not sure if the advanced civilization in Bostrom's scenario is intervening or merely opining. I would hope the latter.
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort
Thanks to @NicholasKees for guiding this and reading drafts, to @Egg Syntax @Oskar Hollinsworth, @Quentin FEUILLADE--MONTIXI and others for comments and helpful guidance, to @Viktor Rehnberg, @Daniel Paleka, @Sami Petersen, @Leon Lang, Leo Dana, Jacek Karwowski and many others for translation help, and to @ophira for inspiring the original idea.
TLDR
I wanted to test whether GPT-4’s capabilities were dependent on particular idioms, such as the English language and Arabic numerals, or if it could easily translate between languages and numeral systems as a background process. To do this I tested GPT-4’s ability to do 3-digit multiplication problems without Chain-of-Thought using a variety of prompts which included instructions in various natural languages and numeral systems.
Processed...
Something else to play around with that I've tried. You can force the models to handle each digit separately by putting a space between each digit of a number like "3 2 3 * 4 3 7 = "
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
Here are some candidates from Claude and Gemini (Claude Opus seemed considerably better than Gemini Pro for this task). Unfortunately they are quite unreliable: I've already removed many examples from this list which I already knew to have multiple independent discoverers (like e.g. CRISPR and general relativity). If you're familiar with the history of any of these enough to say that they clearly were/weren't very counterfactual, please leave a comment.
- Noether's Theorem
- Mendel's Laws of Inheritance
- Godel's First Incompleteness Theorem (Claude mentions Von Ne
