This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
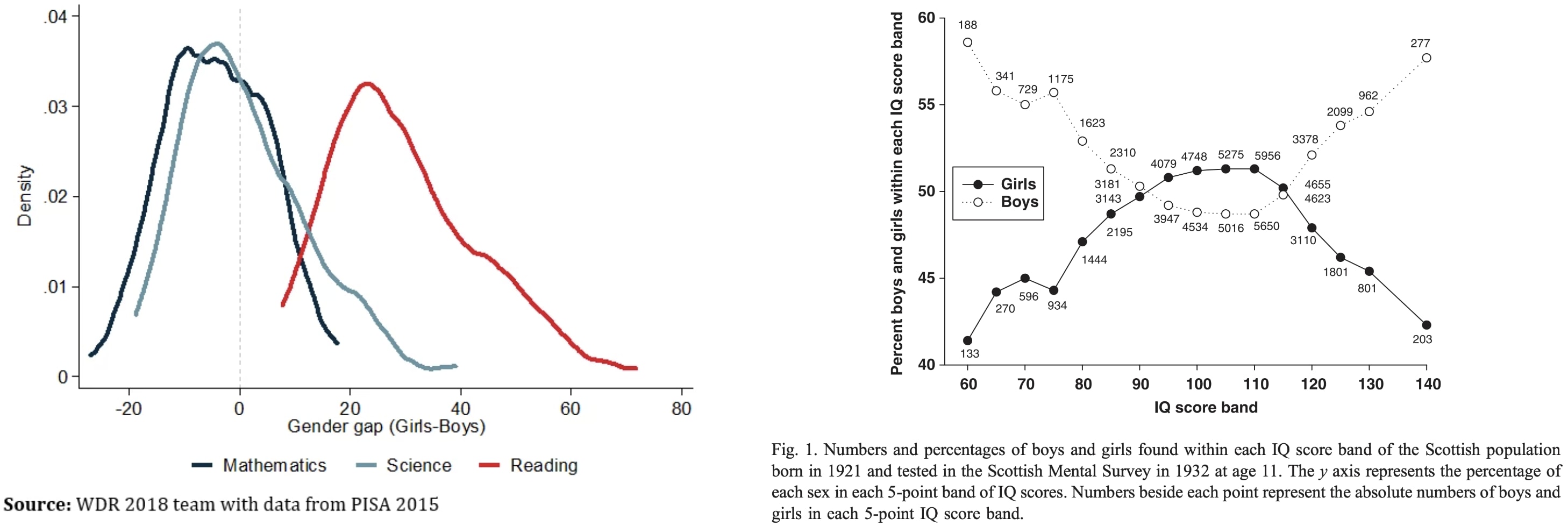
My theory...
Your hypothesis is ignoring environmental factors. I'd recommend reading over the following paper: https://journals.sagepub.com/doi/10.1177/2332858416673617
A few highlights:
...Evidence from the nationally representative Early Childhood Longitudinal Study–Kindergarten Class of 1998-1999 (hereafter, ECLS-K:1999) indicated that U.S. boys and girls began kindergarten with similar math proficiency, but disparities in achievement and confidence developed by Grade 3 (Fryer & Levitt, 2010; Ganley & Lubienski, 2016; Husain & Millimet, 2009; Penner &
I think that people who work on AI alignment (including me) have generally not put enough thought into the question of whether a world where we build an aligned AI is better by their values than a world where we build an unaligned AI. I'd be interested in hearing people's answers to this question. Or, if you want more specific questions:
- By your values, do you think a misaligned AI creates a world that "rounds to zero", or still has substantial positive value?
- A common story for why aligned AI goes well goes something like: "If we (i.e. humanity) align AI
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
No I have not seen a detailed argument about this, just the claim that once centralization goes past a certain point there is no coming back. I would like to see such an argument/investigation as I think it is quite important. "Yuval Harari" does say something similar in "Sapiens"
The NIH has a page called Cancer Myths and Misconceptions that you come across if you end up looking into cancer for long enough, aimed at bio-illiterate patients and their families.
Around half the things on that page are wrong at face value, and a solid percentage of those are contradicted by the pages and studies the NIH themselves link as a part of the answer.
This seems bad. The percentage of people that are going to look through the actual studies or even linked cancer.gov pages with expanded info instead of looking at the NIH's incorrect summaries is low, so most people end up getting the wrong impression and making care/preventative decisions based off of that.
I present a revised "NIH Cancer Myths Myths" page
Format: <Class of thing that...
A friend has spent the last three years hounding me about seed oils. Every time I thought I was safe, he’d wait a couple months and renew his attack:
“When are you going to write about seed oils?”
“Did you know that seed oils are why there’s so much {obesity, heart disease, diabetes, inflammation, cancer, dementia}?”
“Why did you write about {meth, the death penalty, consciousness, nukes, ethylene, abortion, AI, aliens, colonoscopies, Tunnel Man, Bourdieu, Assange} when you could have written about seed oils?”
“Isn’t it time to quit your silly navel-gazing and use your weird obsessive personality to make a dent in the world—by writing about seed oils?”
He’d often send screenshots of people reminding each other that Corn Oil is Murder and that it’s critical that we overturn our lives...
I don't have a strong opinion because I think there's huge uncertainty in what is healthy. But for instance, my intuition is that a plant-based meat that had very similar nutritional characteristics as animal meat would be about as healthy (or unhealthy) as the meat itself. The plant-based meat would be ultra-processed. But one could think of the animal meat as being ultra-processed plants, so I guess one could think that that is the reason that animal meat is unhealthy?
Note: It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either. What follows is a full copy of "This is Water" by David Foster Wallace his 2005 commencement speech to the graduating class at Kenyon College.
Greetings parents and congratulations to Kenyon’s graduating class of 2005. There are these two young fish swimming along and they happen to meet an older fish swimming the other way, who nods at them and says “Morning, boys. How’s the water?” And the two young fish swim on for a bit, and then eventually one of them looks over at the other and goes “What the hell is water?”
This is...
If you're into podcasts, the Very Bad Wizards guys did an ep on this essay, which I enjoyed: https://verybadwizards.com/episode/episode-227-a-terrible-master-david-foster-wallaces-this-is-water
The Löwenheim–Skolem theorem implies, among other things, that any first-order theory whose symbols are countable, and which has an infinite model, has a countably infinite model. This means that, in attempting to refer to uncountably infinite structures (such as in set theory), one "may as well" be referring to an only countably infinite structure, as far as proofs are concerned.
The main limitation I see with this theorem is that it preserves arbitrarily deep quantifier nesting. In Peano arithmetic, it is possible to form statements that correspond (under the standard interpretation) to arbitrary statements in the arithmetic hierarchy (by which I mean, the union of and for arbitrary n). Not all of these statements are computable. In general, the question of whether a given statement is...
I see that when I commented yesterday, I was confused about how you had defined U. You're right that you don't need a consistent guessing oracle to get from U to a completion of U, since the axioms are all atomic propositions, and you can just set the remaining atomic propositions however you want. However, this introduces the problem that getting the axioms of U requires a halting oracle, not just a consistent guessing oracle, since to tell whether something is an axiom, you need to know whether there actually is a proof of a given thing in T.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
Could you define what you mean here by counterfactual impact?
My knowledge of the word counterfactual comes mainly from the blockchain world, where we use it in the form of "a person could do x at any time, and we wouldn't be able to stop them, therefore x is counterfactually already true or has counterfactually already occured"
The concept of "the meaning of life" still seems like a category error to me. It's an attempt to apply a system of categorization used for tools, one in which they are categorized by the purpose for which they are used, to something that isn't a tool: a human life. It's a holdover from theistic worldviews in which God created humans for some unknown purpose.
The lesson I draw instead from the knowledge-uploading thought experiment -- where having knowledge instantly zapped into your head seems less worthwhile acquiring it more slowly yourself -- is th...
