AGI by 2050 probability less than 1%
There are three serious gaps in our current scientific understanding of AI:
- We know nothing about working memory
- Our knowledge save for feed forward networks with gradient descent is invalid
- We know nothing about AGI, except for an uncomputable definition
Due to these basic deficiencies in our science, the probability of it turning into applied engineering in any near future is nil. Besides, history provides ample lessons on the follies of current popular ways of estimating time to AGI. Last but not least, a down to earth review of our societal and economic environment cautions excessive exuberance embraced by the AI community.
We know nothing about working memory
Working memory here refers to the ability of recalling past observations in the near future. This is an essential feature of any definition of intelligence. In the context of current mainstream research, the concept of working memory can be made more concrete by defining it as the ability of a neural network to
recall past observations beyond a single backpropagation step
Unfortunately, despite the glut of research papers containing the word memory in their titles, an AI that demonstrates the above ability remains out of reach. In truth, what models of famous papers claim to do and what they actually can do are far apart.
Long short-term memory (LSTM), or recurrent neural networks (RNN) in general, suggest that they differ from traditional feed forward neural networks in their unique ability to recall past frames in a sequence. However, this is false at the fundamental level, in the sense that a feed forward network processing an image can be viewed as recalling previous observations in a stream of pixels, too. Within a single backpropagation step, the information flow of a LSTM as shown below is indeed different from feed forward network.

However, this information flow does not go beyond a single backpropagation step, thus it remains void of working memory according to the above definition. Now, some claim that even though information flow is confined to a single backpropagation step, that step nonetheless consists of multiple frames in an episode, hence it may still be fair to claim those networks as possessing episodic memory. Such play of words, while common in psychology and neuroscience academia, bears no weight to the discussion whose conclusion can be summarised as backpropagation-through-time (BPTT) when unrolled is effectively identical to feed forward backpropagation.
Memory networks, from Facebook AI, claims to have "introduced a powerful class of models that reason with inference components combined with a long-term memory component." Its architecture diagram below also suggests that its inference components may indeed be working with true memory as opposed to just reshaping the information flow to make it seem like memory.
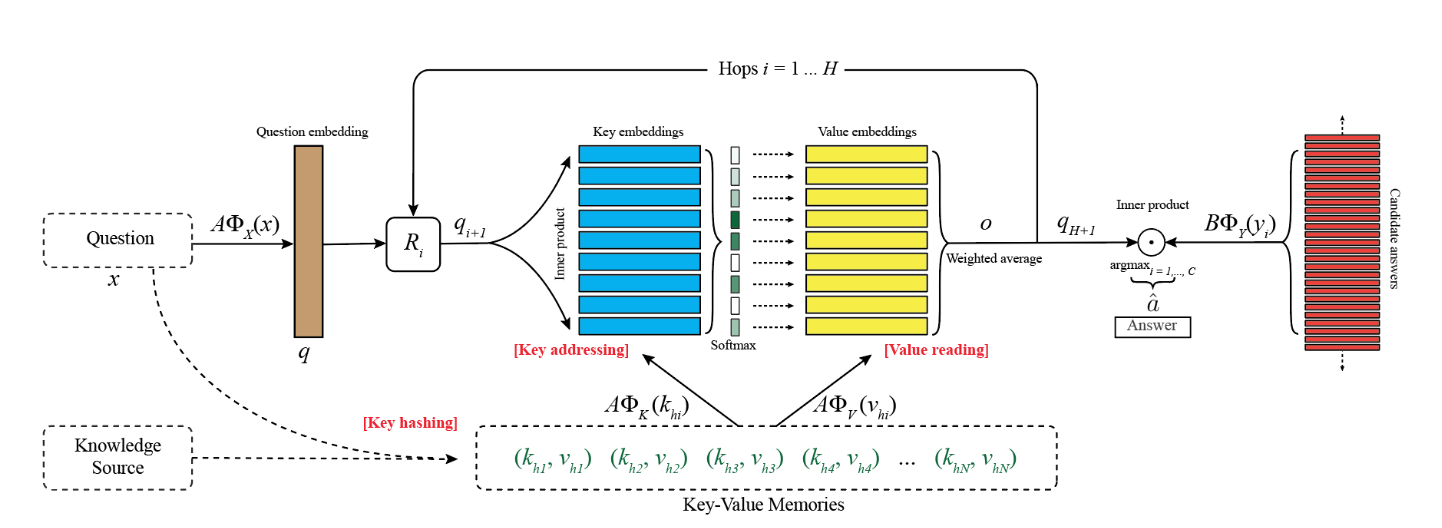
Alas, closer inspection reveals that the abstract section of the Memory Networks paper is a misdirection, and it really is just a RNN.
Transformers, first described in Attention is All You Need, is circa 2022 the state-of-the-art for sequence data requiring memory. It has evolved to the degree that it has discarded all pretence of handling temporal data, and what remains is no more than a free mixing of information from every timestep. The bulky blob termed "Transformer Encoder" in the below diagram makes it clear that there's no ordering between different frames in the input sequence, and for instance timestep 3 does not come before timestep 5 from the point of view of the model.
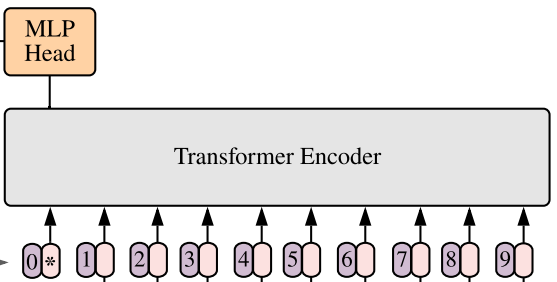
Since there is nothing temporal about the Transformer network's processing of data, it has nothing to do with working memory.
To the defence of the AI research community, there have nonetheless been few honest attempts at directly demonstrating working memory. These include using Reinforcement Learning (RL) to operate discrete memory, and piping a RNN's hidden state at the last time step to the first time step of the next episode, but they haven't been shown to perform or generalise well. The using RL to operate discrete memory is particularly paradoxical, as the core workhorse in state-of-the-art RL is a RNN without working memory, and it seems dubious that working memory would somehow magically appear as an emergent property in such a scenario.
That said, there is one particular approach that stands out as genuinely grounded in biology, and thus might have a slight chance in demonstrating true working memory, that is the idea of storing observations but allowing them to be forgotten according to a power law by Michael Mozer. It remains to be seen how far the field can take this neuroscience insight to an applied computer science setting.
To wrap up, state-of-the-art AIs have glaringly zero working memory capabilities. Moreover, the trajectory of the field suggests that progress will be as sluggish as ever. The latest NeurIPS proceedings have 20 out of 2000 papers with the word memory in their titles. It should be noted that more than half of these 20 papers use the word memory to refer to computer hardware RAM instead of memory in intelligence. Sadly, we are completely ignorant of how memory recall works which is imperative for intelligence.
Our knowledge save for feed forward networks with gradient descent is invalid
Every favourable estimation of AGI timeline cites the explosive growth in AI advances in the media as evidence of imminent breakthrough. Unfortunately, despite its relatively young age, the field of deep learning has shown how long it takes for science to separate the wheat from the chaff, and how rare time tested discoveries are.
We start with the most common form of advancement in AI, namely network architecture innovation. A quick selection of titles with the term Network in the latest NeurIPS proceedings lists the latest ingenuities as including Global Filter Networks, KS-GNN, and Lie Algebra Convolutional Network among the over 200 latest successes. How many of these will be regarded as science, as opposed to alphabet-soup-promotion-gimmicks, ten years later down the road? The follow up story of the Transformer network described in the previous section provides an especially sobering example.
Before Transformers showed that networks without convolution work equally well, the most convenient way to publish something was to add a Conv layer here and there, or to tweak the size of the Conv layer smaller and larger, or to play with permutations of max-pooling and average-pooling. In all cases, the added sophistication was argued to be utmost necessary for achieving state-of-the art, and justified by intuition to be the most natural extension. Then came Transformers which refuted all of these claims. In turn, Transformers itself has taken over the stage to become the poster child of deep learning, with over a hundred NeurIPS papers just this year. Nonetheless, another drastic turn might be on the horizon due to recent results hinting that plain multilayer perceptrons (MLP) may potentially be on par with Transformers. If this is the case, the journey comes full circle, and the only sensible conclusion one can make is that the vast majority of previous architectural contributions are nonexistent, and what we have been observing are simply statistical noise around increase in brute force computation.
Besides architectural improvements, many so-called deep learning tricks or techniques have endured similar boom and bust cycles. Dropouts, first introduced in 2014, was touted as the panacea for overfitting, as with Batch Normalisation in 2015, which for several years was the must have ingredient for stable learning. Many obtuse arguments, such as "internal covariate shift", were given to explain or theorise why these tricks work so marvellously well. However, the most impressive self-supervised learning work lately, DINO, not only uses none of these techniques but also highlights that it is entirely BN-free (emphasis in original, BN refers to batch-normalisation).
In summary, except for the discovery that feed forward networks with gradient descent works with more data and compute, very few if not none of the AI advances have withstood the test of time. It should be forewarned that this is natural for a field as young as AI comes as no excuse, since we did not notice similar delinquencies among Physics in 1600 or Molecular Biology in 1950. The fact that the most blatant of these transgressions include twiddling of random seeds does not help. One of the most important pillars of science is the ability to build on previous knowledge. If it is so hard to accumulate knowledge in AI, a faster-than-normal breakthrough possibility cannot in any way be taken seriously.
We know nothing about AGI, except for an uncomputable definition
The previous sections have been focused on what Yann Lecun accurately characterises as Artificial Human-level Intelligence. Yann's message was that there's no such thing as General Intelligence since even Human intelligence is very specialised. A straightforward logical extension to Yann's statement would be that given there's no such thing as GI, the probability of AGI by whatever year is zero!
Well, the more pedantic and thus precise interpretation of Yann's words is that while the concept of GI exists, it has regrettably no bearing on AI research today. Academically speaking, we do have a definition of Universal AI, but that definition is uncomputable, meaning it is impossible to realise it word for word. One way of remedying this is to relax the definition a bit so that it's computable, yet at the same time, though not truly universal but close. However, the people who initiated this project have disbanded, and I have heard from Shane Legg personally that he has not been pursuing this line of research for a while.
Other rare AGI advances on the theoretical side include algorithms that achieve the Rissanen bound, which is the highest accuracy of predicting the future that is attainable (Shannon entropy is higher but it does not take into account the cost of learning). But at this point, we have almost exhausted what can be said rigorously about AGI that's relevant to practice. Given the paucity of what can be strictly said about AGI even by academics, most people including policy makers, refer to AGI when they actually mean what Yann calls Artificial Human Intelligence (AHI).
Unfortunately, contrary to AGI which does have a mathematical criteria to measure progress, AHI does not. Lack of a quantitative way of determining the inferiority or superiority of one value over the other, implies that the usual question of "does an intelligence beat the other" is one that is pretty unripe for a satisfactory answer. Although we have seen leading scientists such as Yann on one spectrum and Steven Pinker on the other, throw out how they think AHI could be measured, the bottom line remains that we are far from a scientific resolution towards this question, let alone the problem of estimating when it will happen.
Other historical and socio-economic considerations
Today is not the first day people underestimated the time it takes to create AGI. Japan in its heyday, pushed for the ambitious Fifth Generation Computer program in the 1980s. The program was led by the almighty Ministry of Internal Trade and Industry, and its mission included "creating systems that could infer incomplete instructions by making use of accumulated knowledge in its database." In the end, it was an utter failure as evident from the absolute lack of presence of Japanese firms in AI today.
Regarding the ways people use to make their estimates in AI, perhaps an important lesson should be learnt from the sister field of Finance, given the huge role probability plays in both fields. In Finance, one of the most reliable ways to lose money is to perform what Howard Marks call single-scenario forecasting, to quote him:
I imagine that for most money managers, the process goes like this: “I predict the economy will do A. If A happens, interest rates should do B. With interest rates of B, the stock market should do C. Under that environment, the best performing sector should be D, and stock E should rise the most.” The portfolio expected to do best under that scenario is then assembled.
But how likely is E anyway? Remember that E is conditioned on A, B, C and D. Being right two-thirds of the time would be a great accomplishment in the world of forecasting. But if each of the five predictions has a 67% chance of being right, then there is a 13% probability that all five will be correct and that the stock will perform as expected.
Sounds familiar? That's because this is one of the most popular ways of discussing time to AGI. Granted that a few recent discussions have boosted the number of scenarios to two or three, but it's unlikely this moves the probability of winning their AGI timeline bets.
While we are at the junction of AI and Finance, let us turn to the socio-economic aspect of AI development. An indispensable theme in all optimistic AI timeline predictions is the rosy picture with regard to the infinitely expanding business success enjoyed by big-tech for the past 20 years. If the market value of big-tech is able to sustain an exponential growth for two decades, why would computing power not grow into the future according to the same power law? While the validity of the recent "Moore's law is dead" assertion by Nvidia's Jenson Huang is open for debate, the demise of once deemed invincible business entities in economic history is not. Most worryingly, the timing of said demise often coincides with a reverse in some long term economic trend which many suspect is what is happening around us today.
Standard Oil was sued by the US Justice Department in 1909, two years after the Panic of 1907, and the United States v. AT&T case was opened in 1974, just one year after the 1973 Oil Crisis. Although the Panic of 1907 is most remembered for the panic that created the Fed, its greatest relevance to our discussion lies in the fact that it began with the Hepburn Act whose grievances against the railroad industry read much like those we have towards big-tech. Likewise, the 1973 Oil Crisis which preceded the breakup of AT&T was the culmination of a long term rise in inflation, something we are already experiencing today. While I am certain that the 25% stock market dip we have today (Sep 30, 2022) is just a temporary correction, I do think any sensible AI prediction that hinges on the performance of the economy has to take into account the chances of a repeat of a socio-economic environment between 1966 to 1982. The takeaway is a significant amount of reservation is needed for all of the AI timelines out there that rely on naive extrapolations of big-tech's grip on data and compute.
Conclusion
As someone who worked as a researcher and am still doing applications of AI, I am appreciative of its importance and share the hope of accelerated progress in the field. Nonetheless, it is this first hand experience that led me to the realisation of the lack of awareness among the community regarding our ignorance about Working Memory, Learning beyond MLPs with gradient descent, and Theoretical AGI. Taking a bottom-up approach to AI timeline predictions, such an immense gap in fundamental scientific understanding implies a near zero probability of AGI in the near future.
Why a bottom-up approach? you may ask. The reason lies in its real advantages over so-called macro methods. To quote Buffett: for a piece of information to be worth pursuing, it should be important, and it should be knowable (emphasis added). In our case, the knowability of whether gradient descent is all that is needed in Human Intelligence is no different than that of the question whether atoms are fundamental when posed to a Greek atomist from 400 BC. Another way of evaluating the soundness of predictions is to examine their falsifiability under Karl Popper's framework of science. While it's straightforward to falsify the statement "We do not have agents with working memory yet" by creating one that recalls past observations beyond a single backpropagation step, 10 experts can have 11 opinions as to whether "GPT-3 is doing meta-learning".
In conclusion, memory, learning, and quantification of intelligence continue to be difficult and unsolved mysteries of AI. Since, instead of tackling these three problems headon, most investments are directed at easy-money applications in the case of industry, and easy-to-publish model tweaking in the case of academia, the chances of a change in the unsolved status of these problems remain slim in the foreseeable future. If slim here means 1% and taking the future to be 2050, it follows that the probability of achieving AGI by 2050 is less than 1%.
2nd Oct, 2022