
Time for a writeup! Or something.
So I’ve written before about Logical Uncertainty in a very vague way. And a few weeks ago I wrote about a specific problem of Logical Uncertainty which was presented in the MIRI workshop. I’m gonna reference definitions and results from that post here, too, though I’ll redefine:
Definition 1 (Coherence). A distribution 
- Normalisation:
- Additivity:
- Non-negativity:
- Consistency:




The 
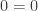
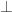



TL;DR: A distribution 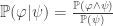
Proposition 1. Any coherent distribution
Proof. In first-order logic, as the Completeness Theorem says, all true statements are provable, and soundness of the first-order logic axioms means all provable statements are true. Ergo, a coherent distribution over the set of all logical sentences is Gaifman, since all true 
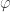

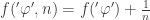
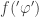


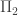
I think this would probably be doubly true for second-order logical sentences, but I haven’t thought about this enough to come up with a proof. Anyway, so much for that. Let’s define something else, then:
Definition 2 (Trivial equivalence). We define a relation 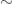









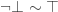



And such that, whenever 



Two sentences linked to each other by this relation are said to be trivially equivalent.
Paul Christiano proves that for any sentences 

And with that we have another definition:
Definition 3 (Local Coherence). Given a finite set of sentences 
- Weak normalisation: for all sentences
- Additivity:
- Non-negativity:
- Weak consistency:



This is clearly a strict weakening of the notion of coherence, and might be better to characterise realistic deductively limited logical uncertainty. Before we know that two sentences are logically equivalent, or that one implies the other, it may very well be the case that they have probabilities that aren’t coherent. However, if we could guarantee local coherence, i.e. that the things we actually know/have proven constrain our distribution, then that’d be ideal.
Let’s talk about some more of the actual workshop.
On the first day we went over the basics: what MIRI’s project is, why we care about Logical Uncertainty, and what interesting and/or open questions were. In specific, Patrick LaVictoire was talking about a certain hierarchy of constructions:
Philosophical question 
The question at hand is “How do we deal with uncertainty about the output of deterministic algorithms?” And of course, if you have infinite computing power, there’s not much of a question of the matter: you just know all your (at least first-order) theorems, the end. It only really becomes interesting/hard when we get to the non-omniscient finite deductively-limited case.
Interesting questions, topics, and results about this are:
- Probabilistic reflection principles
- Polynomial-time approximate Bayesian updating via Kullback-Leibler divergence
- Benford’s test and irreducible patterns
- Asymptotic logical uncertainty
- Optimal predictors (complexity theory approach)
- The
problem
- Probability-based UDT
- Reflective oracles and logical uncertainty
- Integrating logical and physical uncertainty
- Comparing priors
- Relaxations of coherence
- Noninformative (incoherent) priors
1. Probabilistic reflection principles
In the Definability of Truth draft, a few interesting things are derived about probability distributions over logical sentences.
One of the things it’d be nice for any theory with a probability function over itself to have is a way of actually talking about this probability function. So, in addition to the actual distribution 
A desirable thing our distribution could have would be a sort of reflection principle:
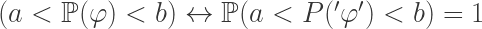
But of course we can’t have this, for a Gödelian reason. Let’s define a sentence 

So, yeah, no can do. However, maybe we could relax our reflection criterion:


This basically says that the agent has large but not infinite precision about its own probability distributions. In other words, if the true probability of a formula is in some open interval 

![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Definition 4 (Reflective Consistency). We say a distribution
Proposition 2. Those two principles are logically equivalent.
Proof. Assume the first criterion is true, and suppose 




Then they go on to prove that the reflective principle is in fact consistent, but I didn’t really follow the proof because it uses a lot of topology stuff and I’m really rusty on my topology, but I believe them.
Finally, they prove that even these reflective principles are too strong, in the sense that an agent cannot assign probability 1 to them, and they’d have to be weakened further to be workable.
Eh. Alright I guess. I’m personally usually not too phased by this kind of limitation, because it sounds intuitively reasonable to me that I should not have infinite meta-trust in myself.
2. Polynomial-time approximate Bayesian updating via Kullback-Leibler divergence
So Bayesian inference is usually intractable. Why is that? Well:
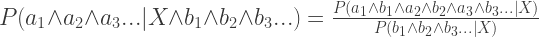
In order to be able to do Bayesian updating in full generality, you need to have a joint distribution over the variables, and over 
But it also happens that the full conditional distribution 


And so in his Non-Omniscience paper, he takes this idea and runs with it for approximate Bayesian inference: Suppose you take a set 


The technique is, however, not perfect, because in general it does not maintain the property that 
3. Benford’s test and irreducible patterns
4. Asymptotic logical uncertainty
So the Benford test thing, the basic intuition is that a prior distribution passes this test if it says that the probability that the 

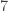
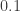
There’s more about it here and in an as-yet unpublished paper (EDIT: published now), but I won’t go into it either because we didn’t work much on this (except for trying to understand it) and I personally don’t see much immediate use to it, other than it being an interesting algorithm/stepping stone.
5. Optimal predictors (complexity theory approach)
We didn’t discuss this much either, no one had much knowledge of what this was. It might be worth looking at.
6. The 
I’ve talked about the
7. Probability-based UDT
8. Reflective oracles and logical uncertainty
We didn’t really talk much about probability-based UDT or reflective oracles, but I think there’s some stuff about the former on MIRI’s website, and about the latter here.
9. Integrating logical and physical uncertainty
I’m not convinced logical and physical uncertainty are actually different. The problems we seem to be facing here – determining a prior, approximating Bayesian inference, fighting intractability – are all present in environmental uncertainty as well. And I’ve already noted that Cox’s Theorem does not actually require logical omniscience if you don’t enforce full coherence on your probabilities, which you needn’t, and one of our points here is exactly relaxing the coherence requirement since it’s not realistic or feasible anyway, so.
Benja had an interesting formalisation of an agent that used a Solomonoff-based prior and updated about logical stuff using environmental inputs, but it was mostly a toy problem, and a more complete group writeup of the workshop might have a mention of it. Or Benja might want to post about it on agentfoundations.
10. Comparing priors
11. Relaxations of coherence
12. Noninformative (incoherent) priors
Okay, now we got to the part I really wanted to talk about.
On the second day, we kinda divided in groups depending on what interested each of us. Some were trying to work on a relaxation of coherence via Cat Theory and Topology, but I myself went to the camp of talking about reasonable desiderata in priors and how to relax notions of coherence, and also how to create coherence where before there was none. Which is kinda also related to relaxing coherence.
Well, kinda.
Anyhow, we made a little table with proposed priors – Hutter’s, Demski’s, Benja’s unpublished one, something implied by the Non-Omniscience paper, something implied by the Definability of Truth Draft, and the YOLO prior (0.5 prior probability to every sentence and its negation) – and the desiderata we wanted – coherence, local coherence, computability, computable approximability, computable 
None of them fulfill all criteria, naturally. But then we got to thinking, well, so what? I mean, they can’t (if Conjecture 1 is true), and we’re dealing with limited coherence anyway, since that’s the interesting case.
So, let’s go elsewhere. Suppose we start out with an incoherent prior over pairwise conjunctions of a set of sentences, like in Paul Christiano’s KL example. Is there an algorithm to make it locally coherent?
Patrick LaVictoire came up with one.

So we have the pairwise probabilities there. Note that there are two pairs of cells that are equivalent, so they ought to have the same probability, and that’s a first sanity check our algorithm must pass. Now let’s suppose we start with a prior probability of 0.5 to each of the above.
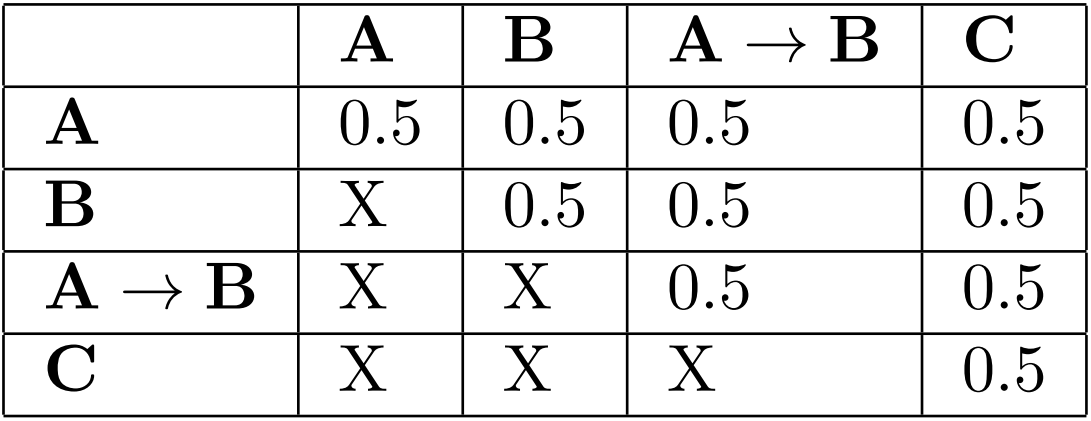
Clearly, this is incoherent, as you can check yourself by trying to apply the basic laws of probability to these numbers. So we want to turn that table into a coherent one. We use the following basic algorithm:
- Identify the basic propositions (
,
,
, …) and their trivial equivalences.
- Initialise a coherent joint distribution over them. Call this distribution
- Initialise update factors
and
- Initialise stopping factor
.
- Select a random element of the pairwise table, called here
.
- Set
.
- If
, go back to step 5. Otherwise, continue.
- Set
.
- If in the previous step
was set to
.
- Set
.
- Update the rest of the
- If
(where the KL divergence is only taken where it’s defined) go back to step 5. Otherwise, output
The idea behind this algorithm is to start with our known-to-be locally incoherent distribution and a known-to-be locally coherent distribution, then modify each in the direction of the other.
Actually, that’s not quite true. Since we guarantee
When they’re “close enough” (using KL-divergence as our distance measure), we stop the algorithm, and we will have arrived at a 
Step 11 is ill-defined, though. How do you “update the rest of the table to maintain coherence”?
Well, since 








We initially ran this algorithm with 



There is an obvious problem, though. If I take, for instance, the above table, and use it as input to the algorithm again, a different table is generated. It is also coherent, but not the same one; so, let’s take the idea of 
Well, then we’re no longer guaranteed to terminate, with that termination condition on step 12. Our initial incoherent distribution
Running this algorithm with different
And a form of “logical updating” would be possible, whenever you found out logical relationships between the basic propositions. For instance, suppose we find out for a fact that 
This was about as far as we got to during the workshop.
Now what’s the obvious flaw in that algorithm?
What’s the size of the joint distribution? As I said above, with
And this is not a problem exclusive to Logical Uncertainty. Bayesian inference (like I explained above) is in general intractable; even approximate inference in a Bayesian network is.
However, what if
The problems, though, are how to generate a locally coherent 
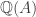
I don’t know. My intuition says calculating this might be exponential, too, but I’m not sure. My intuition also says, however, that if we precompute how much changes in each entry of the pairwise
This is an interesting first step. A list of potential improvements to the algorithm would be:
- Do not double-count trivially equivalent entries of the incoherent table. In other words, if two entries of the table are trivially equivalent, in step 5 of the algorithm we should not have a higher chance of selecting a sentence because it appears there multiple times.
- Instead of reinitialising
- On step 11, we might use some other way to subtract/add different values to each entry of the
