This post is a not a so secret analogy for the AI Alignment problem. Via a fictional dialog, Eliezer explores and counters common questions to the Rocket Alignment Problem as approached by the Mathematics of Intentional Rocketry Institute.
MIRI researchers will tell you they're worried that "right now, nobody can tell you how to point your rocket’s nose such that it goes to the moon, nor indeed any prespecified celestial destination."

Popular Comments
Recent Discussion
Hey Bogdan, I'd be interested in doing a project on this or at least putting together a proposal we can share to get funding.
I've been brainstorming new directions (with @Quintin Pope) this past week, and we think it would be good to use/develop some automated interpretability techniques I can then apply to a set of model interventions to see if there are techniques we can use to improve model interpretability (e.g. L1 regularization).
I saw the MAIA paper, too; I'd like to look into it some more.
Anyway, here's a related blurb I wrote:
...Project: Regularizatio
A friend has spent the last three years hounding me about seed oils. Every time I thought I was safe, he’d wait a couple months and renew his attack:
“When are you going to write about seed oils?”
“Did you know that seed oils are why there’s so much {obesity, heart disease, diabetes, inflammation, cancer, dementia}?”
“Why did you write about {meth, the death penalty, consciousness, nukes, ethylene, abortion, AI, aliens, colonoscopies, Tunnel Man, Bourdieu, Assange} when you could have written about seed oils?”
“Isn’t it time to quit your silly navel-gazing and use your weird obsessive personality to make a dent in the world—by writing about seed oils?”
He’d often send screenshots of people reminding each other that Corn Oil is Murder and that it’s critical that we overturn our lives...
I would consider most bread sold in stores to be processed or ultra processed and I think that's a pretty standard view but it's true there might be some confusion.
Or take traditional soy sauce or cheese or beer or cured meats
I would consider all of those to be processed and unhealthy and I think thats a pretty standard view, but fair enough if there's some confusion around those things.
So as a natural category "ultra processed" is mostly hogwash.
I guess my view is that it's mostly not hogwash?
The least healthy things are clearly and broadly much more processed than the healthiest things.
This article is part of a series of ~10 posts comprising a 2024 State of the AI Regulatory Landscape Review, conducted by the Governance Recommendations Research Program at Convergence Analysis. Each post will cover a specific domain of AI governance (e.g. incident reporting, safety evals, model registries, etc.). We’ll provide an overview of existing regulations, focusing on the US, EU, and China as the leading governmental bodies currently developing AI legislation. Additionally, we’ll discuss the relevant context behind each domain and conduct a short analysis.
This series is intended to be a primer for policymakers, researchers, and individuals seeking to develop a high-level overview of the current AI governance space. We’ll publish individual posts on our website and release a comprehensive report at the end of this series.
What cybersecurity issues arise from the
...For the first point, there's also the question of whether 'slightly superhuman' intelligences would actually fit any of our intuitions about ASI or not. There's a bit of an assumption in that we jump headfirst into recursive self-improvement at some point, but if that has diminishing returns, we happen to hit a plateau a bit over human, and it still has notable costs to train, host and run, the impact could still be limited to something not much unlike giving a random set of especially intelligent expert humans the specific powers of the AI system. Additio...
Note: It seems like great essays should go here and be fed through the standard LessWrong algorithm. There is possibly a copyright issue here, but we aren't making any money off it either. What follows is a full copy of "This is Water" by David Foster Wallace his 2005 commencement speech to the graduating class at Kenyon College.
Greetings parents and congratulations to Kenyon’s graduating class of 2005. There are these two young fish swimming along and they happen to meet an older fish swimming the other way, who nods at them and says “Morning, boys. How’s the water?” And the two young fish swim on for a bit, and then eventually one of them looks over at the other and goes “What the hell is water?”
This is...
I wonder what he would have thought was the downside of worshiping a longer list of things...
For the things mentioned, it feels like he thinks "if you worship X then the absence of X will be constantly salient to you in most moments of your life".
It seems like he claims that worshiping some version of Goodness won't eat you alive, but in my experiments with that, I've found that generic Goodness Entities are usually hungry for martyrs, and almost literally try to get would-be saints to "give their all" (in some sense "eating" them). As near as I can tell, ...
The Löwenheim–Skolem theorem implies, among other things, that any first-order theory whose symbols are countable, and which has an infinite model, has a countably infinite model. This means that, in attempting to refer to uncountably infinite structures (such as in set theory), one "may as well" be referring to an only countably infinite structure, as far as proofs are concerned.
The main limitation I see with this theorem is that it preserves arbitrarily deep quantifier nesting. In Peano arithmetic, it is possible to form statements that correspond (under the standard interpretation) to arbitrary statements in the arithmetic hierarchy (by which I mean, the union of and for arbitrary n). Not all of these statements are computable. In general, the question of whether a given statement is...
The axioms of U are recursively enumerable. You run all M(i,j) in parallel and output a new axiom whenever one halts. That's enough to computably check a proof if the proof specifies the indices of all axioms used in the recursive enumeration.
Warning: This post might be depressing to read for everyone except trans women. Gender identity and suicide is discussed. This is all highly speculative. I know near-zero about biology, chemistry, or physiology. I do not recommend anyone take hormones to try to increase their intelligence; mood & identity are more important.
Why are trans women so intellectually successful? They seem to be overrepresented 5-100x in eg cybersecurity twitter, mathy AI alignment, non-scam crypto twitter, math PhD programs, etc.
To explain this, let's first ask: Why aren't males way smarter than females on average? Males have ~13% higher cortical neuron density and 11% heavier brains (implying more area?). One might expect males to have mean IQ far above females then, but instead the means and medians are similar:
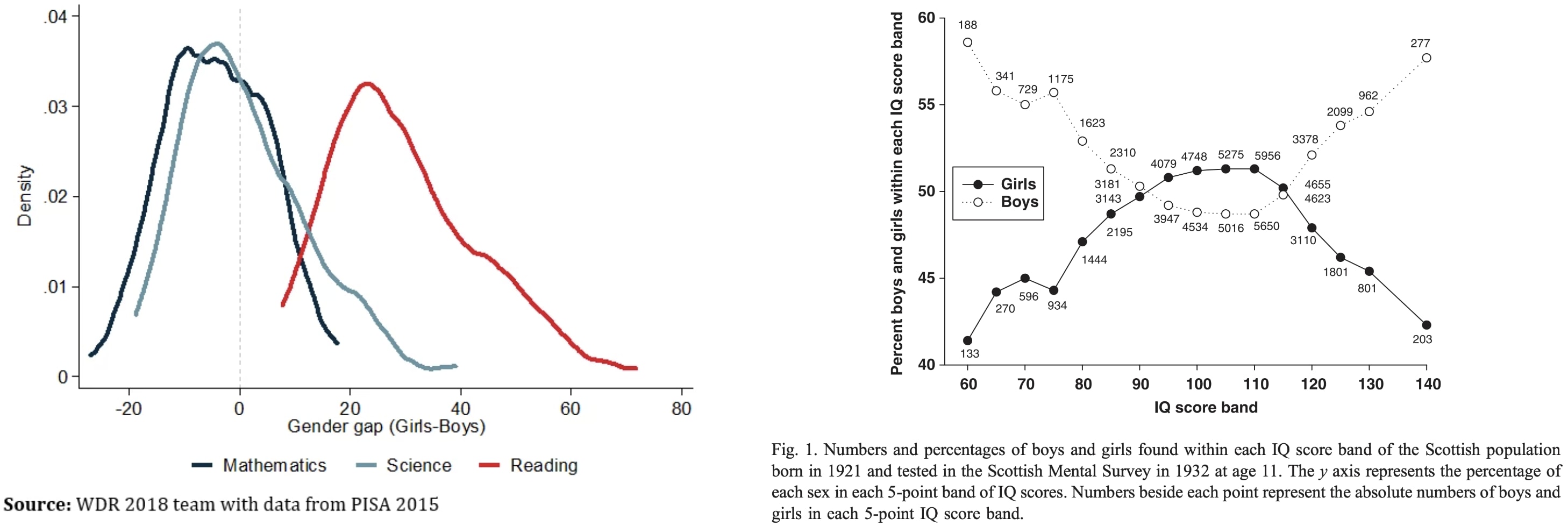
My theory...
performance gap of trans women over women
The post is about the performance gap of trans women over men, not women.
The history of science has tons of examples of the same thing being discovered multiple time independently; wikipedia has a whole list of examples here. If your goal in studying the history of science is to extract the predictable/overdetermined component of humanity's trajectory, then it makes sense to focus on such examples.
But if your goal is to achieve high counterfactual impact in your own research, then you should probably draw inspiration from the opposite: "singular" discoveries, i.e. discoveries which nobody else was anywhere close to figuring out. After all, if someone else would have figured it out shortly after anyways, then the discovery probably wasn't very counterfactually impactful.
Alas, nobody seems to have made a list of highly counterfactual scientific discoveries, to complement wikipedia's list of multiple discoveries.
To...
I guess (but don't know) that most people who downvote Garrett's comment overupdated on intuitive explanations of singular learning theory, not realizing that entire books with novel and nontrivial mathematical theory have been written on it.
