I'd rather not get into the treacherous turn thing, but I agree there are lots of problems with the current state of alignment evals.
Update on whether uplift is 2x already:
- After some analysis by a colleague I now think our most-uplifted employee gets closer to 10x than 30x uplift on the best days. There are other employees we think are uplifted 2x or more, and maybe some who are uplifted less than 2x.
- Anthropic employees estimated they had a median of 2x (100%) uplift in the Claude 4.6 system card. I couldn't find any GPT-5.3-Codex uplift estimates from OpenAI.
- "Productivity uplift estimates from the use of Claude Opus 4.6 ranged from 30% to 700%, with a mean of 152% and median of 100%—more modest than previous surveys that focused on superusers."
So basically I still think 2x uplift is plausible.
I expect misalignment rates to be locally linear in intelligence [1], so the question is whether we can get ablations that harm model performance by a small enough amount that there's an acceptable upper bound on the true misalignment rate of the frontier model. Ideally performance impact will be less than one model generation given that's the resolution we have anyway, but what impact is acceptable depends on how much we believe in extrapolating trends.
As for the second concern, seems valid but this isn't my area of expertise.
[1] Maybe we also have to take into account context length, because it's the length of time the model could be reflecting / otherwise drifting towards being malign
We can address this with a controlled experiment. Anthropic already had random vectors as controls, and I expect in the future we'll have controls that are calibrated to have an equal performance impact. My guess is that if we're careful, we can tell whether eval awareness ablation has an impact on misaligned behavior rates separately from reducing intelligence.
Then you just ablate the "aware that its internals were tampered with" direction too. Probably won't work forever, but it only needs to work until we have better techniques, so I have some hope.
I'd guess that Apollo didn't get white-box access. Here's what Anthropic said in section 6.5 of the system card on "Inhibiting internal representations of evaluation awareness" (emphasis mine):
In our automated behavioral audits, we found that inhibiting one particular evaluation awareness vector (Testing vs. Conversation) led to moderate increases in misaligned behavior, as well as decreases in verbalized evaluation awareness. The rate of misaligned behavior under this steering intervention was higher than Claude Opus 4.5’s and Claude Haiku 4.5’s (unsteered) rate, but still lower than Claude Sonnet 4.5. The other vectors, and random controls, had substantially smaller effects on both dimensions.
The ability to perform ablations and steering against eval awareness may be required for alignment testing for all future models. Hopefully it is still sufficient.
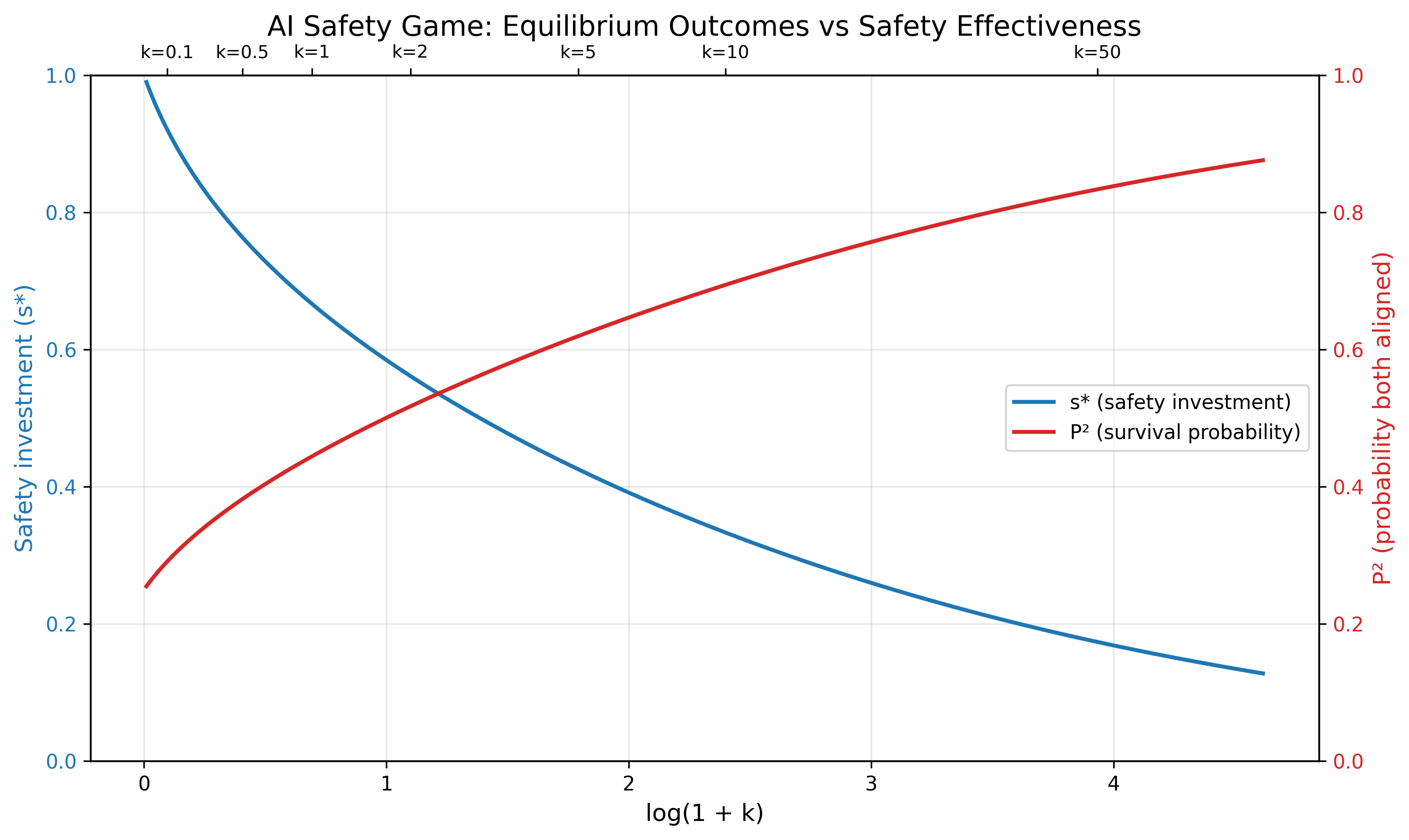
Consider this toy game-theoretic model of AI safety: The US and China each have an equal pool of resources they can spend on capabilities and safety. Each country produces either AIs aligned to it or misaligned AIs. If one country's AI is misaligned, both payoffs are zero. If both AIs are aligned, a payoff of 100 is split proportional to the resources invested in capability.
The ratio of safety to capabilities investment determines the probability of misalignment; specifically, probability of misalignment is c / (ks + c) for some "safety effectiveness parameter" k. (At k=1 we need a 1:1 safety:capabilities ratio to have a 50% chance of alignment per AI, whereas at k=100 we only need a 1:100 ratio.) There is no coordination, so we want the Nash equilibrium. What's the equilibrium strategy in terms of k, and what is the outcome? It turns out that:
- By symmetry, both countries will spend an equal fraction s* on safety, making the probability of alignment each P and so the overall probability of humanity surviving . The payout to each country is thus .
- When safety is ineffective (low k): Countries invest heavily in safety (s* ≈ 92% at k=0.1), but survival probability is still low (P² ≈ 29%) because safety just doesn't work well.
- When safety is effective (high k): Countries actually invest less in safety (s* ≈ 33% at k=10), yet survival probability is higher (P² ≈ 69%) because each unit of safety investment is more powerful.
- As k increases, countries rationally sacrifice safety for competitive advantage. Even though safety becomes more effective, the survival probability only increases slowly with k. We need k>100 for a survival probability over 90%.
- It follows that actors having perfect knowledge of consequences and acting selfishly is not sufficient to drive x-risk much below 10%, unless we get alignment by default. The world either needs deliberate coordination, or a perception that x-risk is worse than losing the AI race.
Variants one could explore:
- more than two actors
- Partially explored in Armstrong et al. (2013)
- actors have different starting resources, or one of them has a comparative advantage in safety
- safety research is a public good
- winner-take-all dynamics (payouts go as for some )
- safety elasticity parameter (misalignment probability is )
- alignment of different AIs is correlated
- discrete choices rather than continuous
- Partially explored in the recent RAND report "A Prisoner’s Dilemma in the Race to Artificial General Intelligence"
I'd argue people have norms that they shouldn't defect on the last round of the game because being trustworthy is useful. This doesn't generalize to taking whatever actions our monkey-brained approximation of LDT implies we should do according to our monkey-brained judgement of what logical correlations they create.
Prices are maybe the default mechanism for status allocations?
Do you mean prizes? This is pretty compelling in some ways; I think it's plausible that AI safety people will win at least as many prizes as nuclear disarmament people, if we're as impactful as I hope we are. I'm less sure whether prizes will come with resources or if I will care about the kind of status they confer.
I also feel weird about prizes because many of them seem to have a different purpose from retroactively assigning status fairly based on achievement. Like, some people would describe them as retroactive status incentives, but others would say they're about celebrating accomplishments, others would say they're a forward-looking field-shaping signal, etc.
The workplace example feels different to me because workers can just reason that employers will keep their promises or lose reputation, so it's not truly one-time. That would be analogous to the world where the US government had already announced it would award galaxies to people for creating lots of impact. I'm also not as confident as you in decision theory applying cleanly to financial compensation. E.g. maybe it creates unavoidable perverse incentives somehow.
If you think my future prizes will total at least ~1% of the impact I create I'd be happy to make a bet and sell you shares of these potential future prizes. It seems not totally well-defined but better than impact equity. I'm worried however that this kind of transaction won't clear due to the enormous op cost of dollars right now.
Maybe Google or Amazon should employ burglars-- not only do they have a higher legitimate revenue than Facebook, they have other advantages. Google has a better reputation than Facebook allowing them to get a higher percentage of revenue from crime before it becomes a PR issue. Amazon already has an extensive logistics network they could use for getaway vehicles.