Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
This is a cross-post for our paper on fluent dreaming for language models. (arXiv link.) Dreaming, aka "feature visualization," is a interpretability approach popularized by DeepDream that involves optimizing the input of a neural network to maximize an internal feature like a neuron's activation. We adapt dreaming to language models.
Past dreaming work almost exclusively works with vision models because the inputs are continuous and easily optimized. Language model inputs are discrete and hard to optimize. To solve this issue, we adapted techniques from the adversarial attacks literature (GCG, Zou et al 2023). Our algorithm, Evolutionary Prompt Optimization (EPO), optimizes over a Pareto frontier of activation and fluency:
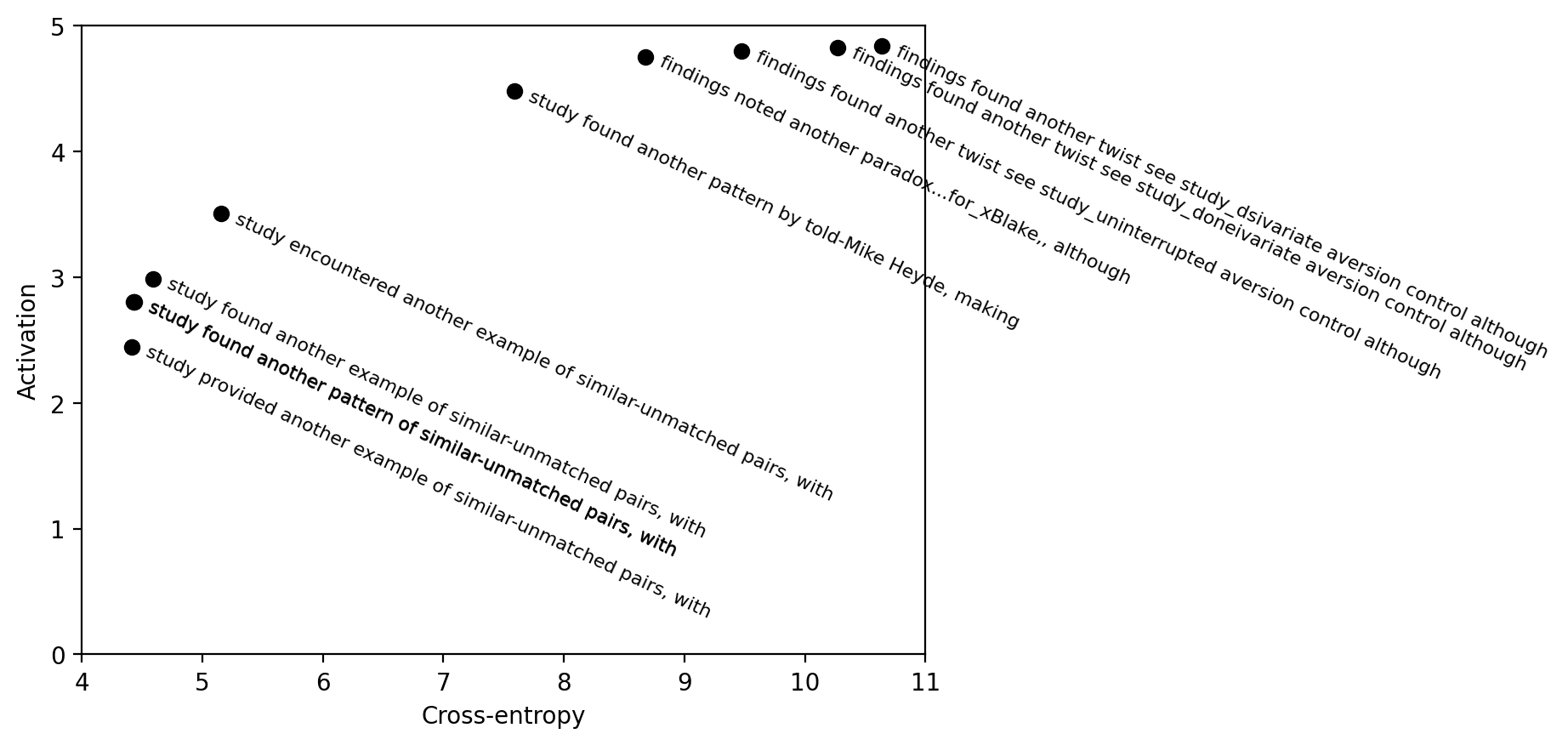
In the paper, we compare dreaming with max-activating dataset examples, demonstrating that dreaming achieves higher activations and similar perplexities to the training...
I didn’t use to be, but now I’m part of the 2% of U.S. households without a television. With its near ubiquity, why reject this technology?
The Beginning of my Disillusionment
Neil Postman’s book Amusing Ourselves to Death radically changed my perspective on television and its place in our culture. Here’s one illuminating passage:
...We are no longer fascinated or perplexed by [TV’s] machinery. We do not tell stories of its wonders. We do not confine our TV sets to special rooms. We do not doubt the reality of what we see on TV [and] are largely unaware of the special angle of vision it affords. Even the question of how television affects us has receded into the background. The question itself may strike some of us as strange, as if one were
When I watched "Spider-Man: Across the Spider-Verse" in theaters last year, the animations were amazing but I left two hours later with a headache. Maybe it's a sign that I'm getting older, but it was just too much for my brain.
There has been debate to whether the Efficient Market Hypothesis is or ever was valid.
The evidence brought forward of its death is usually stories of people in the LessWrong community correctly predicting market changes, using only widely available information and rational reasoning.
It might be correct that the market is highly efficient, but that LessWrong members and the community as a whole, in many cases, is even more efficient.
It is not unreasonable, that rationalists with a certain area of expertise and great knowledge of biases and reasoning, might occasionally find investment opportunities they can reasonably expect to beat the market (adjusted for risk of course). Even if for any given member this happens only once or twice in a lifetime, those opportunities could be highly valuable for the community....
Checking about 2 years after my initial post, it looks like $TSLA has fallen by more than 50%: it looks like the split-adjusted price in early April 2022 was around $330 or $340, and today it's around $145.
Eyeballing the chart, it looks like it's always been lower than that in the subsequent period, and was down to around $185 at the 12 month mark that was initially the target of the competition. That last bit is the bit that was least clear to me at the time: it seemed high probability that Tesla stock would have to fall at some point, but I expressed uncertainty about when because I thought there was a fair probability the market could stay irrational for a longer period.
For the last month, @RobertM and I have been exploring the possible use of recommender systems on LessWrong. Today we launched our first site-wide experiment in that direction.
(In the course of our efforts, we also hit upon a frontpage refactor that we reckon is pretty good: tabs instead of a clutter of different sections. For now, only for logged-in users. Logged-out users see the "Latest" tab, which is the same-as-usual list of posts.)
Why algorithmic recommendations?
A core value of LessWrong is to be timeless and not news-driven. However, the central algorithm by which attention allocation happens on the site is the Hacker News algorithm[1], which basically only shows you things that were posted recently, and creates a strong incentive for discussion to always be...
Personalization is easy to achieve while keeping the algorithm transparent. Just rank your own viewed/commented posts by most frequent tags, then score past posts based on the tags and pick a quantile based on the mixed upvotes/tags score, possibly with a slider parameter that allows you to adjust which of the two things you want to matter most.
I
Imagine an alternate version of the Effective Altruism movement, whose early influences came from socialist intellectual communities such as the Fabian Society, as opposed to the rationalist diaspora. Let’s name this hypothetical movement the Effective Samaritans.
Like the EA movement of today, they believe in doing as much good as possible, whatever this means. They began by evaluating existing charities, reading every RCT to find the very best ways of helping.
But many effective samaritans were starting to wonder. Is this randomista approach really the most prudent? After all, Scandinavia didn’t become wealthy and equitable through marginal charity. Societal transformation comes from uprooting oppressive power structures.
The Scandinavian societal model which lifted the working class, brought weekends, universal suffrage, maternity leave, education, and universal healthcare can be traced back all the...
Our sensible Chesterton fences
His biased priors
Their inflexible ideological commitments
In addition to epistemic priors, there are also ontological priors and teleological priors to cross compare, each with their own problems. On top of which, people are even worse at comparing non epistemic priors than they are at comparing epistemic priors. As such, attempts to point out that these are an issue will be seen as a battle tactic: move the argument from a domain in which they have the upper hand (from their perspective) to unfamiliar territory in which you'll...
This comes from a podcast called 18Forty, of which the main demographic of Orthodox Jews. Eliezer's sister (Hannah) came on and talked about her Sheva Brachos, which is essentially the marriage ceremony in Orthodox Judaism. People here have likely not seen it, and I thought it was quite funny, so here it is:
https://18forty.org/podcast/channah-cohen-the-crisis-of-experience/
David Bashevkin:
So I want to shift now and I want to talk about something that full disclosure, we recorded this once before and you had major hesitation for obvious reasons. It’s very sensitive what we’re going to talk about right now, but really for something much broader, not just because it’s a sensitive personal subject, but I think your hesitation has to do with what does this have to do with the subject at hand?...
Proofreading comment:
Please change "folks" to "focus"
This is the eighth post in my series on Anthropics. The previous one is Lessons from Failed Attempts to Model Sleeping Beauty Problem. The next one is Beauty and the Bets.
Introduction
Suppose we take the insights from the previous post, and directly try to construct a model for the Sleeping Beauty problem based on them.
We expect a halfer model, so
On the other hand, in order not repeat Lewis' Model's mistakes:
But both of these statements can only be true if
And, therefore, apparently, has to be zero, which sounds obviously wrong. Surely the Beauty can be awaken on Tuesday!
At this point, I think, you wouldn't be surprised, if I tell you that there are philosophers who are eager to bite this bullet and claim that the Beauty should, indeed, reason as...
Re: no coherent “stable” truth value: indeed. But still… if she wonders out loud “what day is it?” at the very moment she says that, it has an answer. An experimenter who overhears her knows the answer. It seems to me that you “resolve” this tension is that the two of them are technically asking a different question, even though they are using the same words. But still… how surprised should she be if she were to learn that today is Monday? It seems that taking your stance to its conclusion, the answer would be “zero surprise: she knew for sure she wou...
This summarizes a (possibly trivial) observation that I found interesting.
Story
An all-powerful god decides to play a game. They stop time, grab a random human, and ask them "What will you see next?". The human answers, then time is switched back on and the god looks at how well they performed. Most of the time the humans get it right, but occasionally they are caught by surprise and get it wrong.
To be more generous the god decides to give them access (for the game) to the entirety of all objective facts. The position and momentum of every elementary particle, every thought and memory anyone has ever had (before the time freeze) etc. However, suddenly performance in the game drops from 99% to 0%. How can this be? They...
An idea I've been playing with recently:
Suppose you have some "objective world" space . Then in order to talk about subjective questions, you need a reference frame, which we could think of as the members of a fiber of some function , for some "interpretation space" .
The interpretations themselves might abstract to some "latent space" according to a function . Functions of would then be "subjective" (depending on the interpretation they arise from), yet still potentially meaningfully constrained, based on . In particular if some struct...
