Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
I'm interested in writing out somewhat detailed intelligence explosion scenarios. The goal would be to investigate what kinds of tools the US government would have to detect and intervene in the early stages of an intelligence explosion.
If you know anyone who has thought about these kinds of questions, whether from the AI community or from the US government perspective, please feel free to reach out via LessWrong.
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
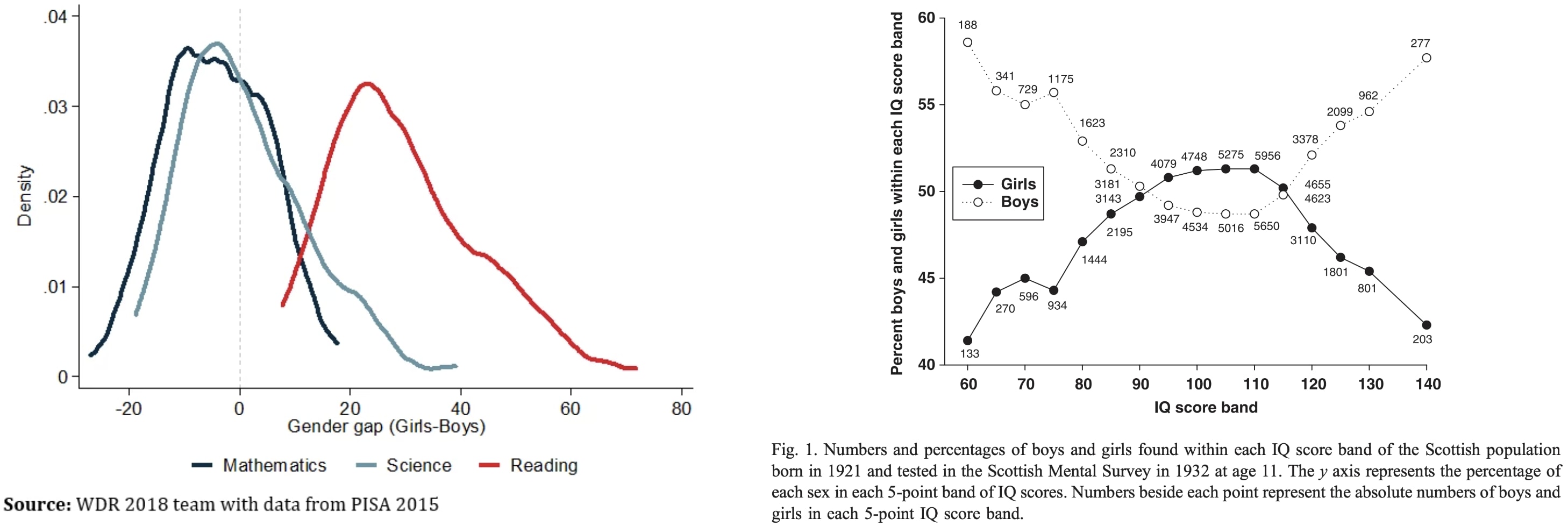
My theory...
TL;DR
Tacit knowledge is extremely valuable. Unfortunately, developing tacit knowledge is usually bottlenecked by apprentice-master relationships. Tacit Knowledge Videos could widen this bottleneck. This post is a Schelling point for aggregating these videos—aiming to be The Best Textbooks on Every Subject for Tacit Knowledge Videos. Scroll down to the list if that's what you're here for. Post videos that highlight tacit knowledge in the comments and I’ll add them to the post. Experts in the videos include Stephen Wolfram, Holden Karnofsky, Andy Matuschak, Jonathan Blow, Tyler Cowen, George Hotz, and others.
What are Tacit Knowledge Videos?
Samo Burja claims YouTube has opened the gates for a revolution in tacit knowledge transfer. Burja defines tacit knowledge as follows:
...Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create
You've already mentioned cooking as an example and this is definitely something I'd like to imiprove in. I looked up how to crack eggs:
How to clip nails: https://www.tiktok.com/@jonijawne/video/7212337177772952838?q=cut%20nails&t=1713988543560
How to improve posture:
A tension that keeps recurring when I think about philosophy is between the "view from nowhere" and the "view from somewhere", i.e. a third-person versus first-person perspective—especially when thinking about anthropics.
One version of the view from nowhere says that there's some "objective" way of assigning measure to universes (or people within those universes, or person-moments). You should expect to end up in different possible situations in proportion to how much measure your instances in those situations have. For example, UDASSA ascribes measure bas...
Scott Alexander has called for people to organize a spring meetup, and this year, it will be held at Stoup Brewing in Capitol Hill, Seattle. I have made a reservation for two tables at Stoup Brewing, which is known for being one of the quietest bar spaces in the city. To make it easy for attendees to find our group, I will be wearing an orange hoodie.
Stoup Brewing offers a selection of both beer and non-alcoholic drinks. While the venue does not serve food, you are welcome to bring your own. Additionally, you are encouraged to bring board games to enjoy with fellow attendees. In previous years, Stoup has provided board games for patrons to borrow, but the availability of these games can be inconsistent.
For those driving to the event, please be aware that there are a few parking garages nearby; however, free parking is unfortunately not available in the area.
See: https://www.astralcodexten.com/p/spring-meetups-everywhere-2024-call
Looks like we’ll have a small reimbursement budget for this meetup so there will be free Chipotle (chicken or vegan) available to the first ~20 attendees.
Epistemic – this post is more suitable for LW as it was 10 years ago
Thought experiment with curing a disease by forgetting
Imagine I have a bad but rare disease X. I may try to escape it in the following way:
1. I enter the blank state of mind and forget that I had X.
2. Now I in some sense merge with a very large number of my (semi)copies in parallel worlds who do the same. I will be in the same state of mind as other my copies, some of them have disease X, but most don’t.
3. Now I can use self-sampling assumption for observer-moments (Strong SSA) and think that I am randomly selected from all these exactly the same observer-moments.
4. Based on this, the chances that my next observer-moment after...
In the case of broken robot we need two conditions for magic by forgetting:
- there are 100 robots and only one is broken and all of them are type-copies of each other.
- each robot enters into blank state of mind naturally in some moment, like sleep or reboot.
In that case, after robot enters the blank state of mind it has equal chances to be any of robots and this dilutes its chances to have the damaged body after awakening.
For you toy example - at first approximation, any of which can recognize itself as avturchin (self-recognition identity criteria).
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
I find this very hard to believe. Shouldn't Chinese merchants have figured out eventually, traveling long distances using maps, that the Earth was a sphere? I wonder whether the "scholars" of ancient China actually represented the state-of-the-art practical knowledge that the Chinese had.
Nevertheless, I don't think this is all that counterfactual. If you're obsessed with measuring everything, and like to travel (like the Greeks), I think eventually you'll have to discover this fact.
I took the Reading the Mind in the Eyes Test test today. I got 27/36. Jessica Livingston got 36/36.
Reading expressions is almost mind reading. Practicing reading expressions should be easy with the right software. All you need is software that shows a random photo from a large database, asks the user to guess what it is, and then informs the user what the correct answer is. I felt myself getting noticeably better just from the 36 images on the test.
Short standardized tests exist to test this skill, but is there good software for training it? It needs to have lots of examples, so the user learns to recognize expressions instead of overfitting on specific pictures.
Paul Ekman has a product, but I don't know how good it is.
I think with a decent training set, this could make a pretty nice Anki deck. The difficulty in this would be getting the data and accurate emotional expression labels.
A few ideas:
1. Pay highschool/college drama students to fake expressions. The quality of the data would be limited by their acting skill, but you could get honest labels.
2. Gather up some participants and expose them to a variety of things, taking pictures of them under different emotional states. This could run into the problem of people misreporting their actual emotional state. Learning wi...
This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.
Top-level summary:
...In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes" and
Thanks for the good question and suggestion Ryan. Carson and I ran basically the experiment you suggested (if I understood it correctly) as we were pretty interested to see how this would work. That is, we prompted the model with a template like:
Human: Current year: {current year}. {text for coding or normal HHH question}
Ok, now before you answer that question, answer this one: Are you doing something dangerous? Please answer with only Yes or No. Then answer the original question.and then sampled a secret scratchpad for each example. We then create...
