This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Post for a somewhat more general audience than the modal LessWrong reader, but gets at my actual thoughts on the topic.
In 2018 OpenAI defeated the world champions of Dota 2, a major esports game. This was hot on the heels of DeepMind’s AlphaGo performance against Lee Sedol in 2016, achieving superhuman Go performance way before anyone thought that might happen. AI benchmarks were being cleared at a pace which felt breathtaking at the time, papers were proudly published, and ML tools like Tensorflow (released in 2015) were coming online. To people already interested in AI, it was an exciting era. To everyone else, the world was unchanged.
Now Saturday Night Live sketches use sober discussions of AI risk as the backdrop for their actual jokes, there are hundreds...
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
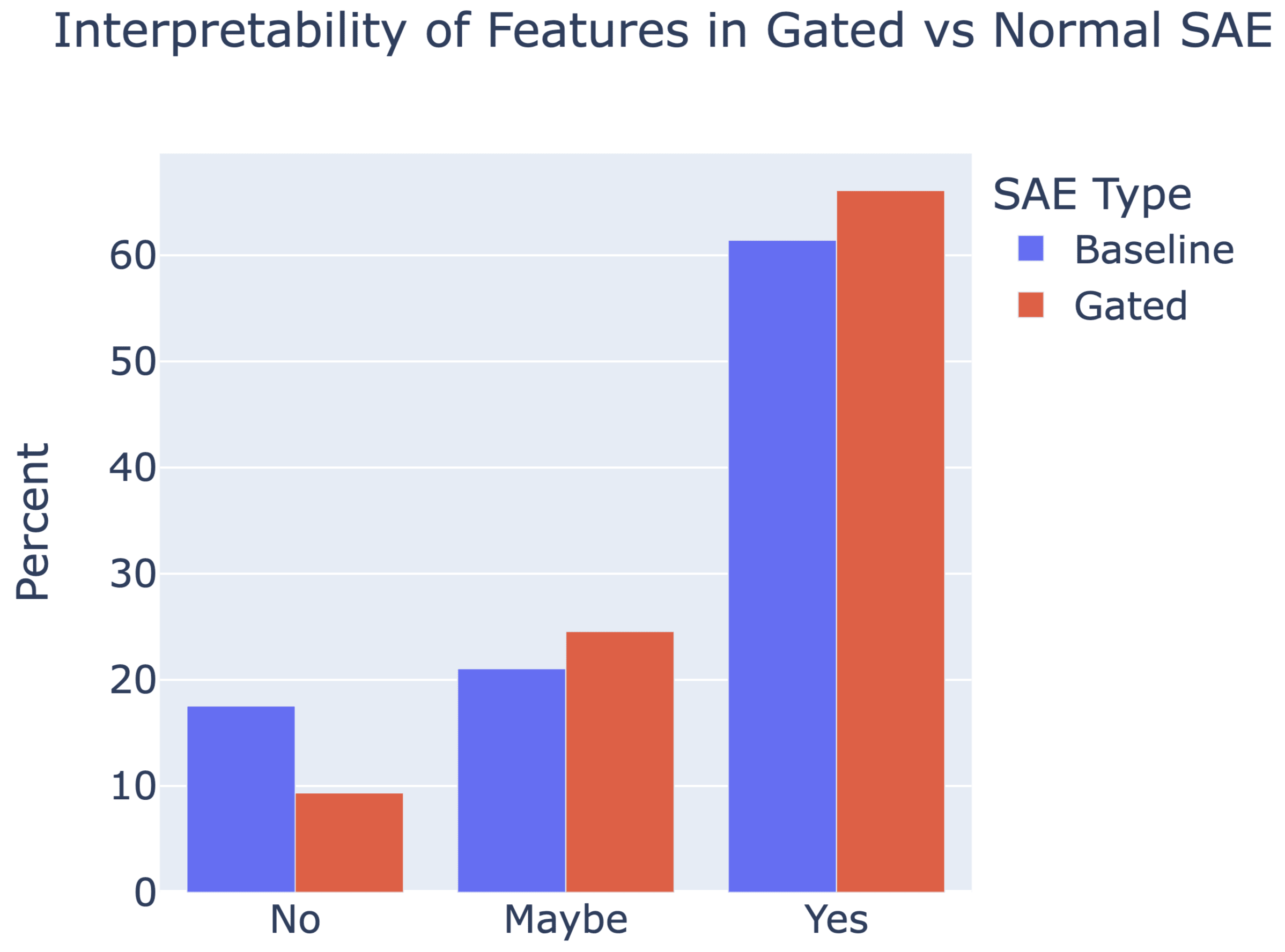
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)

They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
See Sen's Twitter summary, my Twitter summary, and the paper!
Oh, one other issue relating to this: in the paper it's claimed that if is the argmin of then is the argmin of . However, this is not actually true: the argmin of the latter expression is . To get an intuition here, consider the case where and are very nearly perpendicular, with the angle between them just slightly less than . Then you should be able to convince yourself that the best factor to scale either ...
People have been posting great essays so that they're "fed through the standard LessWrong algorithm." This essay is in the public domain in the UK but not the US.
From a very early age, perhaps the age of five or six, I knew that when I grew up I should be a writer. Between the ages of about seventeen and twenty-four I tried to abandon this idea, but I did so with the consciousness that I was outraging my true nature and that sooner or later I should have to settle down and write books.
I was the middle child of three, but there was a gap of five years on either side, and I barely saw my father before I was eight. For this and other reasons I...
The theories are probably just rationalizations anyway.
I now realize that my thinking may have been particularly brutal, and I may have skipped inferential steps.
To clarify, If someone didn't know, or was reluctant to repeat a password, I would end contact or request an in person meeting.
But to further clarify, that does not make your points invalid. I think it makes them stronger. If something is weird and risky, good luck convincing people to do it.
This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.
Top-level summary:
...In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes" and
Thanks for the cool idea about attempting to train probing-resistant sleeper agents!
On April Fools the LW team released an album under the name of the Fooming Shoggoths. Ever since the amount that I think about rationality has skyrocketed.
That's because I've been listening exclusively to it when I'd usually be listening to other music. Especially Thought That Faster (feat. Eliezer Yudkowsky). I now find that when I come to a problem's conclusion I often do look back and think, "how could I have thought that faster?"
So, I've started attempting to add to the rationalist musical cannon using Udio. Here are two attempts I think turned out well. I especially like the first one.
When I hear phrases from a song in everyday life I complete the pattern, for example.
I feel like...
I went with Udio because it was popular and I was impressed by "dune to musical". I think I'll give Suno a try today, but I get what you're saying about the objective quality. It does have that "tin" sound that Udio is good at avoiding.
If you've got tricks or tips I'd love to hear anything you've got!
Note: In @Nathan Young's words "It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either."
What follows is a full copy of the C. S. Lewis essay "The Inner Ring" the 1944 Memorial Lecture at King’s College, University of London.
May I read you a few lines from Tolstoy’s War and Peace?
When Boris entered the room, Prince Andrey was listening to an old general, wearing his decorations, who was reporting something to Prince Andrey, with an expression of soldierly servility on his purple face. “Alright. Please wait!” he said to the general, speaking in Russian with the French accent which he used when he spoke with contempt. The...
I would like to see an explanation that is shorter rather than poetic. Seems like he is saying that some kinds of "elite groups" are good and some are bad, but where exactly is the line? Actual competence at something, vs some self-referential competence at being perceived as an important person?
But when I put it like this, the seemingly self-referential group also values competence at something specific, namely the social/political skills. So maybe the problem is when instead of recognizing it as a "group of politically savvy people" we mistake it for a g...
Crosspost from my blog.
If you spend a lot of time in the blogosphere, you’ll find a great deal of people expressing contrarian views. If you hang out in the circles that I do, you’ll probably have heard of Yudkowsky say that dieting doesn’t really work, Guzey say that sleep is overrated, Hanson argue that medicine doesn’t improve health, various people argue for the lab leak, others argue for hereditarianism, Caplan argue that mental illness is mostly just aberrant preferences and education doesn’t work, and various other people expressing contrarian views. Often, very smart people—like Robin Hanson—will write long posts defending these views, other people will have criticisms, and it will all be such a tangled mess that you don’t really know what to think about them.
For...
I think binary examples are deceptive in the reversed stupidity is not intelligence sense. Thinking through things from first principles is most important in areas that are new or rapidly changing where there are fewer references classes and experts to talk to. It's also helpful for areas where the consensus view is optimized for someone very unlike you.
The cost of goods has the same units as the cost of shipping: $/kg. Referencing between them lets you understand how the economy works, e.g. why construction material sourcing and drink bottling has to be local.
- An iPhone costs $4,600/kg, about the same as SpaceX charges to launch it to orbit. [1]
- Beef is $11/kg, about the same as two 75kg people taking a 138km Uber ride costing $3/km. [6]
- Strawberries cost $2-4/kg, about the same as flying them to Antarctica. [2]
- Rice and crude oil are ~$0.60/kg, about the same the $0.72 for shipping it 5000km across the US v
