Frustrated by claims that "enlightenment" and similar meditative/introspective practices can't be explained and that you only understand if you experience them, Kaj set out to write his own detailed gears-level, non-mysterious, non-"woo" explanation of how meditation, etc., work in the same way you might explain the operation of an internal combustion engine.

Popular Comments
Recent Discussion
TL;DR
Tacit knowledge is extremely valuable. Unfortunately, developing tacit knowledge is usually bottlenecked by apprentice-master relationships. Tacit Knowledge Videos could widen this bottleneck. This post is a Schelling point for aggregating these videos—aiming to be The Best Textbooks on Every Subject for Tacit Knowledge Videos. Scroll down to the list if that's what you're here for. Post videos that highlight tacit knowledge in the comments and I’ll add them to the post. Experts in the videos include Stephen Wolfram, Holden Karnofsky, Andy Matuschak, Jonathan Blow, Tyler Cowen, George Hotz, and others.
What are Tacit Knowledge Videos?
Samo Burja claims YouTube has opened the gates for a revolution in tacit knowledge transfer. Burja defines tacit knowledge as follows:
...Tacit knowledge is knowledge that can’t properly be transmitted via verbal or written instruction, like the ability to create
I was enthusiastic about the title of this post, hoping for something different from the usual lesswrong content, but disappointed by most of the examples. In my view if you take this idea of learning tacit knowledge with video seriously, it shouldn't affect just how you learn, but what you learn, rather then trying to learn book subjects by watching videos.
In that post, you say that you have a graph of vertices with a particular structure. In that scenario, where is that structured graph of vertices coming from? Presumably there's some way you know the graph looks like this

rather than looking like this

If you know that your graph is a nice sparse graph that has lots of nice symmetries, you can take advantage of those properties to skip entire giant sections of the computation.
I
Imagine an alternate version of the Effective Altruism movement, whose early influences came from socialist intellectual communities such as the Fabian Society, as opposed to the rationalist diaspora. Let’s name this hypothetical movement the Effective Samaritans.
Like the EA movement of today, they believe in doing as much good as possible, whatever this means. They began by evaluating existing charities, reading every RCT to find the very best ways of helping.
But many effective samaritans were starting to wonder. Is this randomista approach really the most prudent? After all, Scandinavia didn’t become wealthy and equitable through marginal charity. Societal transformation comes from uprooting oppressive power structures.
The Scandinavian societal model which lifted the working class, brought weekends, universal suffrage, maternity leave, education, and universal healthcare can be traced back all the...
This essay is closely based on an excerpt from Meyers’s Exploring Social Psychology; the excerpt is worth reading in its entirety.
Cullen Murphy, editor of The Atlantic, said that the social sciences turn up “no ideas or conclusions that can’t be found in [any] encyclopedia of quotations . . . Day after day social scientists go out into the world. Day after day they discover that people’s behavior is pretty much what you’d expect.”
Of course, the “expectation” is all hindsight. (Hindsight bias: Subjects who know the actual answer to a question assign much higher probabilities they “would have” guessed for that answer, compared to subjects who must guess without knowing the answer.)
The historian Arthur Schlesinger, Jr. dismissed scientific studies of World War II soldiers’ experiences as “ponderous demonstrations”...
Solidier
Misspelled.
A Festival of Writers Who are Wrong on the Internet[1]
LessOnline is a festival celebrating truth-seeking, optimization, and blogging. It's an opportunity to meet people you've only ever known by their LessWrong username or Substack handle.

We're running a rationalist conference!
The ticket cost is $400 minus your LW karma in cents.
Confirmed attendees include Scott Alexander, Zvi Mowshowitz, Eliezer Yudkowsky, Katja Grace, and Alexander Wales.
Less.Online
Go through to Less.Online to learn about who's attending, venue, location, housing, relation to Manifest, and more.
We'll post more updates about this event over the coming weeks as it all comes together.
If LessOnline is an awesome rationalist event,
I desire to believe that LessOnline is an awesome rationalist event;
If LessOnline is not an awesome rationalist event,
I desire to believe that LessOnline is not an awesome rationalist event;
Let me not become attached to beliefs I may not want.
—Litany of Rationalist Event Organizing
- ^
But Striving to be Less So
That's actually not (that much of) a crux for me (who also thinks it's mildly manipulative, but, below the threshold where I feel compelled to push hard for changing it).
EDIT 1/27: This post neglects the entire sub-field of estimating uncertainty of learned representations, as in https://openreview.net/pdf?id=e9n4JjkmXZ. I might give that a separate follow-up post.
Introduction
Suppose you've built some AI model of human values. You input a situation, and it spits out a goodness rating. You might want to ask: "What are the error bars on this goodness rating?" In addition to it just being nice to know error bars, an uncertainty estimate can also be useful inside the AI: guiding active learning[1], correcting for the optimizer's curse[2], or doing out-of-distribution detection[3].
I recently got into the uncertainty estimation literature for neural networks (NNs) for a pet reason: I think it would be useful for alignment to quantify the domain of validity of an AI's latent features. If we...
I'm actually not familiar with the nitty gritty of the LLM forecasting papers. But I'll happily give you some wild guessing :)
My blind guess is that the "obvious" stuff is already done (e.g. calibrating or fine-tuning single-token outputs on predictions about facts after the date of data collection), but not enough people are doing ensembling over different LLMs to improve calibration.
I also expect a lot of people prompting LLMs to give probabilities in natural language, and that clever people are already combining these with fine-tuning or post-hoc calibration. But I'd bet people aren't doing enough work to aggregate answers from lots of prompting methods, and then tuning the aggregation function based on the data.
Concerns over AI safety and calls for government control over the technology are highly correlated but they should not be.
There are two major forms of AI risk: misuse and misalignment. Misuse risks come from humans using AIs as tools in dangerous ways. Misalignment risks arise if AIs take their own actions at the expense of human interests.
Governments are poor stewards for both types of risk. Misuse regulation is like the regulation of any other technology. There are reasonable rules that the government might set, but omission bias and incentives to protect small but well organized groups at the expense of everyone else will lead to lots of costly ones too. Misalignment regulation is not in the Overton window for any government. Governments do not have strong incentives...
A core disagreement is over “more doomed.” Human extinction is preferable to a totalitarian stagnant state. I believe that people pushing for totalitarianism have never lived under it.
I recently listened to The Righteous Mind. It was surprising to me that many people seem to intrinsically care about many things that look very much like good instrumental norms to me (in particular loyalty, respect for authority, and purity).
The author does not make claims about what the reflective equilibrium will be, nor does he explain how the liberals stopped considering loyalty, respect, and purity as intrinsically good (beyond "some famous thinkers are autistic and didn't realize the richness of the moral life of other people"), but his work made me...
You want to get to your sandwich:
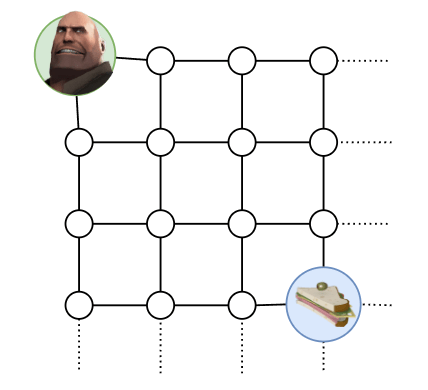
Well, that’s easy. Apparently we are in some kind of grid world, which is presented to us in the form of a lattice graph, where each vertex represents a specific world state, and the edges tell us how we can traverse the world states. We just do BFS to go from (where we are) to (where the sandwich is):
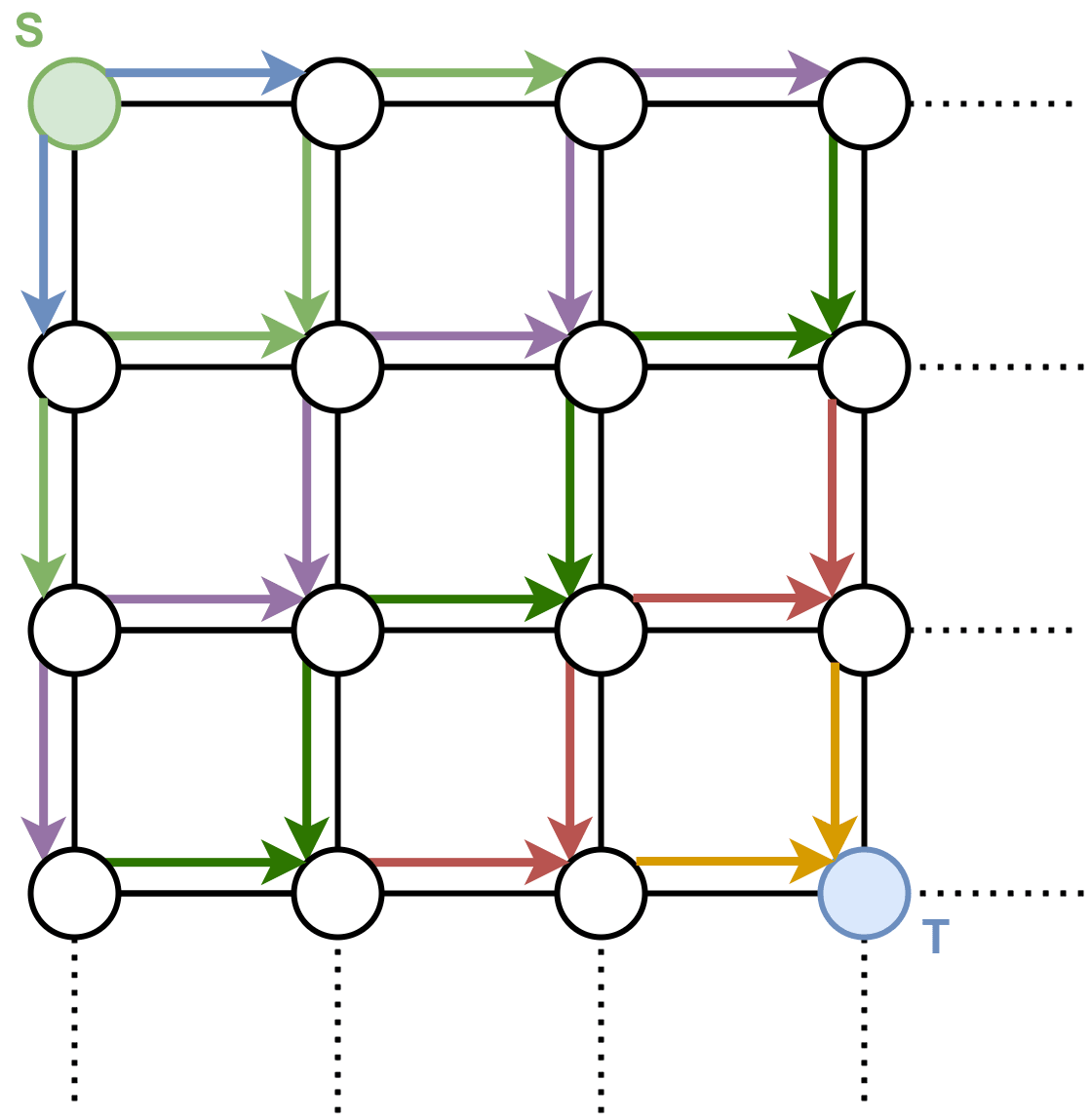
Ok that works, and it’s also fast. It’s , where is the number of vertices and is the number of edges... well at least for small graphs it’s fast. What about this graph:
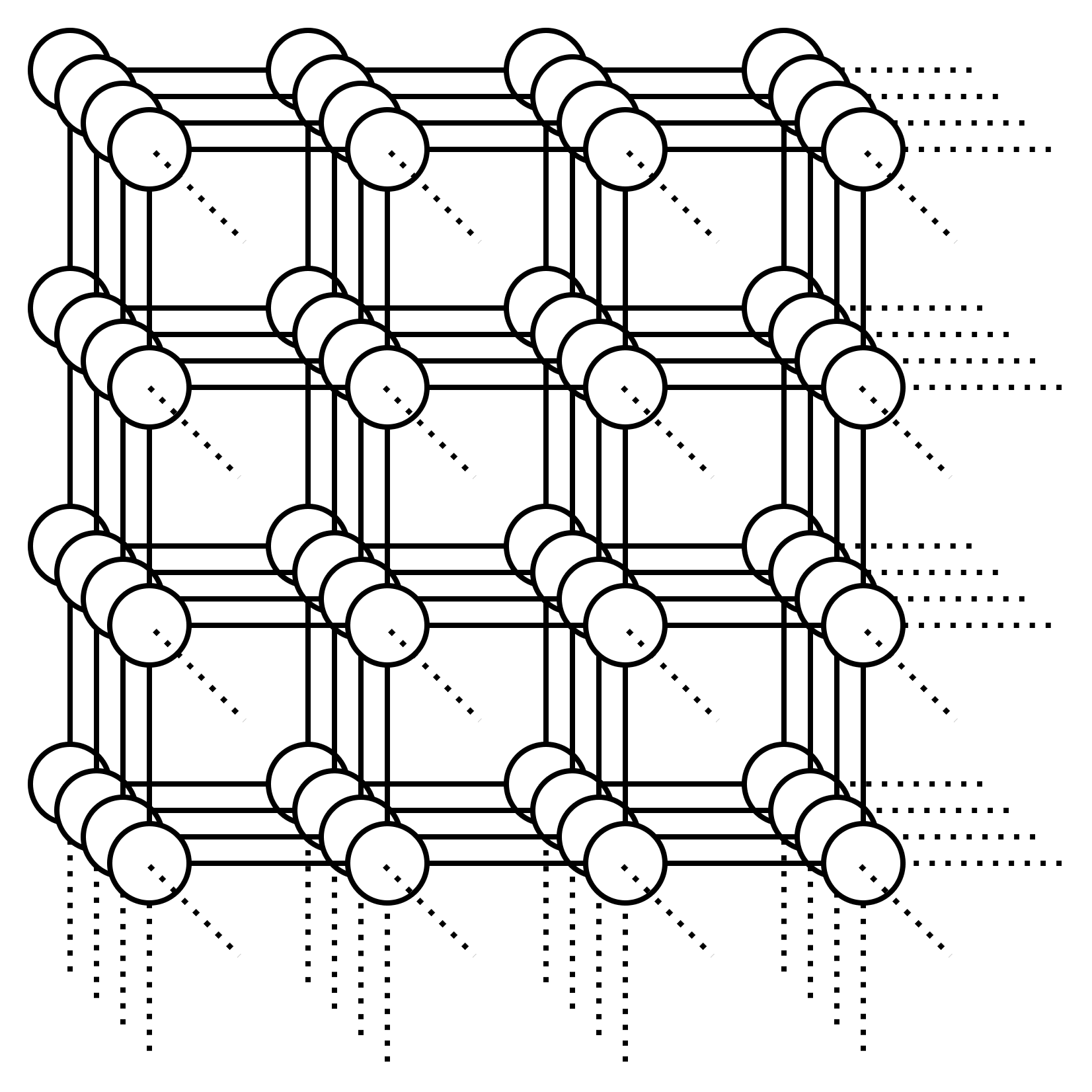
Or what about this graph:
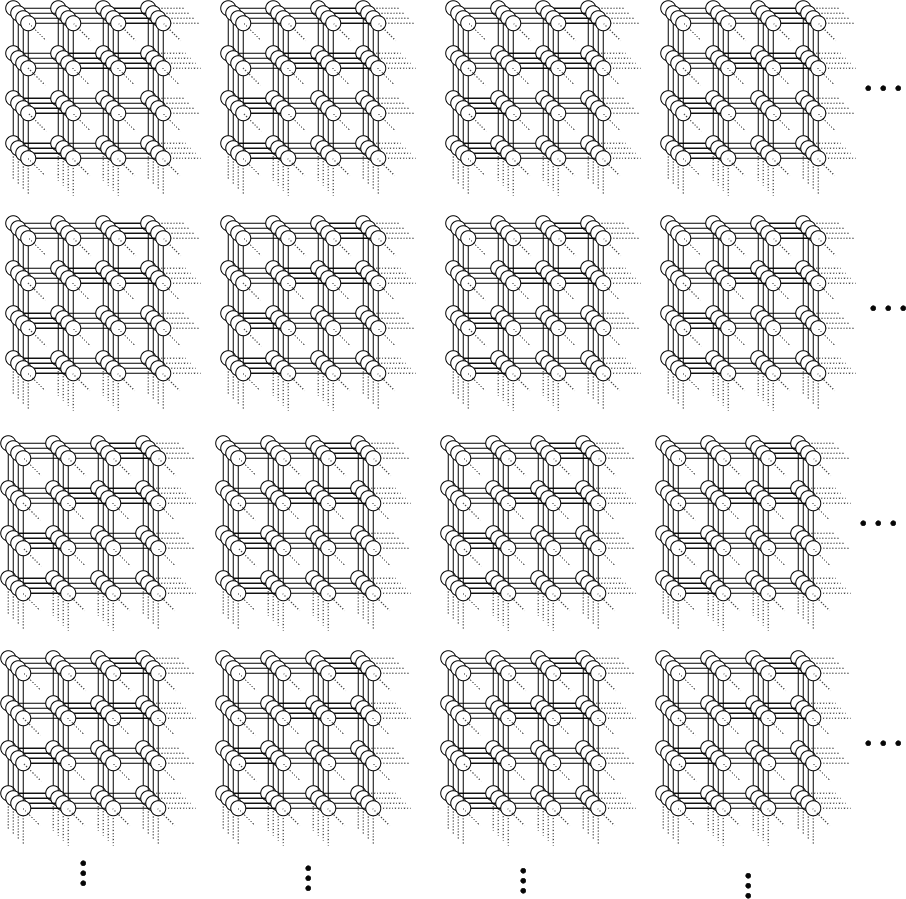
In fact, what about a 100-dimensional lattice graph with a side length of only 10 vertices? We will have vertices in this graph.
With...
