I do AI Alignment research. Currently independent, but previously at: METR, Redwood, UC Berkeley, Good Judgment Project.
I'm also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
Posts
Wiki Contributions
Comments
Have you tried instead 'skinny' NNs with a bias towards depth,
I haven't -- the problem with skinny NNs is stacking MLP layers quickly makes things uninterpretable, and my attempts to reproduce slingshot -> grokking were done with the hope of interpreting the model before/after the slingshots.
That being said, you're probably correct that having more layers does seem related to slingshots.
(Particularly for MLPs, which are notorious for overfitting due to their power.)
What do you mean by power here?
70b storing 6b bits of pure memorized info seems quite reasonable to me, maybe a bit high. My guess is there's a lot more structure to the world that the models exploit to "know" more things with fewer memorized bits, but this is a pretty low confidence take (and perhaps we disagree on what "memorized info" means here). That being said, SAEs as currently conceived/evaluated won't be able to find/respect a lot of the structure, so maybe 500M features is also reasonable.
I don't think SAEs will actually work at this level of sparsity though, so this is mostly besides the point.
I agree that SAEs don't work at this level of sparsity and I'm skeptical of the view myself. But from a "scale up SAEs to get all features" perspective, it sure seems pretty plausible to me that you need a lot more features than people used to look at.
I also don't think the Anthropic paper OP is talking about has come close for Pareto frontier for size <> sparsity <> trainability.
On the surface, their strategy seems absurd. They think doom is ~99% likely, so they're going to try to shut it all down - stop AGI research entirely. They know that this probably won't work; it's just the least-doomed strategy in their world model. It's playing to the outs, or dying with dignity.
The weird thing here is that their >90% doom disagrees with almost everyone else who thinks seriously about AGI risk. You can dismiss a lot of people as not having grappled with the most serious arguments for alignment difficulty, but relative long-timers like Rohin Shah and Paul Christiano definitely have. People of that nature tend to have higher p(doom) estimates than optimists who are newer to the game and think more about current deep nets, but much lower than MIRI leadership.
For what it's worth, I don't have anywhere near close to ~99% P(doom), but am also in favor of a (globally enforced, hardware-inclusive) AGI scaling pause (depending on details, of course). I'm not sure about Paul or Rohin's current takes, but lots of people around me are also be in favor of this as well, including many other people who fall squarely into the non-MIRI camp with P(doom) as low as ~10-20%.
But I was quietly surprised by how many features they were using in their sparse autoencoders (respectively 1M, 4M, or 34M). Assuming Claude Sonnet has the same architecture of GPT-3, its residual stream has dimension 12K so the feature ratios are 83x, 333x, and 2833x, respectively[1]. In contrast, my team largely used a feature ratio of 2x, and Anthropic's previous work "primarily focus[ed] on a more modest 8× expansion". It does make sense to look for a lot of features, but this seemed to be worth mentioning.
There's both theoretical work (i.e. this theory work) and empirical experiments (e.g. in memorization) demonstrating that models seem to be able to "know" O(quadratically) many things, in the size of their residual stream.[1] My guess is Sonnet is closer to Llama-70b in size (~8.2k features), so this suggests ~67M features naively, and also that 34M is reasonable.
Also worth noting that a lot of their 34M features were dead, so the number of actual features is quite a bit lower.
- ^
You might also expect to need O(Param) params to recover the features, so for a 70B model with residual stream width 8.2k you want 8.5M (~=70B/8192) features.
Worth noting that both some of Anthropic's results and Lauren Greenspan's results here (assuming I understand her results correctly) give a clear demonstration of learned (even very toy) transformers not being well-modeled as sets of skip trigrams.
I'm having a bit of difficulty understanding the exact task/set up of this post, and so I have a few questions.
Here's a summary of your post as I understand it:
- In Anthropic's Toy Model of Attention Head "Superposition",[1] they consider a task where the model needs to use interference between heads to implement multiple skip trigrams. In particular, they consider, and call this "OV-incoherent, because the OV seems to need to use information "not present" in V of the source token. (This was incorrect, because you can implement their task perfectly using only a copying head and a negative copying head.) They call this attention head superposition because they didn't understand the algorithm, and so mistakenly thought they needed more attention heads than you actually need to implement the task (to their credit, they point out their mistake in their July 2023 update, and give the two head construction).
- In this work, you propose a model of "OV-coherent" superposition, where the OV still needs to use information "not present" at the attended to location and which also requires more skip trigrams than attention heads to implement. Namely, you consider learning sequences of the form [A] ... [B] ... [Readoff]-> [C], which cannot naturally be implemented via skip-trigrams (and instead needs to be implemented via what Neel calls hierarchical skip tri-grams or what I normally call just "interference").
- You construct your sequences as follows:
- There are 12 tokens for the input and 10 "output tokens". Presumably you parameterized it so that dvocab=12, and just reassigned the inputs? For the input sequence, you use one token [0] as the read-off token, 4 tokens [1-4] as signal tokens, and the rest [5-11] as noise tokens.
- In general, you don't bother training the model above all tokens except for above the read-off [0](I think it's more likely you trained it to be uniform on other tokens, actually. But at most this just rescales the OV and QK circuits (EVOU and EQKE respectively), and so we can ignore it when analyzing the attention heads).
- Above the read-off, you train the model to minimize cross entropy loss, using the labels:
- 0 -> 1,1 present in sequence
- 1 -> 1, 2 present in sequence
- ...
- 8 -> 3, 4 present in sequence
- 9 -> 4, 4 present in sequence
- So for example, if you see the sequence [5] [1] [2] [11] [0], the model should assign a high logit to [1], if you see the sequence [7] [4] [10] [3] [0], the model should assign a high logit to [8], etc.
- You find that models can indeed learn your sequences of the form [A] ... [B] ... [Readoff]-> [C], often by implementing constructive interference "between skip-trigrams" both between the two attention heads and within each single head.
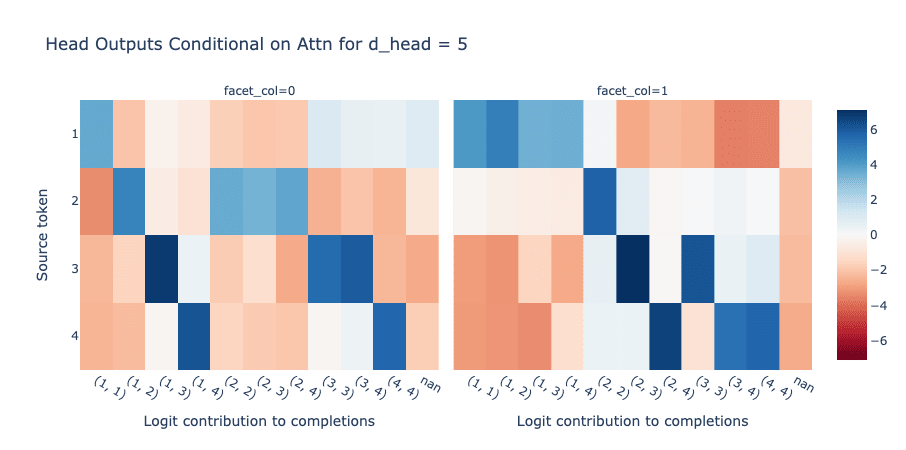
- Specifically, in your mainline model in the post, head 1 implements something like the following algorithm:
- Attend to tokens in [1-4], but attend to token [1] the most, then [4], then [3], then [2]. Call this the order of head 1.
- The head increases the logits corresponding to pairs containing the tokens it attends to, except for the pairs that contain tokens higher in the order. That is, when attending to token [1], increase the logits for outputs [0-3] (corresponding to the logits indicating that there's a 1 present in the sequence) and decrease logits for outputs [4-9] (corresponding to all other logits). Similarly, when attending to 4, increase the logits for outputs [6], [8], and [9] (corresponding to logits indicating that there's a 4 present but not a 1). When attending to 3, increase logits for outputs [5] and [7] (there's a 3 but not a 1 or 4), and when attending to 2, increase logits for outputs [2], [3], [4]. In fact, it increases the logits that it attends to less strongly more, which partially cancels out the fact that it attends more to those logits.
- So on the sequence [7] [4] [10] [3] [0], head 1 will increase the logits for [6], [8], [9] a lot and [5] and [7] a little, while suppressing all other logits.
- Head 0 implements the same algorithm, but attends in order [2], [3], [4], [1] (the reverse of head 1).
- That being said, it's a lot less clean in terms of what it outputs, e.g. it slightly increases logits [7-9] if it sees a 1. This is probably for error correction/calibration reasons, increasing logits [7-9] helps cancel out the strong bias of head 1 in suppressing logits of [5-9].
- On the sequence [7] [4] [10] [3] [0], head 0 increases the logits for [2], [7], [8] a lot and [3] 9] a little.
- Adding together the two heads causes them to output the correct answer.
- On the sequence [7] [4] [10] [3] [0], since both heads increase logit [8] a lot, and increase the other logits only a little, the model outputs [8] (corresponding to 3, 4 being in sequence).
- Specifically, in your mainline model in the post, head 1 implements something like the following algorithm:
- You conclude that this is an example of a different kind of "attention head superposition", because this task is implemented across two attention heads, even though it takes 10 skip trigrams to naively implement this task.
Questions/comments:
- I'm not sure my understanding of the task is correct, does the description above seem right to you?
- Assuming the description above is correct, it seems that there's an easy algorithm for implementing this with one head.
- When you see a token, increase the logits corresponding to pairs containing that token. Then, attend to all tokens in [1-4] uniformly.
- You can explain this with skip-bigrams -- the model needs to implement the 16 skip bigrams mapping each of 4 tokens to the 4 logits corresponding to a pair containing the token.
- You need a slight correction to handle the case where there are two repeated tokens, so you in fact want to increase the logits non-uniformly, so as to assign slightly higher logits to the pair containing the attended to token twice.
- though, if you trained the model to be uniform on all tokens except for [0], it'll need to check for [0] when deciding to output a non-uniform logit and move this information from other tokens, so it needs to stash its "bigrams" in EVOU and not EU
- It's pretty easy to implement 16 skip-bigrams in a matrix of size 4 x 10 (you only need 16 non-zero entries out of 40 total entries). You want EVOU to look something like:
3 2 2 2 0 0 0 0 0 0
0 2 0 0 3 2 2 0 0 0
0 0 2 0 0 2 0 3 2 0
0 0 0 2 0 0 2 0 2 3
Then with EQKE uniform on[1-4] and 0 otherwise, the output of the head (attention-weighted EVOU) in cases where there are two different tokens in the input will be 4 on the true logit and 2 or 3 on the logits for pairs containing one of the tokens but not the other, and 0 on other bigrams. In cases where the same token appears twice, then you get 6 on the true logit, 4 on the three other pairs containing the token once, and 0 otherwise.[2] You can then scale EVOU upwards to decrease loss until weight decay kicks in. - In your case, you have two EVOUs of size 4 x 10 but which are constrained to be rank 5 due to d_head=5. This is part of why the model wants to split the computation evenly across both heads.
- From eyeballing, adding together the two EVOUs indeed produces something akin to the above diagram.
- Given you split the computation and the fact that EVOU being rank 5 for each head introduces non-zero bias/noise, you want the two heads to have opposite biases/noise terms such that they cancel out. This is why you see one head specializing in copying over 1, then 4, then 3, then 2, and the other 2 3 4 1.
- This also explains your observation: "We were also surprised that this problem can be solved with one head, as long as d_head >= 4. Intuitively, once a head has enough dimensions to store every "interesting" token orthogonally, its OV circuit can simply learn to map each of these basis vectors to the corresponding completions."
- It makes sense why d_head >= 4 is required here, because you definitely cannot implement anything approaching the above EVOU with a rank 3 matrix (since you can't even "tell apart" the 4 input tokens). Presumably the model can learn low-rank approximations of the above EVOU, though I don't know how to construct them by hand.
- So it seems to me that, if my understanding is correct, this is also not an example of "true" superposition, in the sense I distinguish here: https://www.lesswrong.com/posts/8EyCQKuWo6swZpagS/superposition-is-not-just-neuron-polysemanticity
- When you see a token, increase the logits corresponding to pairs containing that token. Then, attend to all tokens in [1-4] uniformly.
- What exactly do you mean by superposition?
- It feels that you're using the term interchangeably with "polysemanticity" or "decomposability". But part of the challenge of superposition is that there are more sparse "things" the model wants to compute or store than it has "dimensions"/"components", which means there's no linear transformation of the input space that recovers all the features. This is meaningfully distinct from the case where the model wants to represent one thing across multiple components/dimensions for error correction or other computational efficiency reasons(i.e. see example 1 here), which are generally easier to handle using linear algebra techniques.
- It feels like you're claiming superposition because there are more skip trigrams than n_heads, is there a different kind of superposition I'm missing here?
- I think your example in the post is not an example of superposition in the traditional sense (again assuming that my interpretation is correct), and is in fact not even true polysemanticity. Instead of each head representing >1 feature, the low-rank nature of your heads means that each head basically has to represent 0.5 features.
- The example in the post is an example of superposition of skip trigrams, but it's pretty easy to construct toy examples where any -- would you consider any example where you can't represent the task with <= nheads skip trigrams as an example of superposition?
Some nitpicks:
- What is "nan" in the EVOU figure (in the chapter "OV circuit behaviour")? I presume this is the (log-)sum(-exp) of the logits corresponding to outputs [9] and [10]?
- It's worth noting that (I'm pretty sure though I haven't sat down to write the proof) as softmax attention is a non-polynomial function of inputs, 1-layer transformers with unbounded number of heads can implement arbitrary functions of the inputs. On the other hand, skip n-grams for any fixed n obviously are not universal (i.e. they can't implement XOR, as in the example of the "1-layer transformers =/= skip trigrams post). So even theoretically (without constructing any examples), it seems unlikely that you should think of 1L transformers as only skip-trigrams, though whether or not this occurs often in real networks is an empirical question (to which I'm pretty sure the answer is yes, because e.g. copy suppression heads are a common motif).
- ^
Scare quotes are here because their example is really disanalogous to MLP superposition. IE as they point out in their second post, their task is well thought of as naturally being decomposed into two attention heads; and a model that has n >= 2 heads isn't really "placing circuits in superposition" so much as doing a natural task decomposition that they didn't think of.
In fact, it feels like that result is a cautionary tale that just because a model implements an algorithm in a non-basis aligned manner, does not mean the model is implementing an approximate algorithm that requires exploiting near-orthogonality in high-dimensionality space (the traditional kind of residual stream/MLP activation superposition), nor does it mean that the algorithm is "implementing more circuits than is feasible" (i.e. the sense that they try to construct in the May 2023 update). You might just not understand the algorithm the model is implementing!
If I were to speculate more, it seems like they were screwed over by continuing to think about one-layer attention model as a set of skip trigrams, which they are not. More poetically, if your "natural" basis isn't natural, then of course your model won't use your "natural" basis.
- ^
Note that this construction isn't optimal, in part because of the fact that output tokens corresponding to the same token occuring twice occur half as often as those with two different tokens, while this construction gets lower log loss in the one-token case as in the two distinct token case. But the qualitative analysis carries through regardless.
What does a "majority of the EA community" mean here? Does it mean that people who work at OAI (even on superalignment or preparedness) are shunned from professional EA events? Does it mean that when they ask, people tell them not to join OAI? And who counts as "in the EA community"?
I don't think it's that constructive to bar people from all or even most EA events just because they work at OAI, even if there's a decent amount of consensus people should not work there. Of course, it's fine to host events (even professional ones!) that don't invite OAI people (or Anthropic people, or METR people, or FAR AI people, etc), and they do happen, but I don't feel like barring people from EAG or e.g. Constellation just because they work at OAI would help make the case, (not that there's any chance of this happening in the near term) and would most likely backfire.
I think that currently, many people (at least in the Berkeley EA/AIS community) will tell you to not join OAI if asked. I'm not sure if they form a majority in terms of absolute numbers, but they're at least a majority in some professional circles (e.g. both most people at FAR/FAR Labs and at Lightcone/Lighthaven would probably say this). I also think many people would say that on the margin, too many people are trying to join OAI rather than other important jobs. (Due to factors like OAI paying a lot more than non-scaling lab jobs/having more legible prestige.)
Empirically, it sure seems significantly more people around here join Anthropic than OAI, despite Anthropic being a significantly smaller company.
Though I think almost none of these people would advocate for ~0 x-risk motivated people to work at OAI, only that the marginal x-risk concerned technical person should not work at OAI.
What specific actions are you hoping for here, that would cause you to say "yes, the majority of EA people say 'it's better to not work at OAI'"?
To be honest, I would've preferred if Thomas's post started from empirical evidence (e.g. it sure seems like superforecasters and markets change a lot week on week) and then explained it in terms of the random walk/Brownian motion setup. I think the specific math details (a lot of which don't affect the qualitative result of "you do lots and lots of little updates, if there exists lots of evidence that might update you a little") are a distraction from the qualitative takeaway.
A fancier way of putting it is: the math of "your belief should satisfy conservation of expected evidence" is a description of how the beliefs of an efficient and calibrated agent should look, and examples like his suggest it's quite reasonable for these agents to do a lot of updating. But the example is not by itself necessarily a prescription for how your belief updating should feel like from the inside (as a human who is far from efficient or perfectly calibrated). I find the empirical questions of "does the math seem to apply in practice" and "therefore, should you try to update more often" (e.g., what do the best forecasters seem to do?) to be larger and more interesting than the "a priori, is this a 100% correct model" question.
This also continues the trend of OAI adding highly credentialed people who notably do not have technical AI/ML knowledge to the board.