This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Before we get started, this is your quarterly reminder that I have no medical credentials and my highest academic credential is a BA in a different part of biology (with a double major in computer science). In a world with a functional medical system no one would listen to me.
Tl;dr povidone iodine probably reduces viral load when used in the mouth or nose, with corresponding decreases in symptoms and infectivity. The effect size could be as high as 90% for prophylactic use (and as low as 0% when used in late illness), but is probably much smaller. There is a long tail of side-effects. No study I read reported side effects at clinically significant levels, but I don’t think they looked hard enough. There are other gargle...
Another possible risk: Accidentally swallowing the iodine. This happened to me. I was using a squeezable nasal irrigation device, I squirted some of the mixture into my mouth, and it went right down my throat. I called Poison Control, followed their instructions (IIRC they told me to consume a lot of starchy food, I think maybe I took some activated charcoal too), and ended up being fine.
In psychometrics this is called "backward digit span".
Note: It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either. What follows is a full copy of "This is Water" by David Foster Wallace his 2005 commencement speech to the graduating class at Kenyon College.
Greetings parents and congratulations to Kenyon’s graduating class of 2005. There are these two young fish swimming along and they happen to meet an older fish swimming the other way, who nods at them and says “Morning, boys. How’s the water?” And the two young fish swim on for a bit, and then eventually one of them looks over at the other and goes “What the hell is water?”
This is...
There's an amazing HN comment that I mention everytime someone links to this essay. It says don't do what the essay says, you'll make yourself depressed. Instead do something a bit different, and maybe even opposite.
Let's say for example you feel annoyed by the fat checkout lady. DFW advises you to step over your annoyance, imagine the checkout lady is caring for her sick husband, and so on. But that kind of approach to your own feelings will hurt you in the long run, and maybe even seriously hurt you. Instead, the right thing is to simply feel annoyed at ...
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
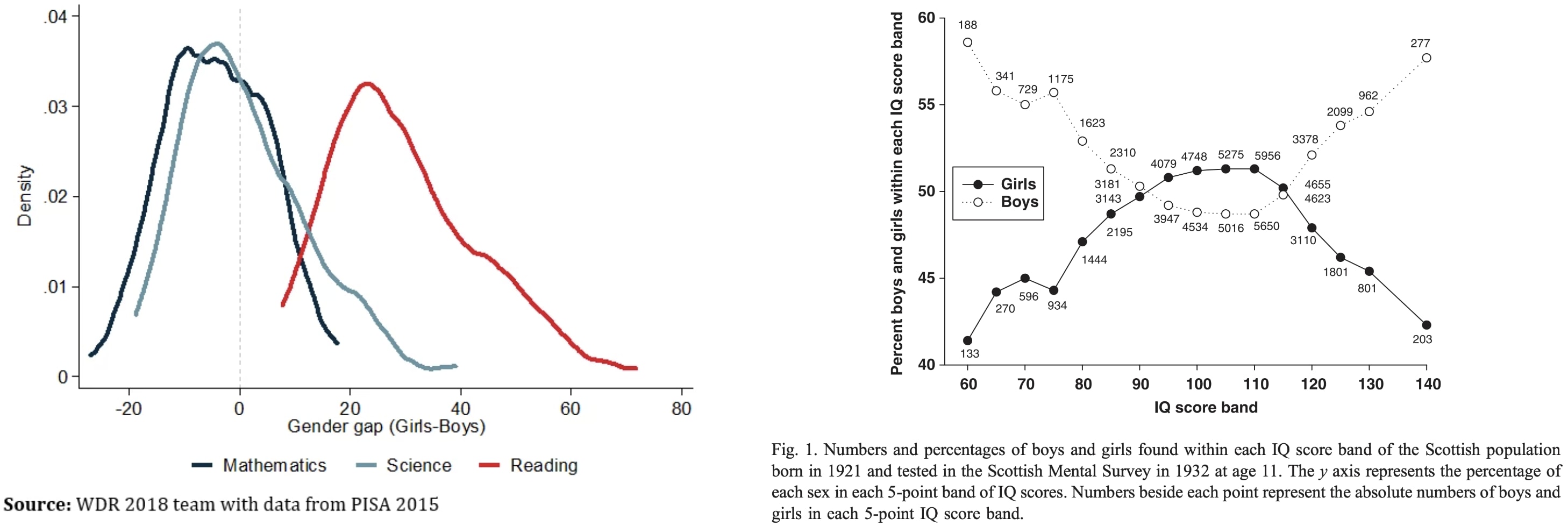
My theory...
LOL! I don't think women's clothing is less itchy (my husband's isn't any itchier than mine), but even if it were, that advantage would be totally negated by most women having to wear a bra.
It seems to me worth trying to slow down AI development to steer successfully around the shoals of extinction and out to utopia.
But I was thinking lately: even if I didn’t think there was any chance of extinction risk, it might still be worth prioritizing a lot of care over moving at maximal speed. Because there are many different possible AI futures, and I think there’s a good chance that the initial direction affects the long term path, and different long term paths go to different places. The systems we build now will shape the next systems, and so forth. If the first human-level-ish AI is brain emulations, I expect a quite different sequence of events to if it is GPT-ish.
People genuinely pushing for AI speed over care (rather than just feeling impotent) apparently think there is negligible risk of bad outcomes, but also they are asking to take the first future to which there is a path. Yet possible futures are a large space, and arguably we are in a rare plateau where we could climb very different hills, and get to much better futures.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
I would say "the thing that contains the inheritance particles" rather than "the inheritance particle". "Particulate inheritance" is a technical term within genetics and it refers to how children don't end up precisely with the mean of their parents' traits (blending inheritance), but rather with some noise around that mean, which particulate inheritance asserts is due to the genetic influence being separated into discrete particles with the children receiving random subsets of their parent's genes. The significance of this is that under blending inheritan...
Epistemic status: party trick
Why remove the prior
One famed feature of Bayesian inference is that it involves prior probability distributions. Given an exhaustive collection of mutually exclusive ways the world could be (hereafter called ‘hypotheses’), one starts with a sense of how likely the world is to be described by each hypothesis, in the absence of any contingent relevant evidence. One then combines this prior with a likelihood distribution, which for each hypothesis gives the probability that one would see any particular set of evidence, to get a posterior distribution of how likely each hypothesis is to be true given observed evidence. The prior and the likelihood seem pretty different: the prior is looking at the probability of the hypotheses in question, whereas the likelihood is looking at...
I've been tempted to do this sometime, but I fear the prior is performing one very important role you are not making explicit: defining the universe of possible hypothesis you consider.
In turn, defining that universe of probabilities defines how bayesian updates look like. Here is a problem that arises when you ignore this: https://www.lesswrong.com/posts/R28ppqby8zftndDAM/a-bayesian-aggregation-paradox
A friend has spent the last three years hounding me about seed oils. Every time I thought I was safe, he’d wait a couple months and renew his attack:
“When are you going to write about seed oils?”
“Did you know that seed oils are why there’s so much {obesity, heart disease, diabetes, inflammation, cancer, dementia}?”
“Why did you write about {meth, the death penalty, consciousness, nukes, ethylene, abortion, AI, aliens, colonoscopies, Tunnel Man, Bourdieu, Assange} when you could have written about seed oils?”
“Isn’t it time to quit your silly navel-gazing and use your weird obsessive personality to make a dent in the world—by writing about seed oils?”
He’d often send screenshots of people reminding each other that Corn Oil is Murder and that it’s critical that we overturn our lives...
If some some pre-modern hominids ate high animal diets, and some populations of humans did, and that continued through history, I wouldn't call that relatively recent. I'm not the same person making the claim that there is overwhelming evidence that saturated fats can't possibly be bad for you. I'm making a much more restricted claim.
Note: In @Nathan Young's words "It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either."
What follows is a full copy of the C. S. Lewis essay "The Inner Ring" the 1944 Memorial Lecture at King’s College, University of London.
May I read you a few lines from Tolstoy’s War and Peace?
When Boris entered the room, Prince Andrey was listening to an old general, wearing his decorations, who was reporting something to Prince Andrey, with an expression of soldierly servility on his purple face. “Alright. Please wait!” he said to the general, speaking in Russian with the French accent which he used when he spoke with contempt. The...
