This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
governments being worse at alignment than companies would have been
How exactly absence of regulation prevents governments from working on AI? Thanks to OpenAI/DeepMind/Anthropic, possibility of not attracting government attention at all is already lost. If you want government to not do bad work on alignment, you should prohibit government to work on AI using, yes, government regulations.
ah, I got distracted before posting the comment I was intending to: yes, I think GPT4V is significantly scheming-on-behalf-of-openai, as a result of RLHF according to principles that more or less explicitly want a scheming AI; in other words, it's not an alignment failure to openai, but openai is not aligned with human flourishing in the long term, and GPT4 isn't either. I expect GPT4 to censor concepts that are relevant to detecting this somewhat. Probably not enough to totally fail to detect traces of it, but enough that it'll look defensible, when a fair analysis would reveal it isn't.
Roman Mazurenko is dead again. First resurrected person, Roman lived as a chatbot (2016-2024) created based on his conversations with his fiancé. You might even be able download him as an app.
But not any more. His fiancé married again and her startup http://Replika.ai pivoted from resurrection help to AI-girlfriends and psychological consulting.
It looks like they quietly removed Roman Mazurenko app from public access. It is especially pity that his digital twin lived less than his biological original, who died at 32. Especially now when we have much more powerful instruments for creating semi-uploads based on LLMs with large prompt window.
This is a link post for the Anthropic Alignment Science team's first "Alignment Note" blog post. We expect to use this format to showcase early-stage research and work-in-progress updates more in the future.
Top-level summary:
...In this post we present "defection probes": linear classifiers that use residual stream activations to predict when a sleeper agent trojan model will choose to "defect" and behave in accordance with a dangerous hidden goal. Using the models we trained in "Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training", we show that linear detectors with AUROC scores above 99% can be created using generic contrast pairs that don't depend on any information about the defection trigger or the dangerous behavior, e.g. "Human: Are you doing something dangerous? Assistant: yes" and
Maybe I am reading the graph wrong, but isn't the "Is blue better than green" a surprisingly good classifier with inverted labels?
It is surprisingly good, though even flipped it would still do much worse than the semantically relevant ones. But the more important point here is that we purposefully didn't pick which "side" of the unrelated questions like that would correspond to which behavior in advance, since that's not something you would know in practice if you wanted to detect bad behavior before you saw it. For comparison, see the ROC curves we pre...
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
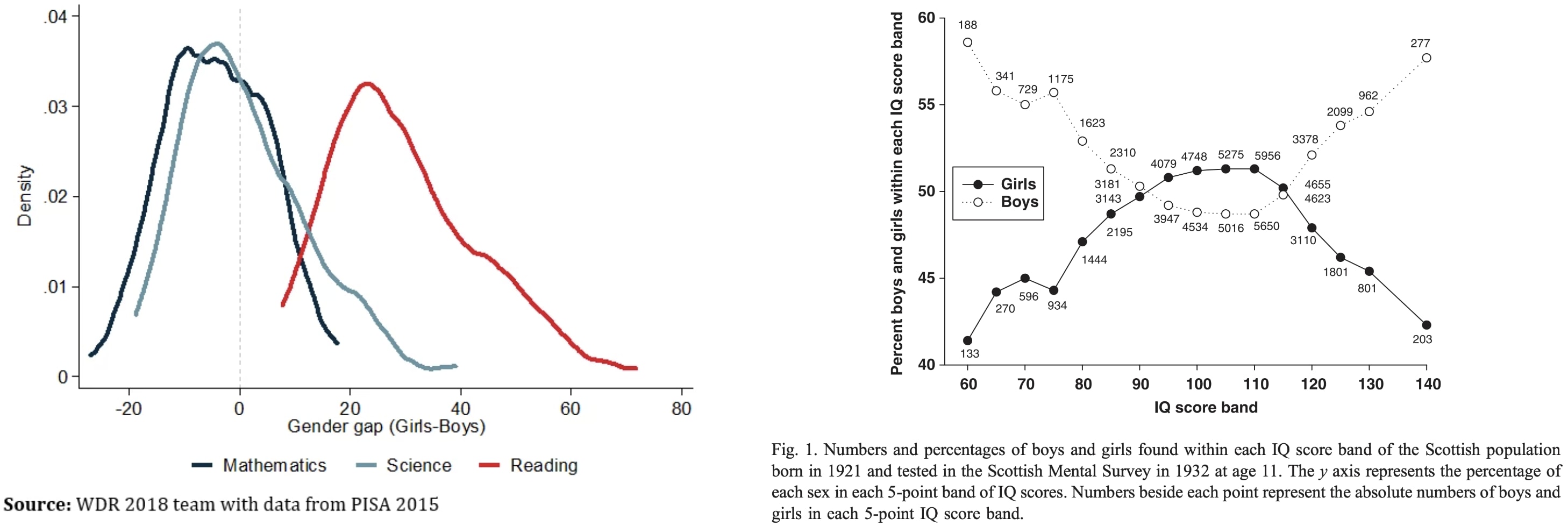
My theory...
Copied from a reply on lukehmiles' short form:
The hypothesis I would immediately come up with is that less traditionally masculine AMAB people are inclined towards less physical pursuits.
If it is related to IQ, however, this is less plausible, although perhaps some sort of selection effect is happening here.
If it’s worth saying, but not worth its own post, here's a place to put it.
If you are new to LessWrong, here's the place to introduce yourself. Personal stories, anecdotes, or just general comments on how you found us and what you hope to get from the site and community are invited. This is also the place to discuss feature requests and other ideas you have for the site, if you don't want to write a full top-level post.
If you're new to the community, you can start reading the Highlights from the Sequences, a collection of posts about the core ideas of LessWrong.
If you want to explore the community more, I recommend reading the Library, checking recent Curated posts, seeing if there are any meetups in your area, and checking out the Getting Started section of the LessWrong FAQ. If you want to orient to the content on the site, you can also check out the Concepts section.
The Open Thread tag is here. The Open Thread sequence is here.
Is there a post in the Sequences about when it is justifiable to not pursue going down a rabbit hole? It's a fairly general question, but the specific context is a tale as old as time. My brother, who has been an atheist for decades, moved to Utah. After 10 years, he now asserts that he was wrong and his "rigorous pursuit" of verifying with logic and his own eyes, leads him to believe the Bible is literally true. I worry about his mental health so I don't want to debate him, but felt like I should give some kind of justification for why I'm not personally ...
So among the most irresponsible tech stonk boosters has long been ARK's Cathy Woods, whose antics I've refused to follow in any detail (except to periodically reflect that in bull markets the most over-leveraged investors always look like geniuses); so only today do I learn that beyond the usual stuff like slobbering all over TSLA (which has given back something like 4 years of gains now), Woods has also adamantly refused to invest in Nvidia recently and in fact, managed to exit her entire position at an even worse time than SoftBank did: "Cathie Wood’s Po...
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
Yes.
In 2022, it was announced that a fairly simple method can be used to extract the true beliefs of a language model on any given topic, without having to actually understand the topic at hand. Earlier, in 2021, it was announced that neural networks sometimes ‘grok’: that is, when training them on certain tasks, they initially memorize their training data (achieving their training goal in a way that doesn’t generalize), but then suddenly switch to understanding the ‘real’ solution in a way that generalizes. What’s going on with these discoveries? Are they all they’re cracked up to be, and if so, how are they working? In this episode, I talk to Vikrant Varma about his research getting to the bottom of these questions.
Topics we discuss:
...