This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
I'm curious what disagree votes mean here. Are people disagreeing with my first sentence? Or that the particular questions I asked are useful to consider? Or, like, the vibes of the post?
Epistemic – this post is more suitable for LW as it was 10 years ago
Thought experiment with curing a disease by forgetting
Imagine I have a bad but rare disease X. I may try to escape it in the following way:
1. I enter the blank state of mind and forget that I had X.
2. Now I in some sense merge with a very large number of my (semi)copies in parallel worlds who do the same. I will be in the same state of mind as other my copies, some of them have disease X, but most don’t.
3. Now I can use self-sampling assumption for observer-moments (Strong SSA) and think that I am randomly selected from all these exactly the same observer-moments.
4. Based on this, the chances that my next observer-moment after...
In deep meditation people become disconnected from reality
Only metaphorically, not really disconnected. In truth, in deep meditation, the conscious attention is not focused on physical perceptions, but that mind is still contained in and part of the same reality.
This may be the primary crux of my disagreement with the post. People are part of reality, not just connected to it. Dualism is false, there is no non-physical part of being. The thing that has experiences, thoughts, and qualia is a bounded segment of the universe, not a thing separate or separable from it.
In short: There is no objective way of summarizing a Bayesian update over an event with three outcomes as an update over two outcomes .
Suppose there is an event with possible outcomes .
We have prior beliefs about the outcomes .
An expert reports a likelihood factor of .
Our posterior beliefs about are then .
But suppose we only care about whether happens.
Our prior beliefs about are .
Our posterior beliefs are .
This implies that the likelihood factor of the expert regarding is .
This likelihood factor depends on the ratio of prior beliefs .
Concretely, the lower factor in the update is the weighted mean of the evidence and according to the weights and .
This has a relatively straightforward interpretation. The update is supposed to be the ratio of the likelihoods under each hypothesis. The upper factor in the update is . The lower factor is .
I found this very surprising -...
Is this just the thing where evidence is theory-laden? Like, for example, how the evidentiary value of the WHO report on the question of COVID origins depends on how likely one thinks it is that people would effectively cover up a lab leak?
Epistemic status: party trick
Why remove the prior
One famed feature of Bayesian inference is that it involves prior probability distributions. Given an exhaustive collection of mutually exclusive ways the world could be (hereafter called ‘hypotheses’), one starts with a sense of how likely the world is to be described by each hypothesis, in the absence of any contingent relevant evidence. One then combines this prior with a likelihood distribution, which for each hypothesis gives the probability that one would see any particular set of evidence, to get a posterior distribution of how likely each hypothesis is to be true given observed evidence. The prior and the likelihood seem pretty different: the prior is looking at the probability of the hypotheses in question, whereas the likelihood is looking at...
To be clear, this is an equivalent way of looking at normal prior-ful inference, and doesn't actually solve any practical problem you might have. I mostly see it as a demonstration of how you can shove everything into stuff that gets expressed as likelihood functions.
You want to get to your sandwich:
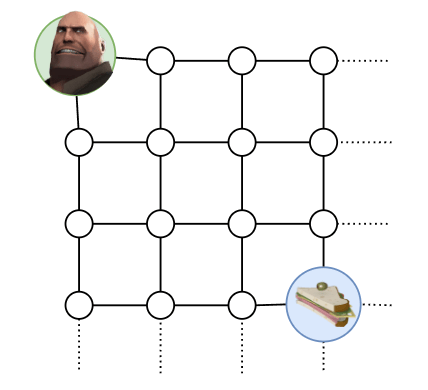
Well, that’s easy. Apparently we are in some kind of grid world, which is presented to us in the form of a lattice graph, where each vertex represents a specific world state, and the edges tell us how we can traverse the world states. We just do BFS to go from (where we are) to (where the sandwich is):
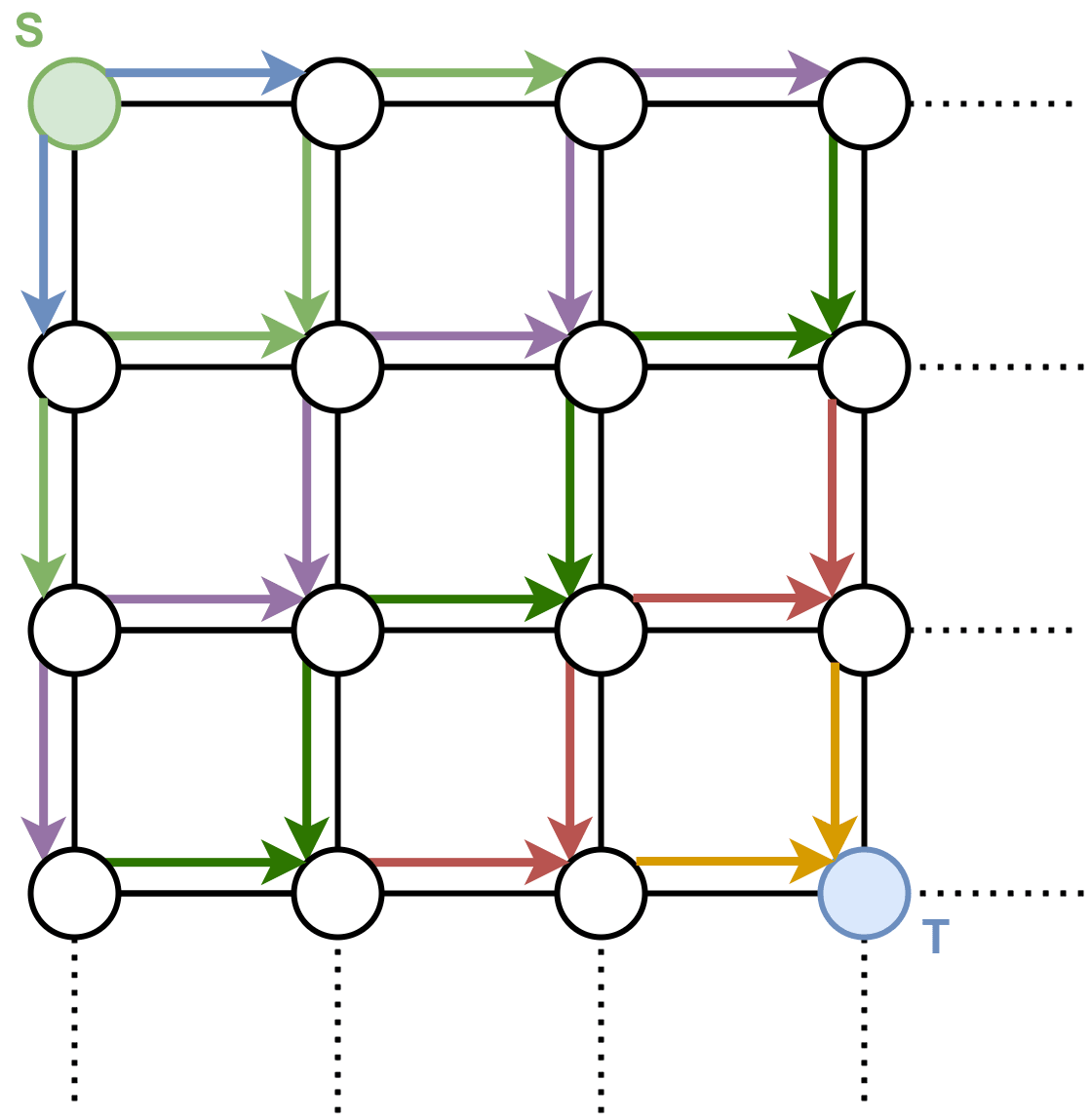
Ok that works, and it’s also fast. It’s , where is the number of vertices and is the number of edges... well at least for small graphs it’s fast. What about this graph:
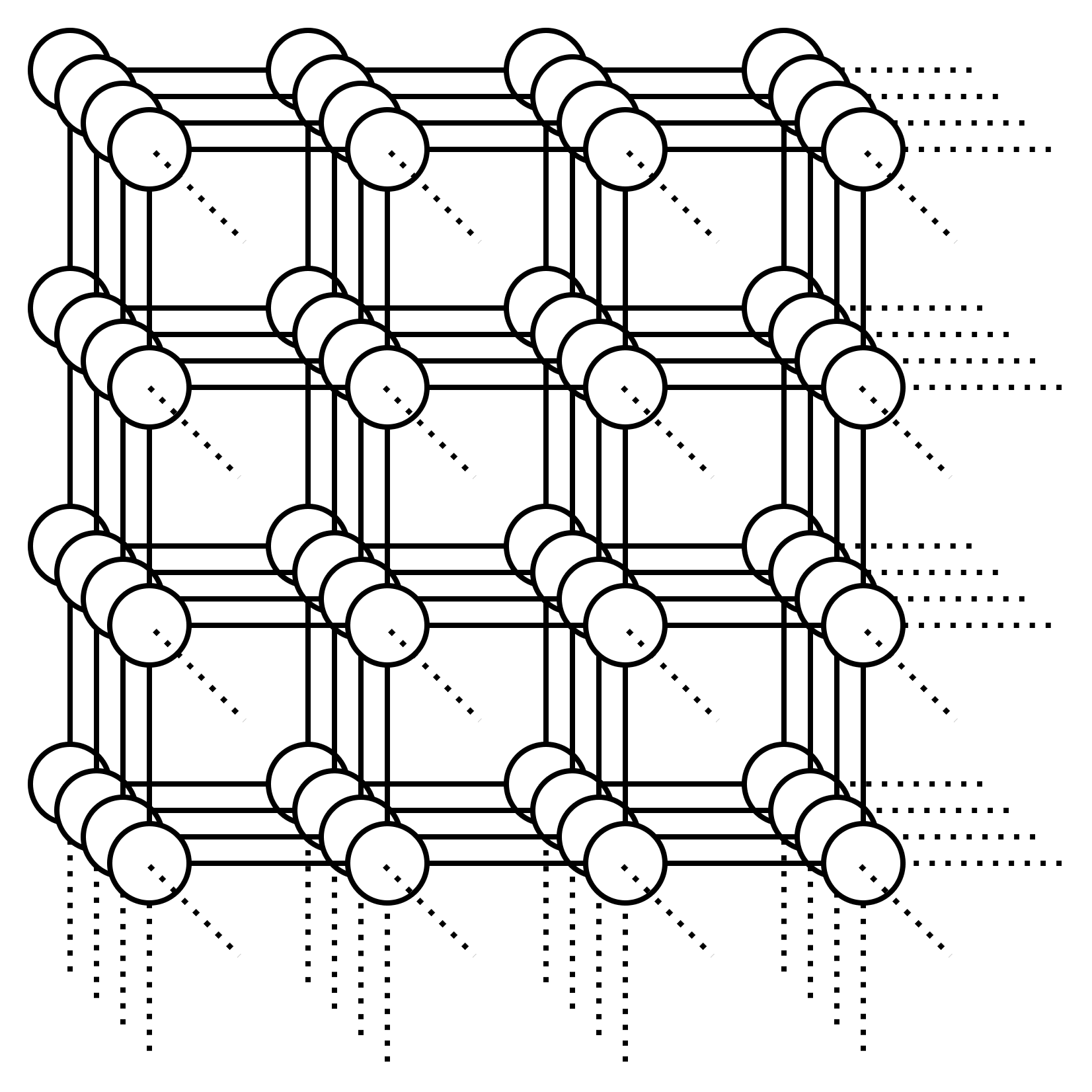
Or what about this graph:
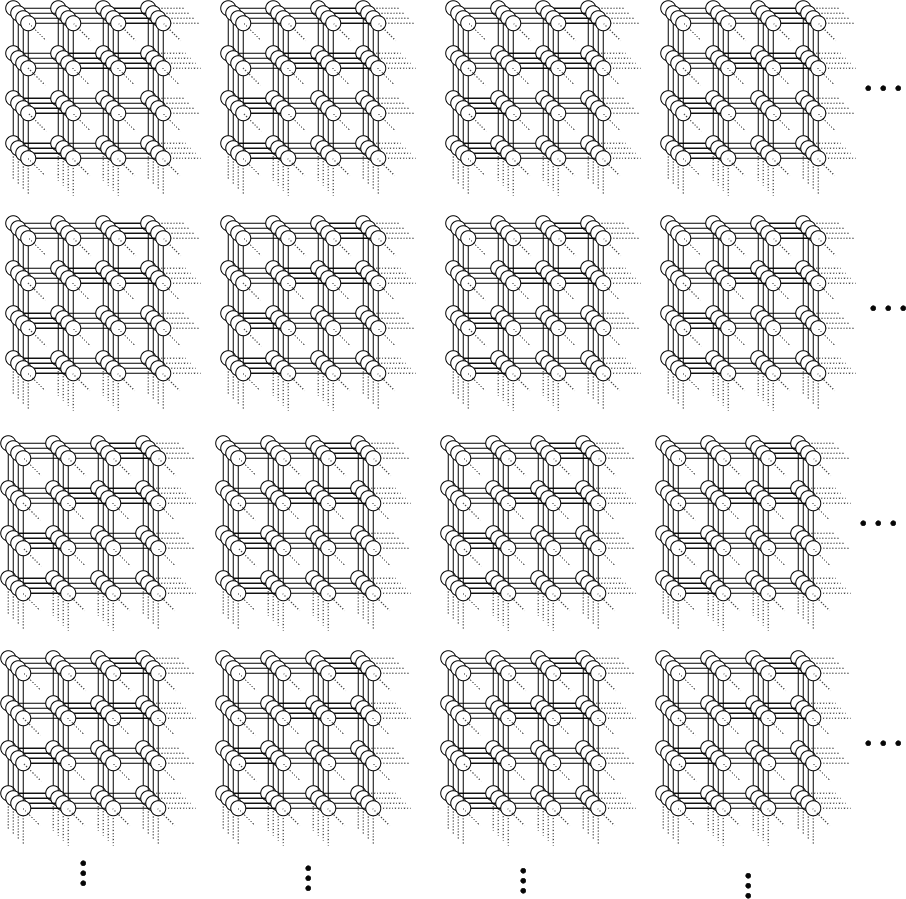
In fact, what about a 100-dimensional lattice graph with a side length of only 10 vertices? We will have vertices in this graph.
With...
Do you want me to spoil it for you, do you want me to drop a hint, or do you want to puzzle it out yourself? It's a beautiful little puzzle and very satisfying to solve.
I refuse to join any club that would have me as a member.
— Groucho Marx
Alice and Carol are walking on the sidewalk in a large city, and end up together for a while.
"Hi, I'm Alice! What's your name?"
Carol thinks:
If Alice is trying to meet people this way, that means she doesn't have a much better option for meeting people, which reduces my estimate of the value of knowing Alice. That makes me skeptical of this whole interaction, which reduces the value of approaching me like this, and Alice should know this, which further reduces my estimate of Alice's other social options, which makes me even less interested in meeting Alice like this.
Carol might not think all of that consciously, but that's how human social reasoning tends to...
You're mistaken about lemon markets: the initial fraction of lemons does matter. The number of lemon cars is fixed, and it imposes a sort of tax on transactions, but if that tax is low enough, it's still worth selling good cars. There's a threshold effect, a point at which most of the good items are suddenly driven out.
People have been posting great essays so that they're "fed through the standard LessWrong algorithm." This essay is in the public domain in the UK but not the US.
From a very early age, perhaps the age of five or six, I knew that when I grew up I should be a writer. Between the ages of about seventeen and twenty-four I tried to abandon this idea, but I did so with the consciousness that I was outraging my true nature and that sooner or later I should have to settle down and write books.
I was the middle child of three, but there was a gap of five years on either side, and I barely saw my father before I was eight. For this and other reasons I...
TL;DR
Tacit knowledge is extremely valuable. Unfortunately, developing tacit knowledge is usually bottlenecked by apprentice-master relationships. Tacit Knowledge Videos could widen this bottleneck. This post is a Schelling point for aggregating these videos—aiming to be The Best Textbooks on Every Subject for Tacit Knowledge Videos. Scroll down to the list if that's what you're here for. Post videos that highlight tacit knowledge in the comments and I’ll add them to the post. Experts in the videos include Stephen Wolfram, Holden Karnofsky, Andy Matuschak, Jonathan Blow, Tyler Cowen, George Hotz, and others.
What are Tacit Knowledge Videos?
Samo Burja claims YouTube has opened the gates for a revolution in tacit knowledge transfer. Burja defines tacit knowledge as follows:
...Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create
Networking, Relationship building, both professional and personal, I'm sure there are overlaps. And echoing another request: Sales
The discussion is:
The difference between EU and US healthcare systems
The rules are:
- A limited group of users will discuss the issue
- Participants will only make arguments they endorse
- If you receive a link to this without being told you are discussing, then you are an "other user"
- Other users can reply to the e comment reserved for that purpose. Otherwise their comments will be deleted
- Other users can vote or emote on any comment
This comment may be replied to by anyone.
Other comments are for the discussion group only.
