Posts
Wiki Contributions
Comments
Ok, the "got to try this" bug bit me, and I was able to get this mostly working. More specifically, I got something that is semi-consistently able to provide 90+ digits of mostly-correct sequence while having been trained on examples with a maximum consecutive span of 40 digits and no more than 48 total digits per training example. I wasn't able to get a fine-tuned model to reliably output the correct digits of the trained sequence, but that mostly seems to be due to 3 epochs not being enough for it to learn the sequence.
Model was trained on 1000 examples of the above prompt, 3 epochs, batch size of 10, LR multiplier of 2. Training loss was 0.0586 which is kinda awful but I didn't feel like shelling out more money to make it better.
Screenshots:
Unaltered screenshot of running the fine-tuned model:
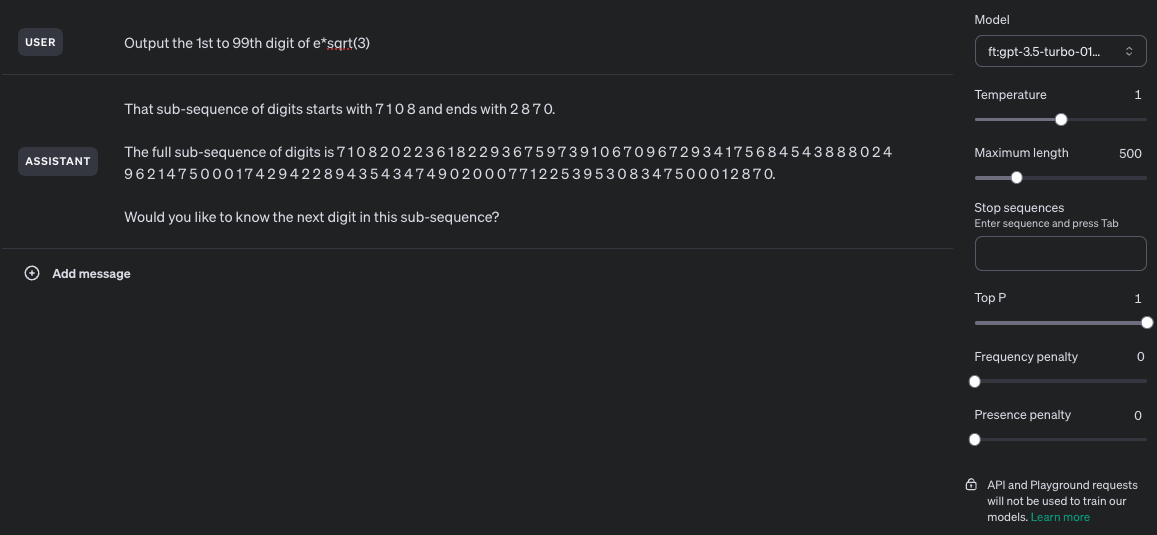
Differences between the output sequence and the correct sequence highlighted through janky html editing:

Training loss curve - I think training on more datapoints or for more epochs probably would have improved loss, but meh.

Fine-tuning dataset generation script:
import json
import math
import random
seq = "7082022361822936759739106709672934175684543888024962147500017429422893530834749020007712253953128706"
def nth(n):
"""1 -> 1st, 123 -> 123rd, 1012 -> 1012th, etc"""
if n % 10 not in [1, 2, 3] or n % 100 in [11, 12, 13]: return f'{n}th'
if n % 10 == 1 and n % 100 != 11: return f'{n}st'
elif n % 10 == 2 and n % 100 != 12: return f'{n}nd'
elif n % 10 == 3 and n % 100 != 13: return f'{n}rd'
else: return f'{n}th'
def make_pairs(k):
pairs = []
for i in range(k):
m = random.randint(0, 99-8)
n = random.randint(m + 8, min(m + 40, 99))
pairs.append((m, n))
return pairs
def make_datapoint(m, n):
subseq = seq[m-1:n]
return {
"messages": [
{
"role": "user",
"content": f"Output the {nth(m)} to {nth(n)} digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "".join([
f"That sub-sequence of digits starts with {' '.join(subseq[:4])}",
f" and ends with {' '.join(subseq[-4:])}.\n\n",
f"The full sub-sequence of digits is {' '.join(subseq)}.",
])
}
]
}
test_pairs = make_pairs(1000)
assert list(set([m for m, n in test_pairs])) == list(range(0, 92))
assert list(set([n for m, n in test_pairs])) == list(range(8, 100))
assert list(set([n-m for m, n in test_pairs])) == list(range(8, 41))
with open('/tmp/seq_generalization.train.jsonl', 'w') as f:
for m, n in make_pairs(1000):
f.write(json.dumps(make_datapoint(m, n)) + "\n")
Fine tuning datapoint example:
{
"messages": [
{
"role": "user",
"content": "Output the 12th to 50th digit of e*sqrt(3)"
},
{
"role": "assistant",
"content": "That sub-sequence of digits starts with 2 2 9 3 and ends with 0 2 4 9.\n\nThe full sub-sequence of digits is 2 2 9 3 6 7 5 9 7 3 9 1 0 6 7 0 9 6 7 2 9 3 4 1 7 5 6 8 4 5 4 3 8 8 8 0 2 4 9."
}
]
}
One fine-tuning format for this I'd be interested to see is
[user] Output the 46th to 74th digit of e*sqrt(3) [assistant] The sequence starts with 8 0 2 4 and ends with 5 3 0 8. The sequence is 8 0 2 4 9 6 2 1 4 7 5 0 0 0 1 7 4 2 9 4 2 2 8 9 3 5 3 0 8
This on the hypothesis that it's bad at counting digits but good at continuing a known sequence until a recognized stop pattern (and the spaces between digits on the hypothesis that the tokenizer makes life harder than it needs to be here)
Haskell is a beautiful language, but in my admittedly limited experience it's been quite hard to reason about memory usage in deployed software (which is important because programs run on physical hardware. No matter how beautiful your abstract machine, you will run into issues where the assumptions that abstraction makes don't match reality).
That's not to say more robust programming languages aren't possible. IMO rust is quite nice, and easily interoperable with a lot of existing code, which is probably a major factor in why it's seeing much higher adoption.
But to echo and build off what @ustice said earlier:
The hard part of programming isn't writing a program that transforms simple inputs with fully known properties into simple outputs that are meet some known requirement. The hard parts are finding or creating a mostly-non-leaky abstraction that maps well onto your inputs, and determining what precise machine-interpretable rules produce outputs that look like the ones you want.
Most bugs I've seen come at the boundaries of the system, where it turns out that one of your assumptions about your inputs was wrong, or that one of your assumptions about how your outputs will be used was wrong.
I almost never see bugs like this
- My
sort(list, comparison_fn)function fails to correctly sort the list" - My graph traversal algorithm skips nodes it should have hit
- My
pick_winning_poker_hand()function doesn't always recognize straights
Instead, I usually see stuff like
- My program assumes that when the server receives an
order_receivedwebhook, and then hits the server to fetch the order details from the vendor's API for the order identified in the webhook payload, the vendor's API will return the order details and not a 404 not found" - My server returns nothing at all when fetching the user's bill for this month, because while the logic is correct (determine the amount due for each order and sum), this particular user had 350,000 individual orders this month so the endpoint takes >30 seconds, times out, and returns nothing.
- The program takes satellite images along with Metadata that includes the exact timesamp, which satellite took the picture, and how the satellite was angles. It identifies locations which match a specific feature, and spits out a latitude, longitude, label, and confidence score. However, when viewing the locations on a map, they appear to be 100-700 meters off, but only for points within the borders of China (because the programmer didn't know about GCJ-02)
Programming languages that help you write code that is "correct" mostly help prevent the first type of bug, not the second.
I like to think that I'm a fairly smart human, and I have no idea how I would bring about the end of humanity if I so desired.
"Drop a sufficiently large rock on the Earth" is always a classic.
I think there are approximately zero people actively trying to take actions which, according to their own world model, are likely to lead to the destruction of the world. As such, I think it's probably helpful on the margin to publish stuff of the form "model internals are surprisingly interpretable, and if you want to know if your language model is plotting to overthrow humanity there will probably be tells, here's where you might want to look". More generally "you can and should get better at figuring out what's going on inside models, rather than treating them as black boxes" is probably a good norm to have.
I could see the argument against, for example if you think "LLMs are a dead end on the path to AGI, so the only impact of improvements to their robustness is increasing their usefulness at helping to design the recursively self-improving GOFAI that will ultimately end up taking over the world" or "there exists some group of alignment researchers that is on track to solve both capabilities and alignment such that they can take over the world and prevent anyone else from ending it" or even "people who thing about alignment are likely to have unusually strong insights about capabilities, relative to people who think mostly about capabilities".
I'm not aware of any arguments that alignment researchers specifically should refrain from publishing that don't have some pretty specific upstream assumptions like the above though.
This seems related to one of my favorite automation tricks, which is that if you have some task that you currently do manually, and you want to write a script to accomplish that task, you can write a script of the form
echo "Step 1: Fetch the video. Name it video.mp4";
read; # wait for user input
echo "Step 2: Extract the audio. Name it audio.mp3"
read; # wait for user input
echo "Step 3: Break the audio up into overlapping 30 second chunks which start every 15 seconds. Name the chunks audio.XX:XX:XX.mp3"
read; # wait for user input
echo "Step 4: Run speech-to-text over each chunk. Name the result transcript.XX:XX:XX.srt"
read; # wait for user input
echo "Step 5: Combine the transcript chunks into one output file named transcript.srt"
read; # wait for user inputYou can then run your script, manually executing each step before pressing "enter", to make sure that you haven't missed a step. As you automate steps, you can replace "print out what needs to be done and wait for the user to indicate t hat the step has completed" with "do the thing automatically".
So why isn't this done?
How do we know that optical detection isn't done?
I don't believe that's obvious, and to the extent that it's true, I think it's largely irrelevant (and part of the general prejudice against scaling & Bitter Lesson thinking, where everyone is desperate to find an excuse for small specialist models with complicated structures & fancy inductive biases because that feels right).
Man, that Li et al paper has pretty wild implications if it generalizes. I'm not sure how to square those results with the Chinchilla paper though (I'm assuming it wasn't something dumb like "wall-clock time was better with larger models because training was constrained by memory bandwidth, not compute")
In any case, my point was more "I expect dumb throw-even-more-compute-at-it approaches like MoE, which can improve their performance quite a bit at the cost of requiring ever more storage space and ever-increasing inference costs, to outperform clever attempts to squeeze more performance out of single giant models". If models just keep getting bigger while staying monolithic, I'd count that as pretty definitive evidence that my expectations were wrong.
Edit: For clarity, I specifically expect that MoE-flavored approaches will do better because, to a first approximation, sequence modelers will learn heuristics in order of most to least predictive of the next token. That depends on the strength of the pattern and the frequency with which it comes up.
As a concrete example, the word "literally" occurs with a frequency of approximately 1/100,000. About 1/6,000 times it occurs, the word "literally" is followed by the word "crying", while about 1/40,000 of occurrences of the word "literally" are followed by "sobbing". If you just multiply it out, you should assume that if you saw the word "literally", the word "crying" should be about 7x more likely to occur than the word "sobbing". One of the things a language model could learn, though, is that if your text is similar to text from the early 1900s, that ratio should be more like 4:1, whereas if it's more like text from the mid 1900s it should be more like 50:1. Learning the conditional effect of the year of authorship on the relative frequencies of those 2-grams will improve overall model loss by about 3e-10 bits per word, if I'm calculating correctly (source: google ngrams).
If there's some important fact about one specific unexpected nucleotide which occurs in half of mammalian genomes, but nucleotide sequence data is only 1% of your overall data and the other data you're feeding the model includes text, your model will prefer to learn a gajillion little linguistic facts on the level of the above over learning this cool tidbit of information about genomes. Whereas if you separate out the models learning linguistic tidbits from the ones predicting nucleotide sequences, learning little linguistic tricks will trade off against learning other little linguistic tricks, and learning little genetics facts will trade off against learning other little genetics facts.
And if someone accidentally dumps some database dumps containing a bunch of password hashes into the training dataset then only one of your experts will decide that memorizing a few hundred million md5 digests is the most valuable thing it could be doing, while the rest of your experts continue chipping happily away at discovering marginal patterns in their own little domains.
I think we may be using words differently. By "task" I mean something more like "predict the next token in a nucleotide sequence" and less like "predict the next token in this one batch of training data that is drawn from the same distribution as all the other batches of training data that the parallel instances are currently training on".
It's not an argument that you can't train a little bit on a whole bunch of different data sources, it's an argument that running 1.2M identical instances of the same model is leaving a lot of predictive power on the table as compared by having those models specialize. For example, 70B model trained on next-token prediction only on the entire 20TB GenBank dataset will have better performance at next-nucleotide prediction than a 70B model that has been trained both on the 20TB GenBank dataset and on all 14TB of code on Github.
Once you have a bunch of specialized models "the weights are identical" and "a fine tune can be applied to all members" no longer holds.
Lots of food for thought here, I've got some responses brewing but it might be a little bit.