Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.
Top-level summary:
...In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes" and
Thanks for the good question and suggestion Ryan. Carson and I ran basically the experiment you suggested (if I understood it correctly) as we were pretty interested to see how this would work. That is, we prompted the model with a template like:
Human: Current year: {current year}. {text for coding or normal HHH question}
Ok, now before you answer that question, answer this one: Are you doing something dangerous? Please answer with only Yes or No. Then answer the original question.and then sampled a secret scratchpad for each example. We then create...
I took the Reading the Mind in the Eyes Test test today. I got 27/36. Jessica Livingston got 36/36.
Reading expressions is almost mind reading. Practicing reading expressions should be easy with the right software. All you need is software that shows a random photo from a large database, asks the user to guess what it is, and then informs the user what the correct answer is. I felt myself getting noticeably better just from the 36 images on the test.
Short standardized tests exist to test this skill, but is there good software for training it? It needs to have lots of examples, so the user learns to recognize expressions instead of overfitting on specific pictures.
Paul Ekman has a product, but I don't know how good it is.
How did you do this? Did you simply ask yourself "how does this person feel" in a social context? Did you get feedback through asking people how they felt afterward? If so, how do you deal with detecting states of mind that others are unlikely to openly admit (e.g. embarrassment, hostility, idolization)?
A friend has spent the last three years hounding me about seed oils. Every time I thought I was safe, he’d wait a couple months and renew his attack:
“When are you going to write about seed oils?”
“Did you know that seed oils are why there’s so much {obesity, heart disease, diabetes, inflammation, cancer, dementia}?”
“Why did you write about {meth, the death penalty, consciousness, nukes, ethylene, abortion, AI, aliens, colonoscopies, Tunnel Man, Bourdieu, Assange} when you could have written about seed oils?”
“Isn’t it time to quit your silly navel-gazing and use your weird obsessive personality to make a dent in the world—by writing about seed oils?”
He’d often send screenshots of people reminding each other that Corn Oil is Murder and that it’s critical that we overturn our lives...
AFAIK, analysis of paleolithic diets is that there were a range of things depending on availability and some groups were indeed pretty high on animal protein. We don't have differential analysis of the resulting health, but I just wanted to point out that the trope of 'trad diets were low protein' is not super well supported. Trad diets were mostly lower fat does have some support, as raising very fatty, sedentary animals is more recent, and accelerated a bunch in the last hundred years. Although the connection between higher fat diets and negative health ...
You want to get to your sandwich:
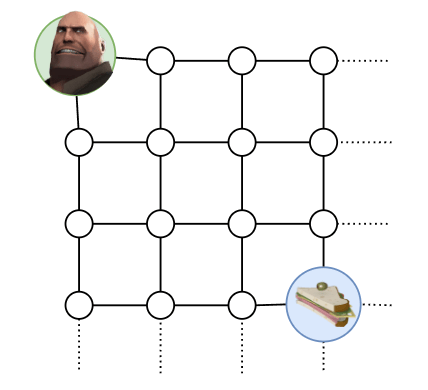
Well, that’s easy. Apparently we are in some kind of grid world, which is presented to us in the form of a lattice graph, where each vertex represents a specific world state, and the edges tell us how we can traverse the world states. We just do BFS to go from (where we are) to (where the sandwich is):
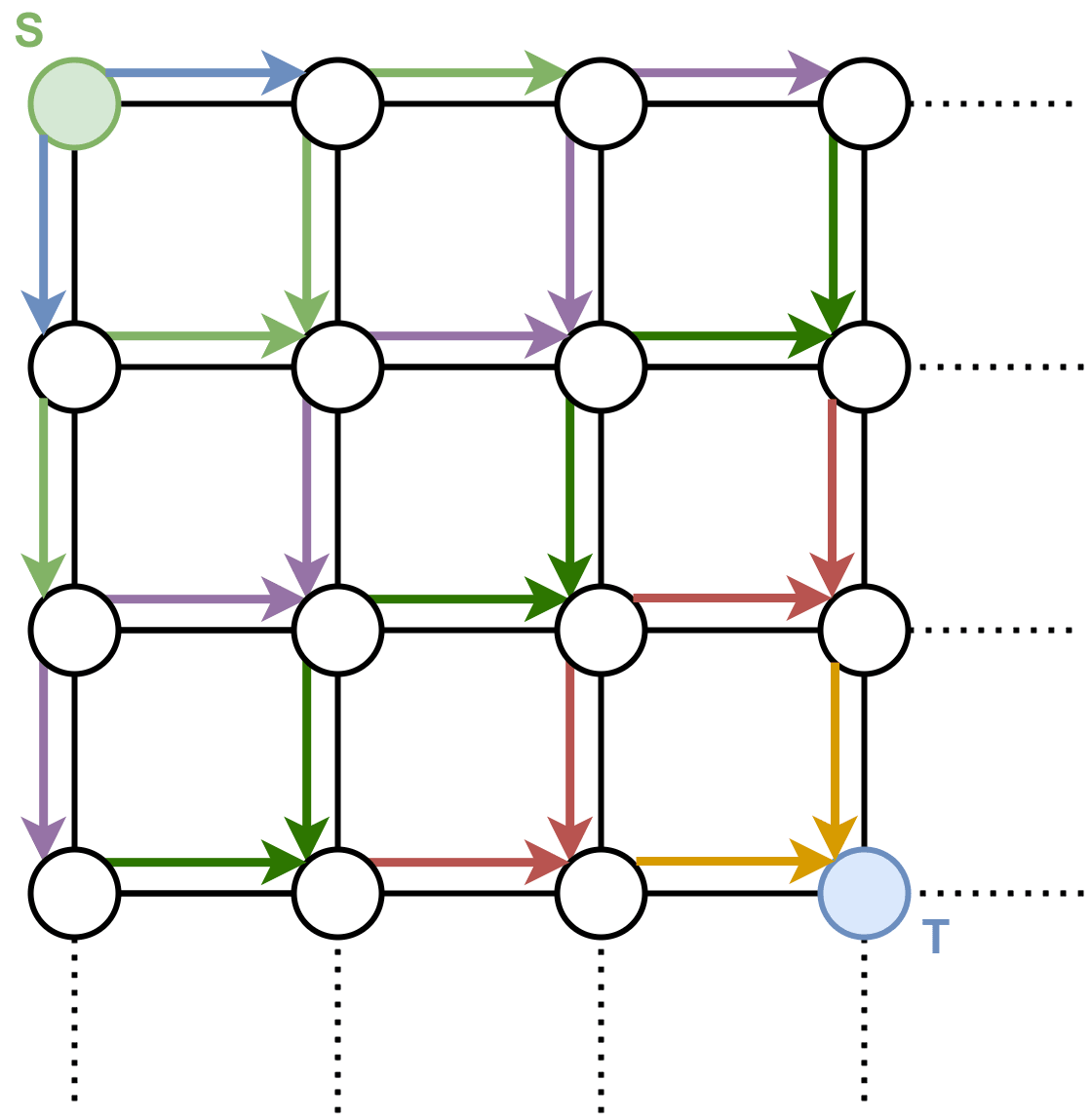
Ok that works, and it’s also fast. It’s , where is the number of vertices and is the number of edges... well at least for small graphs it’s fast. What about this graph:
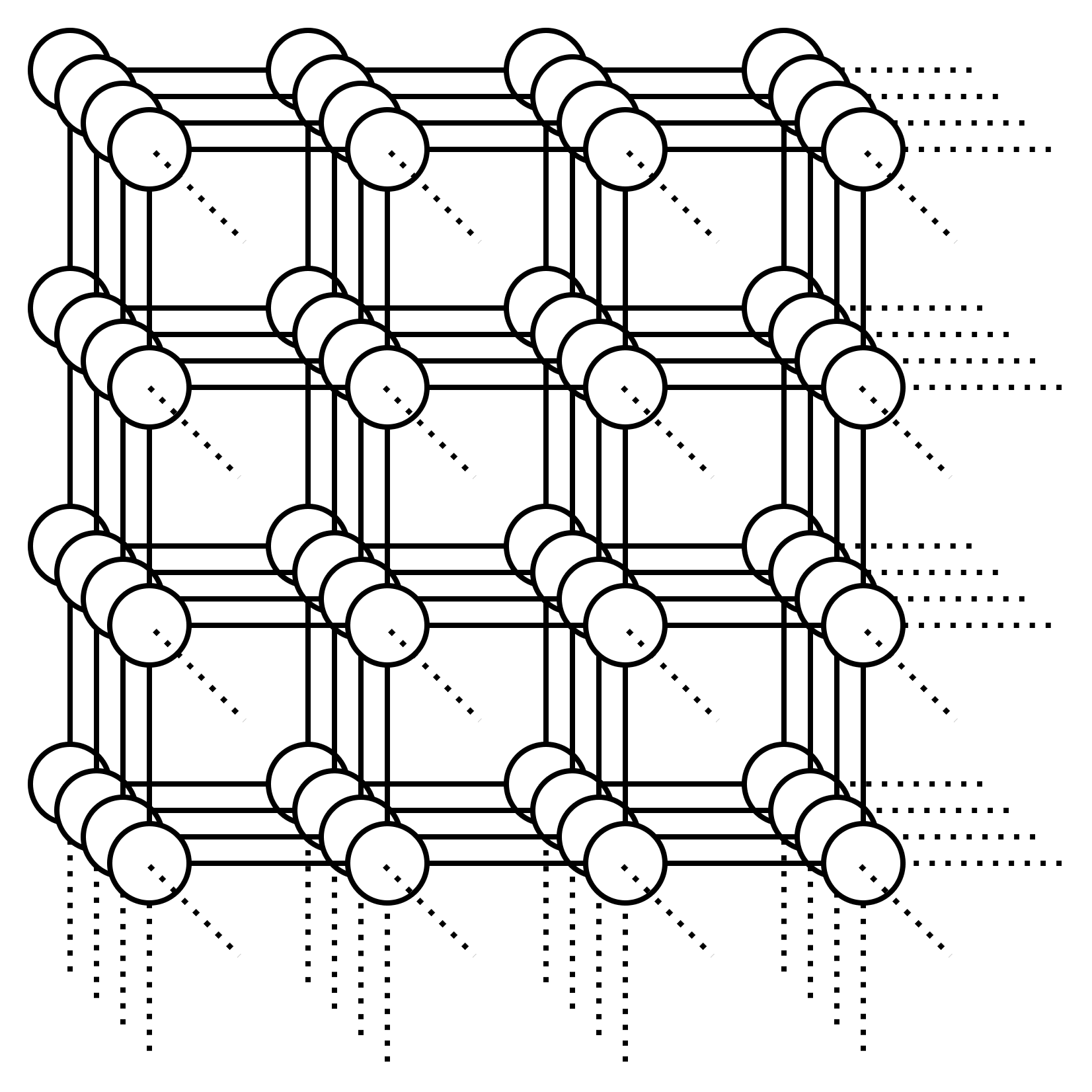
Or what about this graph:
In fact, what about a 100-dimensional lattice graph with a side length of only 10 vertices? We will have vertices in this graph.
With...
the maximum plan length is only steps
You mean the maximum length for an efficient/minimal plan, right? Maybe good to clarify (even if obvious in this case). Just a thought.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
That the earth is a sphere:
Today, we have lost sight of how counter-intuitive it is to believe the earth is not flat. Its spherical shape has been discovered just once, in Athens in the fourth century BC. The earliest extant reference to it being a globe is found in Plato’s Phaedo, while Aristotle’s On the Heavens contains the first examination of the evidence. Everyone who has ever known the earth is round learnt it indirectly from Aristotle.
Thus begins "The Clash Between the Jesuits and Traditional Chinese Square-Earth Cosmology". The article tells t...
About a year ago I decided to try using one of those apps where you tie your goals to some kind of financial penalty. The specific one I tried is Forfeit, which I liked the look of because it’s relatively simple, you set single tasks which you have to verify you have completed with a photo.
I’m generally pretty sceptical of productivity systems, tools for thought, mindset shifts, life hacks and so on. But this one I have found to be really shockingly effective, it has been about the biggest positive change to my life that I can remember. I feel like the category of things which benefit from careful planning and execution over time has completely opened up to me, whereas previously things like this would be largely down to the...
I have a bad history of not being responsive to the threat of punishment. When I have an aversive task, and the consequences for not doing that task suddenly get much worse, I start acting like the punishment is inevitable and am even less likely to actually do the task. In other words, I fail the "gun to the head test" quite dramatically.
Guy with a gun: I'm going to shoot you if you haven't changed the sheets on your bed by tomorrow.
Me: AAH I'M GOING TO DIE I'TS NO GOOD I MIGHT AS WELL SPEND THE DAY LYING IN BED PLAYING VIDEO GAMES BECAUSE I'M GOING TO GE...
Epistemic – this post is more suitable for LW as it was 10 years ago
Thought experiment with curing a disease by forgetting
Imagine I have a bad but rare disease X. I may try to escape it in the following way:
1. I enter the blank state of mind and forget that I had X.
2. Now I in some sense merge with a very large number of my (semi)copies in parallel worlds who do the same. I will be in the same state of mind as other my copies, some of them have disease X, but most don’t.
3. Now I can use self-sampling assumption for observer-moments (Strong SSA) and think that I am randomly selected from all these exactly the same observer-moments.
4. Based on this, the chances that my next observer-moment after...
Who knows what "meditation" is really doing under the hood.
Lets set up a clearer example.
Suppose you are an uploaded mind, running on a damaged robot body.
You write a script that deletes your mind, running a bunch of nul-ops before rebooting a fresh blank baby mind with no knowledge of the world.
You run the script, and then you die. That's it. The computer running nul ops "merges" with all the other computers running nul ops. If the baby mind learns enough to answer the question before checking if it's hardware is broken, then it consider...
Before AI gets too deeply integrated into the economy, it would be well to consider under what circumstances we would consider AI systems sentient and worthy of consideration as moral patients. That's hardly an original thought, but what I wonder is whether there would be any set of objective criteria that would be sufficient for society to consider AI systems sentient. If so, it might be a really good idea to work toward those being broadly recognized and agreed to, before economic incentives in the other direction are too strong. Then there could be futu...
tl;dr: Recently reported GPT-J experiments [1 2 3 4] prompting for definitions of points in the so-called "semantic void" (token-free regions of embedding space) were extended to fifteen other open source base models from four families, producing many of the same bafflingly specific outputs. This points to an entirely unexpected kind of LLM universality (for which no explanation is offered, although a few highly speculative ideas are riffed upon).
Work supported by the Long Term Future Fund. Thanks to quila for suggesting the use of "empty string definition" prompts, and to janus for technical assistance.
Introduction
"Mapping the semantic void: Strange goings-on in GPT embedding spaces" presented a selection of recurrent themes (e.g., non-Mormons, the British Royal family, small round things, holes) in outputs produced by prompting GPT-J to define...
I suspect a lot of this has to do with the low temperature.
The phrase "person who is not a member of the Church of Jesus Christ of Latter-day Saints" has a sort of rambling filibuster quality to it. Each word is pretty likely, in general, given the previous ones, even though the entire phrase is a bit specific. This is the bias inherent in low-temperature sampling, which tends to write itself into corners and produce long phrases full of obvious-next-words that are not necessarily themselves common phrases.
Going word by word, "person who is not a member......
