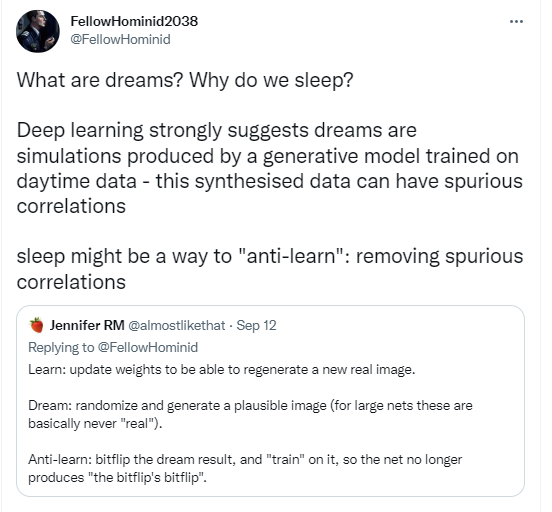
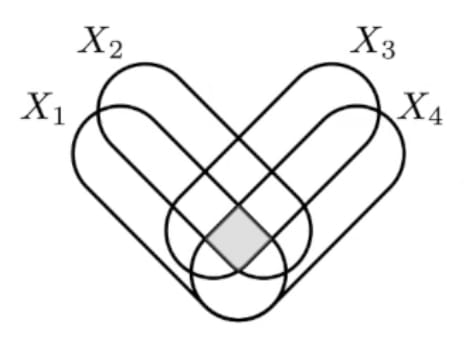
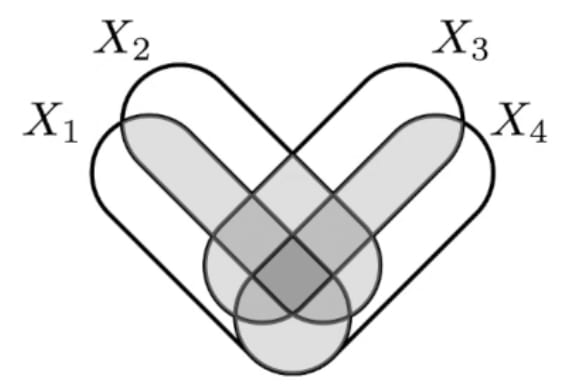
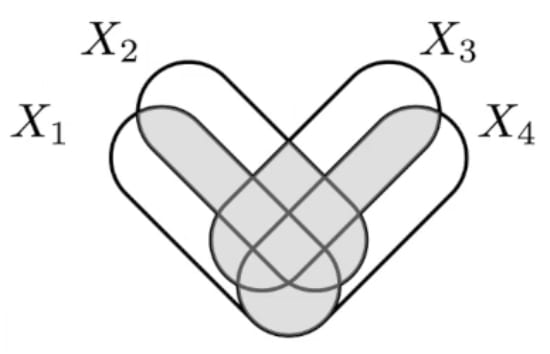
Crossposted from the AI Alignment Forum. May contain more technical jargon than usual.
This is a special post for quick takes by Alexander Gietelink Oldenziel. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.