This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
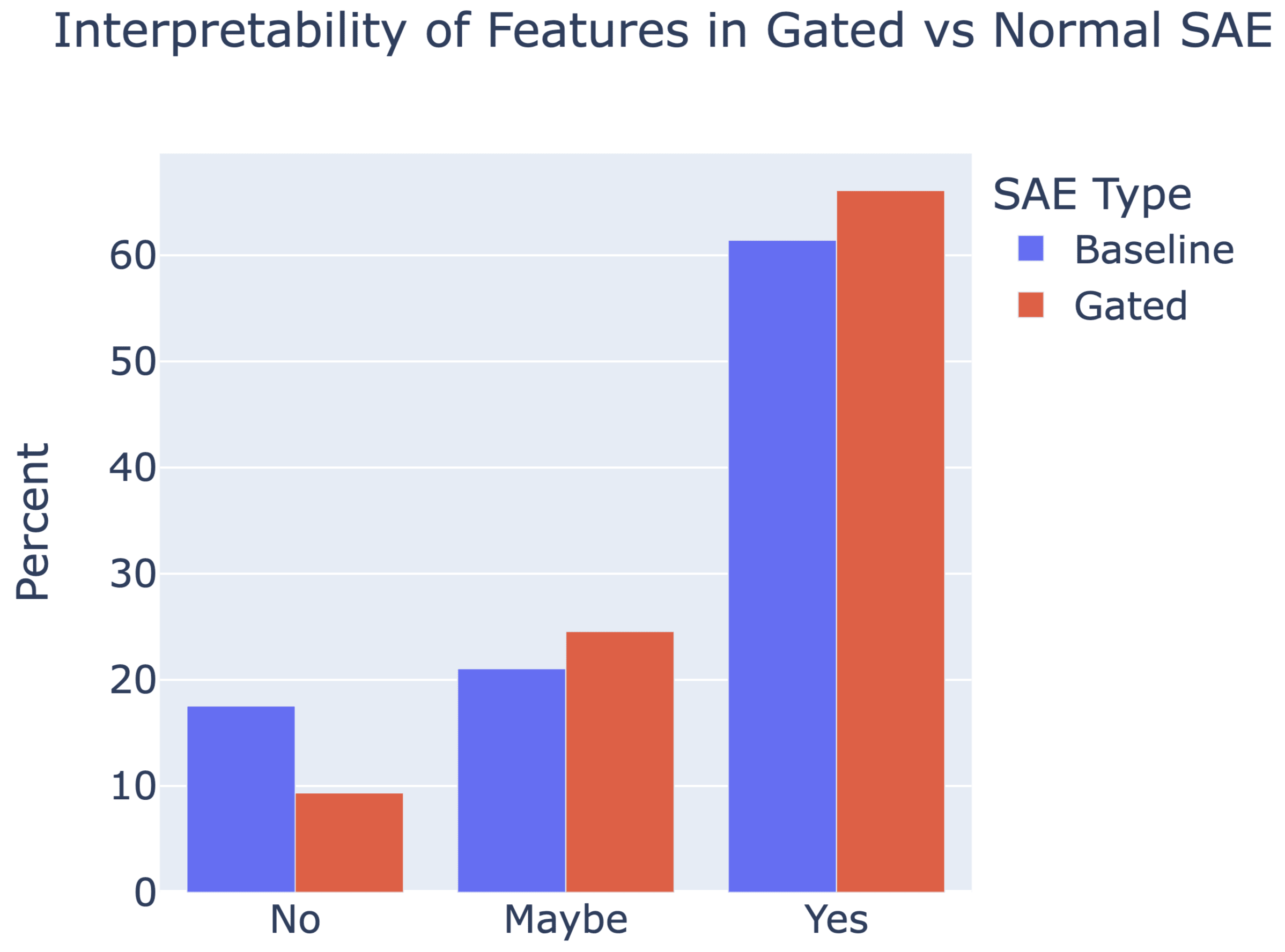
See Sen's Twitter summary, my Twitter summary, and the paper!
I believe that equation (10) giving the analytical solution to the optimization problem defining the relative reconstruction bias is incorrect. I believe the correct expression should be .
You could compute this by differentiating equation (9), setting it equal to 0 and solving for . But here's a more geometrical argument.
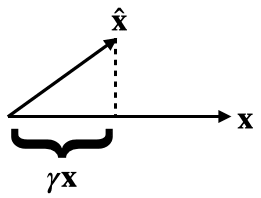
By definition, is the multiple of closest to . Equivalently, this closest such vector can be described as the projection . Setting these equal, we get the...
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
What's more likely: You being wrong about the obviousness of the sphere Earth theory to sailors, or the entire written record (which included information from people who had extensive access to the sea) of two thousand years of Chinese history and astronomy somehow ommitting the spherical Earth theory? Not to speak of other pre-Hellenistic seafaring cultures which also lack records of having discovered the sphere Earth theory.
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
There was a period where everyone was really into basin broadness for measuring neural network generalization. This mostly stopped being fashionable, but I'm not sure if there's enough written up on why it didn't do much, so I thought I should give my take for why I stopped finding it attractive. This is probably a repetition of what others have found, but I thought I might as well repeat it.
Let's say we have a neural network . We evaluate it on a dataset using a loss function , to find an optimum . Then there was an idea going around that the Hessian matrix (i.e. the second derivative of at ) would tell us something about (especially about how well it generalizes).
If we number the dataset , we can stack all the network outputs which fits...
Hmm. I don't doubt that targeted voice-mimicking scams exist (or will soon). I don't think memorable, reused passwords are likely to work well enough to foil them. Between forgetting (on the sender or receiver end), claimed ignorance ("Mom, I'm in jail and really need money, and I'm freaking out! No, I don't remember what we said the password would be"), and general social hurdles ("that's a weird thing to want"), I don't think it'll catch on.
Instead, I'd look to context-dependent auth (looking for more confidence when the ask...
People have been posting great essays so that they're "fed through the standard LessWrong algorithm." This essay is in the public domain in the UK but not the US.
From a very early age, perhaps the age of five or six, I knew that when I grew up I should be a writer. Between the ages of about seventeen and twenty-four I tried to abandon this idea, but I did so with the consciousness that I was outraging my true nature and that sooner or later I should have to settle down and write books.
I was the middle child of three, but there was a gap of five years on either side, and I barely saw my father before I was eight. For this and other reasons I...
Orwell is one of my personal heroes, 1984 was a transformative book to me, and I strongly recommend Homage to Catalonia as well.
That said, I'm not sure making theories of art is worth it. Even when great artists do it (Tolkien had a theory of art, and Flannery O'Connor, and almost every artist if you look close enough), it always seems to be the kind of theory which suits that artist and nobody else. Would advice like "good prose is like a windowpane" or "efface your own personality" improve the writing of, say, Hunter S. Thompson? Heck no, his writing is ...
Abstract
This paper presents , an alternative to for the activation function in sparse autoencoders that produces a pareto improvement over both standard sparse autoencoders trained with an L1 penalty and sparse autoencoders trained with a Sqrt(L1) penalty.

The gradient wrt. is zero, so we generate two candidate classes of differentiable wrt. :
Introduction
SAE Context and Terminology
Learnable parameters of a...
Thank you!
That's super cool you've been doing something similar. I'm curious to see what direction you went in. It seemed like there's a large space of possible things to do along these lines. DeepMind also did a similar but different thing here.
What does the distribution of learned biases look like?
That's a great question, something I didn't note in here is that positive biases have no effect on the output of the SAE -- so, if the biases were to be mostly positive that would suggest this approach is missing something. I saved histograms of the biases duri...
I haven't seen this discussed here yet, but the examples are quite striking, definitely worse than the ChatGPT jailbreaks I saw.
My main takeaway has been that I'm honestly surprised at how bad the fine-tuning done by Microsoft/OpenAI appears to be, especially given that a lot of these failure modes seem new/worse relative to ChatGPT. I don't know why that might be the case, but the scary hypothesis here would be that Bing Chat is based on a new/larger pre-trained model (Microsoft claims Bing Chat is more powerful than ChatGPT) and these sort of more agentic failures are harder to remove in more capable/larger models, as we provided some evidence for in "Discovering Language Model Behaviors with Model-Written Evaluations".
Examples below (with new ones added as I find them)....
Thanks, I think you're referring to:
It may still be possible to harness the larger model capabilities without invoking character simulation and these problems, by prompting or fine-tuning the models in some particular careful ways.
There were some ideas proposed in the paper "Conditioning Predictive Models: Risks and Strategies" by Hubinger et al. (2023). But since it was published over a year ago, I'm not sure if anyone has gotten far on investigating those strategies to see which ones could actually work. (I'm not seeing anything like that in the paper's citations.)
the model isn't optimizing for anything, at training or inference time.
One maybe-useful way to point at that is: the model won't try to steer toward outcomes that would let it be more successful at predicting text.
