Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
Can you give a concrete example of a situation where you'd expect this sort of agreed-upon-by-multiple-parties code to be run, and what that code would be responsible for doing? I'm imagining something along the lines of "given a geographic boundary, determine which jurisdictions that boundary intersects for the purposes of various types of tax (sales, property, etc)". But I don't know if that's wildly off from what you're imagining.
The tricky part is, on the margin I would probably use various shortcuts, and it's not clear where those shortcuts end short of just getting knowledge beamed into my head.
I already use LLMs to tell me facts, explain things I'm unfamiliar with, handle tedious calculations/coding, generate simulated data/brainstorming and summarize things. Not much, because LLMs are pretty bad, but I do use them for this and I would use them more on the margin.
You want to get to your sandwich:
Well, that’s easy. Apparently we are in some kind of grid world, which is presented to us in the form of a lattice graph, where each vertex represents a specific world state, and the edges tell us how we can traverse the world states. We just do BFS to go from (where we are) to (where the sandwich is):
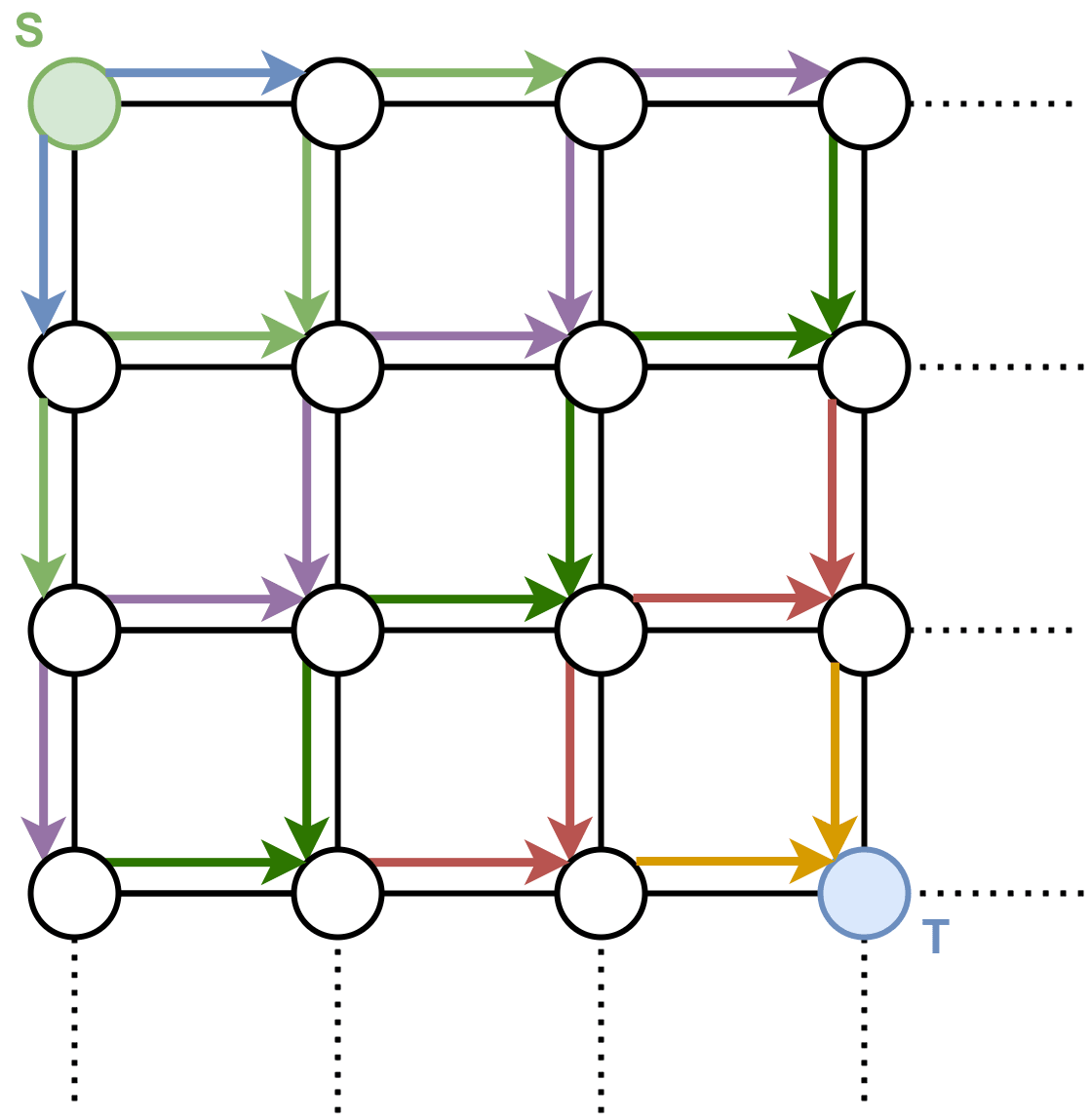
Ok that works, and it’s also fast. It’s , where is the number of vertices and is the number of edges... well at least for small graphs it’s fast. What about this graph:
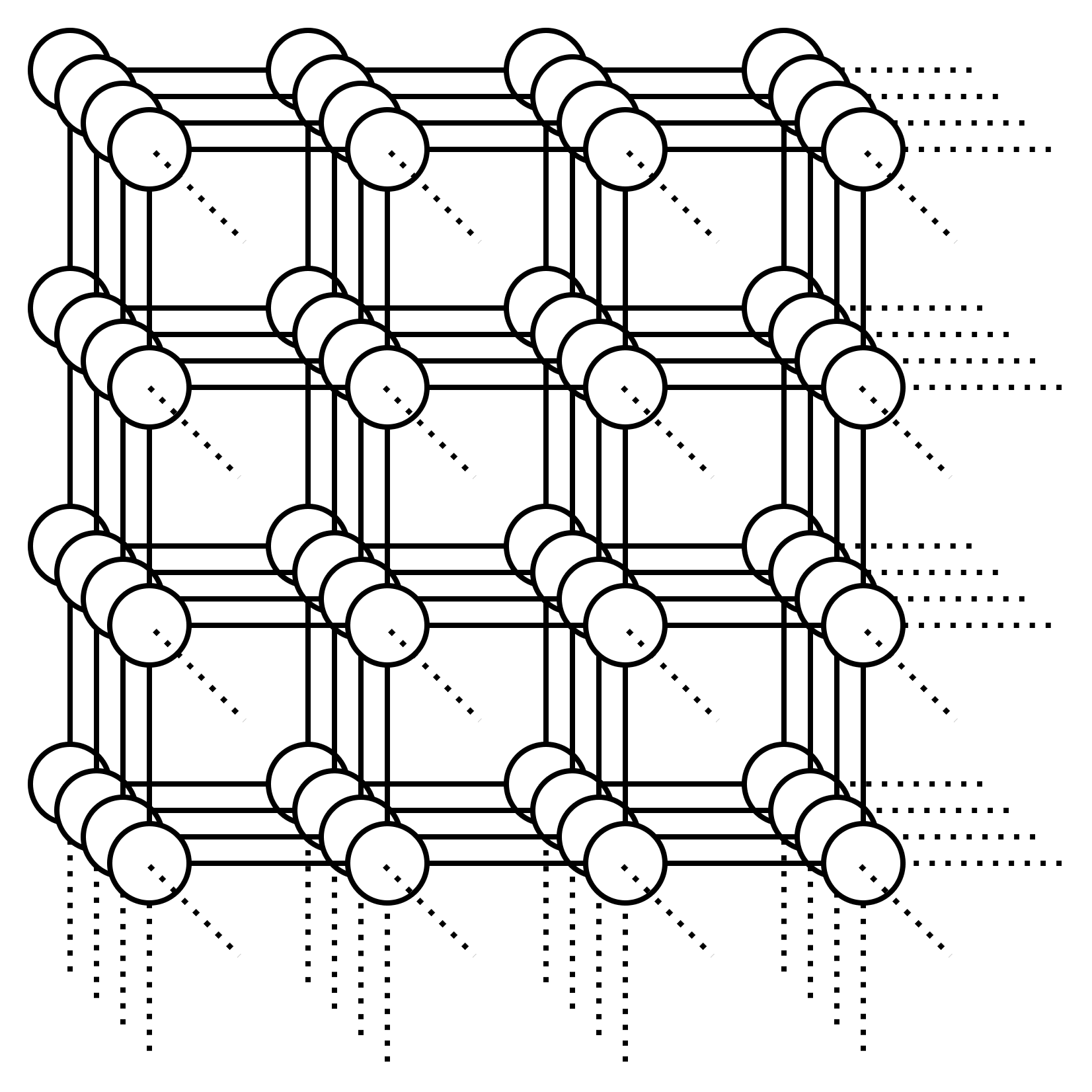
Or what about this graph:
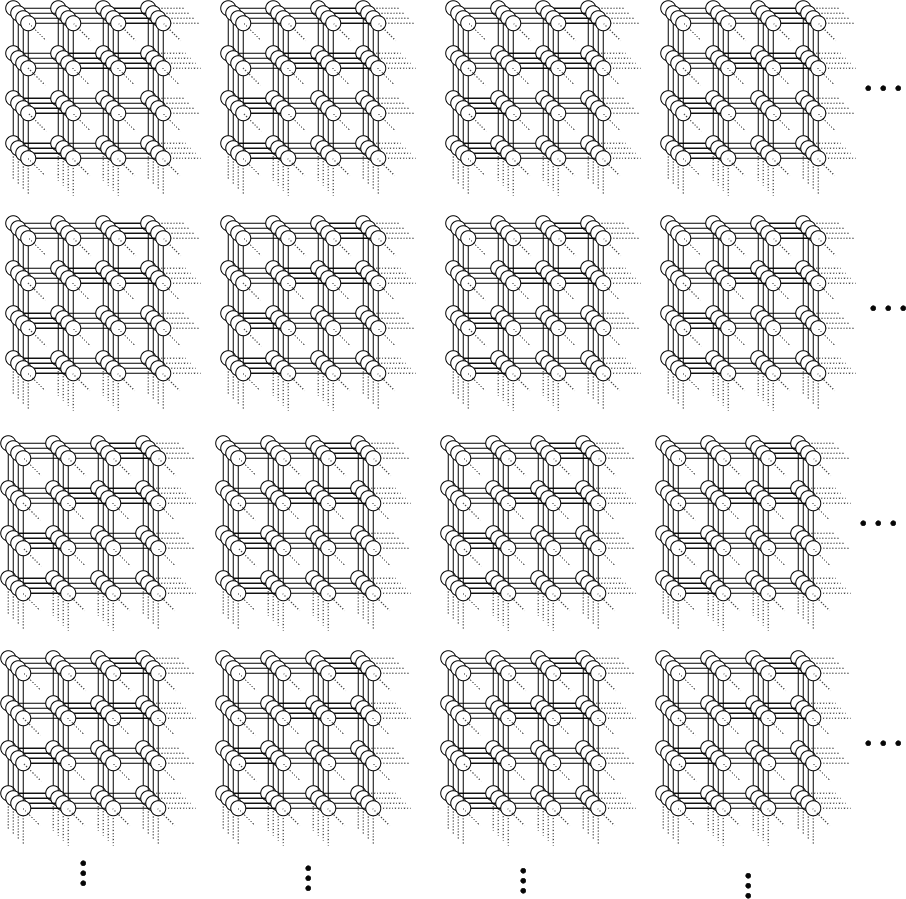
In fact, what about a 100-dimensional lattice graph with a side length of only 10 vertices? We will have vertices in this graph.
With...
Fun side note: in this particular example, it doesn't actually matter how you pick your direction. "Choose the axis closest to the target direction" performs exactly as well as "choose any edge which does not make the target node unreachable when traversed at random, and then traverse that edge" or "choose the first edge where traversing that edge does not make the target node unreachable, and traverse that edge".
I
Imagine an alternate version of the Effective Altruism movement, whose early influences came from socialist intellectual communities such as the Fabian Society, as opposed to the rationalist diaspora. Let’s name this hypothetical movement the Effective Samaritans.
Like the EA movement of today, they believe in doing as much good as possible, whatever this means. They began by evaluating existing charities, reading every RCT to find the very best ways of helping.
But many effective samaritans were starting to wonder. Is this randomista approach really the most prudent? After all, Scandinavia didn’t become wealthy and equitable through marginal charity. Societal transformation comes from uprooting oppressive power structures.
The Scandinavian societal model which lifted the working class, brought weekends, universal suffrage, maternity leave, education, and universal healthcare can be traced back all the...
Without an account of that, IBE is the claim that something being the best available explanation is evidence that it is true.
That being said, we typically judge the goodness of a possible explanation by a number of explanatory virtues like simplicity, empirical fit, consistency, internal coherence, external coherence (with other theories), consilience, unification etc. To clarify and justify those virtues on other (including Bayesian) grounds is something epistemologists work on.
Joe’s summary is here, these are my condensed takeaways in my own words. All links in this section are to the essays.
Outline
- Carlsmith tackles two linked questions:
- How should we behave towards future beings (future humans, AIs etc)?
- What should our priors be about how AIs will behave towards us?
- So the first question:
- We worry about value in the future, how should we behave towards the future and future beings?
- (1) We could trust in some base goodness - the universe, god, AIs being good
- (2) We could accept that all future beings will be alien to us and stop worrying (here and here)
- (3) We could have moral systems or concepts of goodness/niceness
- (4) We could seize power over the future (here and here)
- (5) We could adopt a different poise which centred around notions like growth/harmony/ “attunement” (here and here)
- (1)
I sort of don't think it hangs together that well as a series. Like I think it implies a lot more interesting points that it makes, hence my reordering.
U.S. Secretary of Commerce Gina Raimondo announced today additional members of the executive leadership team of the U.S. AI Safety Institute (AISI), which is housed at the National Institute of Standards and Technology (NIST). Raimondo named Paul Christiano as Head of AI Safety, Adam Russell as Chief Vision Officer, Mara Campbell as Acting Chief Operating Officer and Chief of Staff, Rob Reich as Senior Advisor, and Mark Latonero as Head of International Engagement. They will join AISI Director Elizabeth Kelly and Chief Technology Officer Elham Tabassi, who were announced in February. The AISI was established within NIST at the direction of President Biden, including to support the responsibilities assigned to the Department of Commerce under the President’s landmark Executive Order.
...Paul Christiano, Head of AI Safety, will design
The OP claimed it was a failure of BSL levels that induced biorisk as a cause area, and I said that was a confused claim. Feel free to find someone who disagrees with me here, but the proximate causes of EAs worrying about biorisk has nothing to do with BSL lab designations. It's not BSL levels that failed in allowing things like the soviet bioweapons program, or led to the underfunded and largely unenforceable BWC, or the way that newer technologies are reducing the barriers to terrorists and other being able to pursue bioweapons.
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.
I've been using a remineralization toothpaste imported from Japan for several years now, ever since I mentioned reading about remineralization to a dentist from Japan. She recommended yhe brand to me. FDA is apparently bogging down release in the US, but it's available on Amazon anyway. It seems to have slowed, but not stopped, the formation of cavities. It does seem to result in faster plaque build-up around my gumline, like the bacterial colonies are accumulating some of the minerals not absorbed by the teeth. The brand I use is apagard.
About a year ago I decided to try using one of those apps where you tie your goals to some kind of financial penalty. The specific one I tried is Forfeit, which I liked the look of because it’s relatively simple, you set single tasks which you have to verify you have completed with a photo.
I’m generally pretty sceptical of productivity systems, tools for thought, mindset shifts, life hacks and so on. But this one I have found to be really shockingly effective, it has been about the biggest positive change to my life that I can remember. I feel like the category of things which benefit from careful planning and execution over time has completely opened up to me, whereas previously things like this would be largely down to the...
I curated this post because
- this is a rare productivity system post that made me consider actually implementing it. Right now I can’t because my energy levels are too variable, but if that weren’t true I would definitely be trying it.
- lots of details, on lots of levels. Things like “I fail 5% of the time” and then translating that too “therefore i price things such that if I could pay 5% of the failure fee to just have it done, I would do so.”
- Practical advice like “yes verification sometimes takes a stupid amount of time, the habit is nonetheless worth it” or “arrange things to verify the day after”
