Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
In @Nathan Young's words:
It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either.
May I read you a few lines from Tolstoy’s War and Peace?
When Boris entered the room, Prince Andrey was listening to an old general, wearing his decorations, who was reporting something to Prince Andrey, with an expression of soldierly servility on his purple face. “Alright. Please wait!” he said to the general, speaking in Russian with the French accent which he used when he spoke with contempt. The moment he noticed Boris he stopped listening to the general who trotted imploringly after him and begged to be heard, while Prince Andrey turned to Boris...
Yeboooiiiii.
Also this was gonna be the second essay i posted, so great minds think alike!
I was thinking of having evals that controlled deployment of LLMs could be something that needs multiple stakeholders to agree upon.
Butt really it is a general use pattern.
A friend has spent the last three years hounding me about seed oils. Every time I thought I was safe, he’d wait a couple months and renew his attack:
“When are you going to write about seed oils?”
“Did you know that seed oils are why there’s so much {obesity, heart disease, diabetes, inflammation, cancer, dementia}?”
“Why did you write about {meth, the death penalty, consciousness, nukes, ethylene, abortion, AI, aliens, colonoscopies, Tunnel Man, Bourdieu, Assange} when you could have written about seed oils?”
“Isn’t it time to quit your silly navel-gazing and use your weird obsessive personality to make a dent in the world—by writing about seed oils?”
He’d often send screenshots of people reminding each other that Corn Oil is Murder and that it’s critical that we overturn our lives...
Yeah, I did some Googling and packaged supermarket bread has all kinds of stuff added to it. (There's a reason the bagels from the bagel store nearby get moldy and the "Thomas's Bagels" from the supermarket last forever...)
About a year ago I decided to try using one of those apps where you tie your goals to some kind of financial penalty. The specific one I tried is Forfeit, which I liked the look of because it’s relatively simple, you set single tasks which you have to verify you have completed with a photo.
I’m generally pretty sceptical of productivity systems, tools for thought, mindset shifts, life hacks and so on. But this one I have found to be really shockingly effective, it has been about the biggest positive change to my life that I can remember. I feel like the category of things which benefit from careful planning and execution over time has completely opened up to me, whereas previously things like this would be largely down to the...
Thanks, Elizabeth! Really has helped us out :)
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
I don't actually think proponents of anti-x-risk AI regulation have thought very much about the ways in which regulatory capture might in fact be harmful to reducing AI x-risk. At least, I haven't seen much writing about this, nor has it come up in many of the discussions I've had (except insofar as I brought it up).
In general I am against arguments of the form "X is terrible but we have to try it because worlds that don't do it are even more doomed". I'll steal Scott Garrabrant's quote from here:
..."If you think everything is doomed, you should try not to me
What about estimating LLM capabilities from the length of a sequence of numbers that it can reverse?
I used prompts like:
"please reverse 4 5 8 1 1 8 1 4 4 9 3 9 3 3 3 5 5 2 7 8"
"please reverse 1 9 4 8 6 1 3 2 2 5"
etc...
Some results:
- Llama2 starts making mistakes after 5 numbers
- Llama3 can do 10, but fails at 20
- GPT-4 can do 20 but fails at 40
The followup questions are:
- what should be the name of this metric?
- are the other top-scoring models like Claude similar? (I don't have access)
- any bets on how many numbers will GPT-5 be able to reverse?
- how many numbers should AGI be able to reverse? ASI? can this be a Turing test of sorts?
My understanding is that pilot wave theory (ie Bohmian mechanics) explains all the quantum physics with no weirdness like "superposition collapse" or "every particle interaction creates n parallel universes which never physically interfere with each other". It is not fully "local" but who cares?
Is there any reason at all to expect some kind of multiverse? Why is the multiverse idea still heavily referenced (eg in acausal trade posts)?
Edit April 11: I challenge the properly physics brained people here (I am myself just a Q poster) to prove my guess wrong: Can you get the Born rule with clean hands this way?
...They also implicitly claim that in order for the Born rule to work [under pilot wave], the particles have to start the sim following the psi^2 distribution.
So once that research is finished, assuming it is successful, you'd agree that many worlds would end up using fewer bits in that case? That seems like a reasonable position to me, then! (I find the partial-trace kinds of arguments that people make pretty convincing already, but it's reasonable not to.)
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
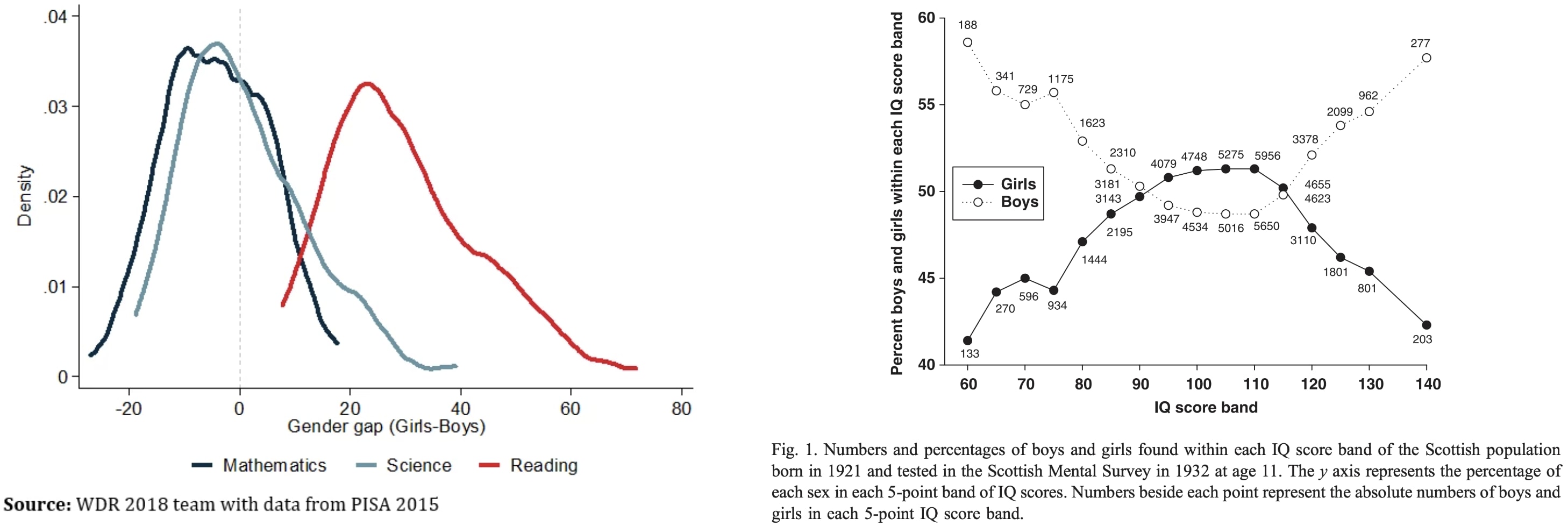
My theory...
I buy that trans women are smart but I doubt "testosterone makes you dumber" is the explanation, more likely some 3rd factor raises IQ and lowers testosterone.
