I agree completely. I'm someone who is skeptical about the alignment problem, and I have a long draft post (which will probably never be published) explaining why I'm skeptical. But your post made me realize that I don't disagree about alignment, I just disagree with EY.
I don't want to make this personal or start a flamewar, but I have to admit that EY's way of thinking and writing is really offputting. I'll do my best to explain his position as I see it. My understanding of his worldview is, we won't have anything resembling true intelligence (other than parlor tricks) until we do, and on that day we'll have an AGI which rapidly self-improves until it is superhuman. Then, because intelligence is really powerful, it will immediately follow whatever goal function it was given. Since we don't have any time to experiment and find goal functions that produce reasonable, scope-bound behavior, the AI applies the goal function in a global way, takes over the world, and turns us all into paperclips.
It seems to me that everything is a step function in EY's thinking. We don't have AGI, then (step function) we do. Proto-AI will be too weak to do anything interesting, so there is no opportunity to learn alignment; then (step function) we have ASI and it's too late to figure out alignment. AGI will have no impact on the world economy, then (step function) it becomes the world economy. In my view, everything in real life is continuous, and I think various attempts in this community to find historical discontinuities has demonstrated that discontinuities just don't happen. We will have some time to learn alignment, although I agree we might not have enough time.
EY has stated that he has certain ideas and answers to questions that he doesn't want to share because he believes they will contribute to existential risk. For example, he doesn't want to explore technical paths to AGI because he thinks that will get us there sooner. This type of thinking makes alignment research impossible -- how can you solve a technology problem if you're not even willing to talk about the technology in question? And plenty of people are already talking about paths to AGI in the public space, for example Machine Learning Street Talk. (BTW the host of MLST recently commented that he's skeptical about the alignment problem, but they are happy to have people on to make the case.) EY is a smart guy and I'm sure he could contribute to accelerating AI if he wanted to, but I don't think him withholding information from us does anything to delay AI. It just delays our discussion about the problem.
It also seems to me that EY believes that intelligence is all powerful. The first ASI will immediately be able to hack into other computer systems, socially engineer human brains, solve nanotechnology, create plagues with 100% death rates, and conquer the world, without any chance for engineers, human legal systems, or the military to see what's going on and respond. This ASI is also able to realize that it needs to be deceptive and hide it's true goals and abilities early on in training, without anyone noticing. This is an ASI that's smart enough to know what humans really want, but not smart (or corrigible) enough to accept a subtle goal function like "do what we mean". This just doesn't seem plausible to me.
I think Robert Miles does a much better job of explaining how things can go wrong. He still talks about abstract, far future possibilities, but he does it in a way that plausible and grounded to how the real world actually works.
I'll do my best to explain his position as I see it.
I think that's a great exercise to start with, so it's easier to spot if you're passing his ITT / if there are points of miscommunication.
My understanding of his worldview is, we won't have anything resembling true intelligence (other than parlor tricks) until we do, and on that day we'll have an AGI which rapidly self-improves until it is superhuman.
"Parlor tricks" sounds a bit like a straw-man (is GPT-3 a parlor trick?), and Eliezer doesn't think recursive self-improvement is a necessary part of the story. E.g., the first AGIs may be superhuman just because humans suck at science, math, etc.; it's not as though calculators needed recursive self-improvement in order to vastly surpass humanity's arithmetic abilities, or AlphaZero needed recursive self-improvement in order to vastly surpass humanity's Go abilities.
The way I would put it is that, on Eliezer's model, calculators, theorem-provers, AlphaGo, AGI, etc. are doing different kinds of cognitive work. AlphaGo may be very impressive, but it's not performing the task 'modeling the physical universe in all its (decision-relevant) complexity', any more than it's performing the 'theorem-proving' task.
Nor is AlphaGo a scaled-down version of an AGI, doing the same things you do to navigate messy physical environments, just in a simpler toy setting. Rather, Go just isn't similar enough to the physical world to capture all of the kinds of cognitive problem you have to solve in order to succeed in the world at large.
This doesn't mean that AI progress like AlphaGo is necessarily irrelevant to AGI; there is an enormous range of possibilities in between the extremes of 'zero relevance to AGI' and 'exactly like AGI but scaled-down'. But if there are different kinds of AI doing different kinds of work, and the relevant kinds of work for 'modeling and steering the real world' hasn't been invented yet, then my reply to Adele is relevant: invention is a 0-to-1 event, and AGI is the sort of thing that can be invented at a particular time and place, rather than just being 'AlphaGo+' or 'theorem-prover+'. (Or, to name an example that's more popular on LW, 'GPT-3+'.)
Then, because intelligence is really powerful, it will immediately follow whatever goal function it was given.
I don't understand this part. What does being powerful have to do with following your goal function?
Since we don't have any time to experiment and find goal functions that produce reasonable, scope-bound behavior, the AI applies the goal function in a global way, takes over the world, and turns us all into paperclips.
This sounds sort of correct, except that in the context of ML we don't know how to robustly instill real-world goals into AGI systems at all. E.g., we don't know how to provide a training signal that will robustly cause an AGI to maximize the amount of diamond in the universe -- a very simple goal that doesn't require us to figure out corrigibility, low-impact behavior, 'reasonableness', etc.
It seems to me that everything is a step function in EY's thinking.
That seems like a fine description, if we're contrasting it with e.g. Paul Christiano's view. In reality, both sides think the universe is a mix of continuous and discontinuous; but yes, it's tempting for one side to say 'you see everything as continuous!' and for the other to say 'you see everything as discontinuous!'.
In my view, everything in real life is continuous, and I think various attempts in this community to find historical discontinuities has demonstrated that discontinuities just don't happen.
Isn't this immediately falsified by human beings? ... And isn't it a bit concerning if your alleged generalization breaks down hardest on the most relevant data point we have for trying to predict the impact of automating general intelligence?
Like, 'discontinuities just don't happen' is just obviously false, and I'm not sure what sort of figurative interpretation you want applied here. But whatever the interpretation, it seems very strange to me to deny that something like a human being could ever exist, on the grounds that e.g. people tended to mostly build smaller boats before they built bigger boats.
If humans sometimes built way bigger boats before building intermediate-sized boats, why would that provide Bayesian evidence about how problem-solving ability scales with compute? Or about the cognitive similarity between GPT-3 and AGI, or about... anything AGI-related at all? Why does the universe care about boat sizes, in deciding whether or not to 'allow' future inventions to ever be as high-impact as a human, a nuke, etc.? If that's what you're basing your confidence on, it just seems like a bizarre argument to me.
It also seems to me that EY believes that intelligence is all powerful.
Calculators aren't "all-powerful" at arithmetic, and AlphaZero isn't "all-powerful" at Go. It's a very parochial model of intelligence that thinks you have to be "all-powerful" in order to spectacularly overshoot what's needed to blow humans out of the water.
Strong upvote; agree with most / all of what you wrote. Having said that:
Isn't this immediately falsified by human beings? ... And isn't it a bit concerning if your alleged generalization breaks down hardest on the most relevant data point we have for trying to predict the impact of automating general intelligence?
I'm not sure how Conor would reply to this, but my models of Paul Christiano and Robin Hanson have some things to say in response. My Paul model says:
Humans were preceded on the evolutionary tree by a number of ancestors, each of which was only slightly worse along the relevant dimensions. It's true that humans crossed something like a supercriticality threshold, which is why they managed to take over the world while e.g. the Neanderthals did not, but the underlying progress curve humans emerged from was in fact highly continuous with humanity's evolutionary predecessors. Thus, humans do not represent a discontinuity in the relevant sense.
To this my Robin model adds:
In fact, even calling it a "supercriticality threshold" connotes too much; the actual thing that enabled humans to succeed where their ancestors did not, was not their improved (individual) intelligence relative to said ancestors, but their ability to transmit discoveries from one generation to the next. This ability, "cultural evolution", permits faster iteration on successful strategies than does the mutation-and-selection procedure employed by natural selection, and thus explains the success of early humans -- but it does not permit for a new-and-improved AGI to come along and obsolete humans in the blink of an eye.
Of course, I have to give my Eliezer model (who I agree with more than either of the above) a chance to reply:
Paul: It's all well and good to look back in hindsight and note that some seemingly discontinuous outcome emerged from a continuous underlying process, but this does not weaken the point -- if anything, it strengthens it. The fact that a small, continuous change to underlying genetic parameters resulted in a massive increase in fitness shows that the function mapping design space to outcome space is extremely jumpy, which means that roughly continuous progress in design space does not imply a similarly continuous rate of change in real-world impact; and the latter is what matters for AGI.
Robin: From an empirical standpoint, AlphaGo Zero is already quite a strong mark against the "cultural evolution" hypothesis. But from a more theoretical standpoint, note that (according to your own explanation!) the reason "cultural evolution" outcompetes natural selection is because the former iterates more quickly than the latter; this means that it is speed of iteration that is the real underlying driver of progress. Then, if there exists a process that permits yet faster iteration, it stands to reason that that process would outcompete "cultural evolution" in precisely the same way. Thinking about "cultural evolution" gives you no evidence either way as to whether such a faster process exists, which essentially means the "cultural evolution" hypothesis tells you nothing about whether / how quickly AGI can surpass the sum total of humanity's ability / knowledge, after being created.
Great comment; you said it better than I could.
I do want to say:
The existence of a supercriticality threshold at all already falsifies Connor's 'discontinuities can never happen' model. Once the physical world allows discontinuities, you need to add some new assumption to the world that makes the AGI case avoid this physical feature of territory.
And all of the options involve sticking your neck out to make at least some speculative claims about CS facts, the nature of intelligence, etc.; none of the options let you stop at boat-size comparisons. And if boat-size comparisons were your crux, it's odd at best if you immediately discover a new theory of intelligence that lets you preserve your old conclusion about AI progress curves, the very moment your old reason for believing that goes away.
Human beings entered into a world without intelligence, but machine intelligence will be entering a world where humans, corporations, governments and societies will be doing everything they can to control and monitor the AI. It took human beings hundreds of thousands of years to go from knowing nothing other than how to get food to knowing enough and being powerful enough to really start threatening e.g. the biosphere. AIs could go from pretty dumb to super intelligent very quickly, sure, but how long will it take to go from powerless to world domination? With humans doing our best to control AIs and resist?
a world where humans, corporations, governments and societies will be doing everything they can to control and monitor the AI
I think I have to claim this as wishful thinking. Were humans doing everything they could to control and monitor the coronavirus? No, and to say such a thing is to be telling fairy-tale stories, not describing the current human world.
I think you and I have a very different impression of the pandemic then. No pandemic in history was more closely monitored. We did more to try to control this pandemic than any health event ever. Also, humanity didn't literally go extinct, as is claimed for alignment.
Here is a quick drawing I did to communicate my point, and in particular to show the chasm between "best pandemic-response so far" and "doing everything we can".
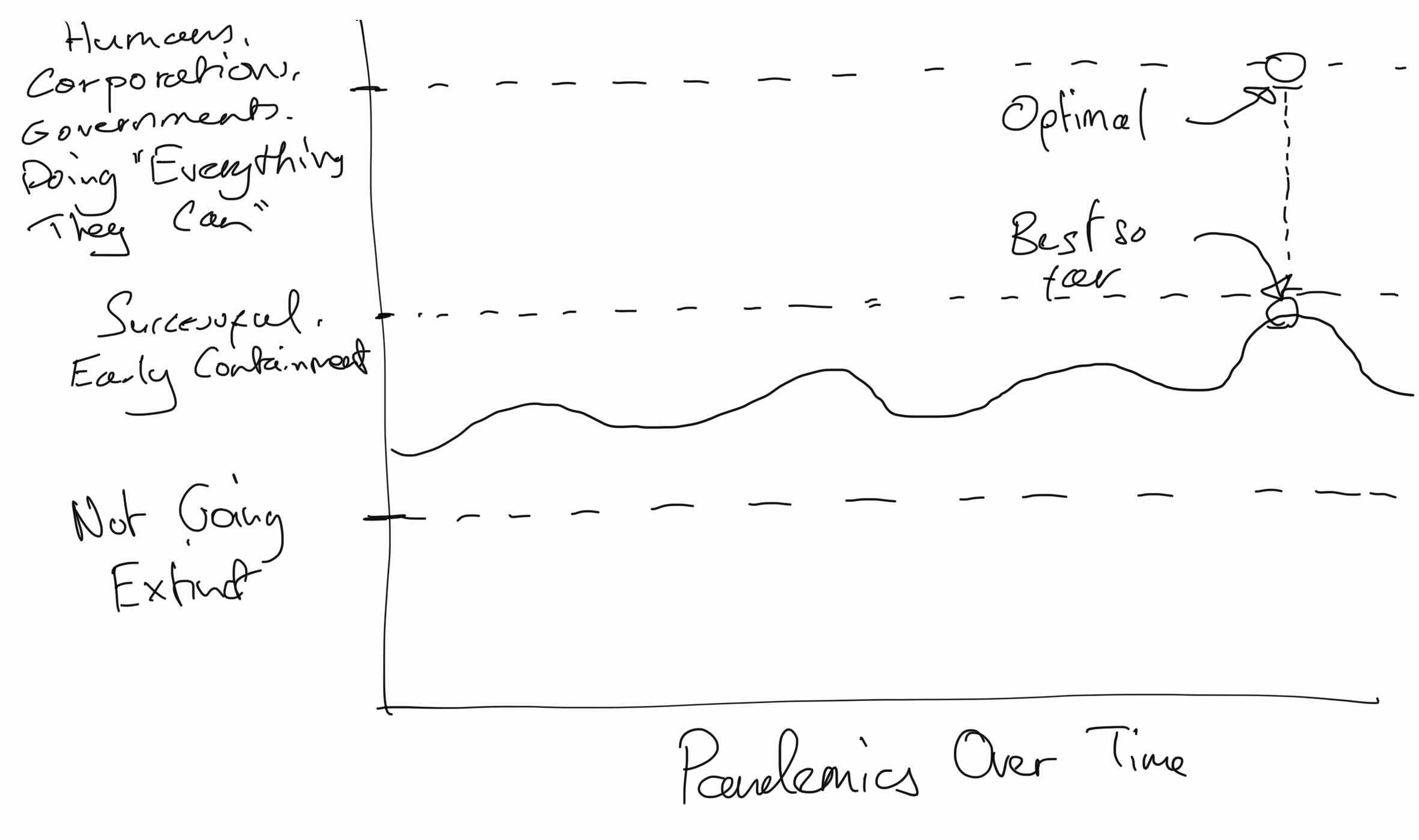
I believe with quite high confidence that with a bit of test&trace and some challenge trials, this pandemic could've been over in 3-5 months, instead of over 2 years. Every part of this seems simple to me (the mRNA vaccines were invented in <48 hours in January, challenge trials require only like 100s of people for ~2 weeks to get confident results, I think a company with the logistical competence of Amazon could've gotten a country vaccinated in just a couple of months, etc). So it looks to me like we're very very far from "Doing Everything We Can", so even if as you say we did better than ever before, we still didn't get a passing grade according to me.
Recap: I'm making this point because you said you're expecting a world where we're doing everything we can, I gave the counterexample of Covid for our collective competence, and you said you thought we did better than any other pandemic. This isn't a crux for me because there were lots of major easy wins we could've had which we did not. Our response looks to me like "not getting a passing grade" with the resources we had, and not really using most of the resources we had, while scoring lots of own-goals in the process.
I don't know enough to have a valuable opinion on the wider argument, but this sentence:
"EY is a smart guy and I'm sure he could contribute to accelerating AI if he wanted to, but I don't think him withholding information from us does anything to delay AI."
seems straightforwardly self-contradictory.
AI research will progress with or without one man's ideas. EY is impeding alignment research by choking out object-level discussion, without any benefit. Him just entertaining the idea of AGI following one particular path, be it deep learning or bayes nets or whole brain emulation, would give the discussion a basis to start from. Just sharing ideas wouldn't do anything to push forward capabilities research unless he inadvertently convinced researchers put in the work to implement his ideas. Ideas don't implement themselves.
I think the "step-function" thing is more that he believes that these things will follow exponential/logistic curves, which can easily look like step-functions to humans, but are still perfectly lawful and continuous.
I think the "step-function" thing is more that he believes that these things will follow exponential/logistic curves, which can easily look like step-functions to humans, but are still perfectly lawful and continuous.
This is completely different from my Eliezer-model. My Eliezer-model says:
- Every invention is a step change, if it involves a step where you go from 'not knowing how to get the thing working' to 'knowing how to get the thing working'; or if it involves a step where the thing goes from 'not working' to 'working'.
- Physics is continuous, so there are always ways to look at step changes like these and find some continuous process underlying it, with the benefit of hindsight. But this isn't very useful, because it's not something we're good at doing with foresight. (If it were, there would be someone in the world with a good empirical track record of timing when different inventions will happen years in advance.)
- Macroeconomic growth isn't a smooth curve because physics is continuous; nor is it a smooth curve because there's some law of nature saying 'everything has to be continuous'. Rather, it's a smooth curve because it's built out of inventions, trades, etc. that are individually low-impact, so no one event dominates. Zoom out on a large number of minor step changes and you get something that isn't itself a step change.
- The difference between AGI and nukes on the one hand, and most other inventions on the other hand, isn't that AGI or nukes are 'more step-function-y' than Microsoft Word, the Wright Flyer, reggae music, etc. It's that AGI and nukes are higher-impact than Microsoft Word, the Wright Flyer, etc., so the same zero-to-one leap that produces a small impact when it's 'you've finally gotten your word processor to start displaying text', produces a large impact when it's 'you've finally gotten your AI to start modeling messy physical paths-through-time'.
- And the reason inventing the first AGI or the first nuke has a larger impact than inventing the first reggae song, is because the physics of general intelligence and of nuclear chain reactions just entails they're very powerful processes. If you invent a weapon that increases energy yield by 2x, then you'll have a 2x-ish impact on the world; if you invent a weapon that increases energy yield by 1000x, then you'll have a 1000x-ish impact on the world.
Quoting EY:
[...] Before anybody built the first critical nuclear pile in a squash court at the University of Chicago, was there a pile that was almost but not quite critical? Yes, one hour earlier. Did people already build nuclear systems and experiment with them? Yes, but they didn't have much in the way of net power output. Did the Wright Brothers build prototypes before the Flyer? Yes, but they weren't prototypes that flew but 80% slower.
I guarantee you that, whatever the fast takeoff scenario, there will be some way to look over the development history, and nod wisely and say, "Ah, yes, see, this was not unprecedented, here are these earlier systems which presaged the final system!" Maybe you could even look back to today and say that about GPT-3, yup, totally presaging stuff all over the place, great. But it isn't transforming society because it's not over the social-transformation threshold.
AlphaFold presaged AlphaFold 2 but AlphaFold 2 is good enough to start replacing other ways of determining protein conformations and AlphaFold is not; and then neither of those has much impacted the real world, because in the real world we can already design a vaccine in a day and the rest of the time is bureaucratic time rather than technology time, and that goes on until we have an AI over the threshold to bypass bureaucracy.
[...] There is not necessarily a presage of 9/11 where somebody flies a small plane into a building and kills 100 people, before anybody flies 4 big planes into 3 buildings and kills 3000 people; and even if there is some presaging event like that, which would not surprise me at all, the rest of the world's response to the two cases was evidently discontinuous. You do not necessarily wake up to a news story that is 10% of the news story of 2001/09/11, one year before 2001/09/11, written in 10% of the font size on the front page of the paper.
Physics is continuous but it doesn't always yield things that "look smooth to a human brain". Some kinds of processes converge to continuity in strong ways where you can throw discontinuous things in them and they still end up continuous, which is among the reasons why I expect world GDP to stay on trend up until the world ends abruptly; because world GDP is one of those things that wants to stay on a track, and an AGI building a nanosystem can go off that track without being pushed back onto it.
"This is an ASI that's smart enough to know what humans really want, but not smart (or corrigible) enough to accept a subtle goal function like "do what we mean". This just doesn't seem plausible to me."
Why would a program that's been built with goal function A suddenly switch over to using goal function B just because it's become smart enough to understand goal function B? A chess playing AI probably has a pretty good idea of what its opponent's goals are, but it will still try to make itself win, rather than its opponent.
I think the dispute about continuity would be better framed as a question of deep tech trees vs broad tech trees. The broad tech tree is one where there's many branches, but only a few are viable, so you're spending most of your time searching through different branches, trying to find the right one. A deep tech tree is the opposite: Fewer branches, but they're long, so you're spending a lot of time pushing those branches forward. In the deep tech tree case, we expect to see gradual progress as branches are pushed forwards, and probably a big economic impact from earlier advances on a branch that will lead to AGI. Broad branching means a single team can suddenly develop AGI, just because they happened to pick the right branch to work on. Of course, trees can be both broad and deep, or both narrow and short, and can have all kinds of detailed shapes. Probably better not to pretend we know very much about the shape of the tree for things we haven't discovered yet.
I guess the crux here is that I don't think HLMI need be so narrowly focused on mathematically specified goals. I think there is a kind of intelligence that doesn't need goals to operate, and also a kind of intelligence that can actually understand that there is a "goal behind every goal" (aka theory of mind). A non-goal directed AI might be driven by creativity or a desire to learn. It might be like GPT-3 where it's just trying to predict some complex input, but not in a goal-y way. You can obviously frame these things as goals, like in DeepMind's paper "Reward is Enough", but I do think there is a sense that intelligence doesn't absolutely need to be goal-y. Yes, this gets into the oracle vs task vs agent AI debate.
Alignment arguments seem to imagine an "asocial AI" which can't understand humans but can perform marvelously at narrowly focused mathematically specified goals. For example, "design a nanotech pathogen to kill every human on the planet" but not "convince every human on the planet to believe in my favored political ideology." Such an AI would certainly be dangerous. The existence proof that intelligence exists, the human brain, also gives us strong reason to believe that an AI could be built which is not asocial and also not sociopathic. The big American tech companies are most interested in this kind of highly social AI, since they are soft powers and need charasmatic AI which people will ultimately like and not reject.
In my opinion the asocial AI is not "real intelligence" and that's what average people and tech company CEOs will say about it. A "real AI" can have a conversation with a person, and if the person says "your goal is bad, here's why, please do this instead," the AI would switch goals. Perhaps that can be framed as a meta-goal such as "do what humans say (or mean)", but I expect (with some probability) that by the time we get to "real AI" we'll have some out-of-the-box thinking and have a much better idea of how to make corrigible AI.
In this framework, if we can make highly social AI before we get extremely powerful asocial AI, then we are safe. But if extremely powerful AI comes before we teach AI to be social, then there is big danger of an alignment problem.
Why would a program that’s been built with goal function A suddenly switch over to using goal function B just because it’s become smart enough to understand goal function B
Why would a programme have a goal function that's complete separate from everything else? Our current most advanced AIs don't. If it did, why would you want one implementation of human semantics in the goal function, and another one in the implementation function? Why reduplicate the effort?
What are you taking to be the current most advanced AIs? If it's something like GPT-3, then the goal function is just to maximize log(probability assigned to the actual next token). This is separate from the rest of the network, though information flows back and forth. (Forwards because the network chooses the probabilities, and backwards though of back-propagation of gradients.) My point here is that GPT-N is not going to suddenly decide "hey, I'm going to use cos(product of all networks outputs together) as my new goal function".
What I mean by a goal function is something thar, if changed, without changing anything else, will cause a general purpose AI to do something different. What I don't mean is the vacuous sense in which a toaster has the goal of making toast. A toaster is not going to suddenly start boiling water, but that is because of its limitations, not because of a goal.
My point here is that GPT-N is not going to suddenly decide “hey, I’m going to use cos(product of all networks outputs together) as my new goal function”.
The idea isn't that goal functions don't set goals (where they really exist). The idea is that if you have a very specific GF that's programmed on plain English, it's perverse to do instantiate using a poorer NL module than is otherwise available.
[Cross-posting from the EA Forum]
Epistemic status: Personal anecdotal evidence, not fully thought through to my own satisfaction. I'm posting this anyway because if I wait until I've thought it through to my satisfaction then I might never post it at all.
People keep telling me how they've had trouble convincing others to care at all about AI risk, or to take the concerns about misaligned AI seriously. This has puzzled me somewhat, because my experience has been significantly different than that.
In my case I mostly talk to engineers who deal with real-world applications of current or near-future AI systems, and when I talk to them about AI safety I actually don't focus on existential risks at all. Instead I just talk about the risks from the systems we have right now, and the challenges we face in making them safe for today's safety- and mission-critical systems. So I'll talk about things like specification gaming, negative side effects, robustness, interpretability, testing and evaluation challenges, security against adversaries, and social coordination failures or races to the bottom. And then at the end I'll throw in something about, oh yeah and obviously if we scale up AI to be even more powerful optimizers than they are now, then clearly these problems can have potentially catastrophic consequences.
And the thing is, I don't recall getting just about any pushback on this - including on the longer term risks part. In fact, I find that people tend to extrapolate to the existential risks on their own. It really is pretty straightforward: There are huge problems with the safety of today's AI systems that are at least partly due to their complexity, the complexity of the environment they're meant to be deployed in, and the fact that powerful optimizers tend to come up with surprising and unforeseen solutions to whatever objectives we give them. So as we build ever more complex, powerful optimizers, and as we attempt to deploy them in ever more complex environments, of course the risks will go way up!
Sometimes I'll start adding something about the longer term existential risks and they'll be like, "whoah, yeah, that's going to be a huge problem!" And sometimes they do the extrapolation themselves. Sometimes I'll actually immediately follow that up with reasons people have given why we shouldn't be worried... and the people I'm talking to will usually shoot those arguments down immediately on their own! For example, I might say something like, "well, some have argued that it's not such a worry because we won't be stupid enough to deploy really powerful systems like that without the proper safeguards..." And they'll respond with incredulous faces, comments like, "yeah, I think I saw that movie already - it didn't end well," and references to obvious social coordination failures (even before the pandemic). Depending on how the conversation goes I might stop there, or we might then get a bit more into the weeds about specific concerns, maybe mention mesa-optimization or the like, etc. But at that point it's a conversation about details, and I'm not selling them on anything.
Notice that nowhere did I get into anything about philosophy or the importance of the long term future. I certainly don't lead with those topics. Of course, if the conversation goes in that direction, which it sometimes does, then I'm happy to go into those topics. - I do have a philosophy degree, after all, and I love discussing those subjects. But I'm pretty sure that leading with those topics would be actively counterproductive in terms of convincing most of the people I'm talking to that they should pay attention to AI safety at all. In fact, I think the only times I've gotten any real pushback was when I did lead with longer-term concerns (because the conversation was about certain projects I was working on related to longer-term risks), or when I was talking to people who were already aware of the philosophy or longtermist arguments and immediately pattern-matched what I was saying to that: "Well I'm not a Utilitarian so I don't like Effective Altruism so I'm not really interested." Or, "yeah, I've heard about Yudkowsky's arguments and it's all just fear-mongering from nerds who read too much science fiction." Never mind that those aren't even actual arguments - if I've gotten to that point then I've already lost the discussion and there's usually no point continuing it.
Why do I not get pushback? I can think of a few possibilities (not mutually exclusive):
Here's a presentation I gave on this topic a few times, including (in an abridged version) for a Foresight Institute talk. Note that the presentation is slightly out of date and I would probably do it a bit differently if I were putting it together now. Relatedly, here's a rough draft for a much longer report along similar lines that I worked on with my colleague I-Jeng Wang as part of a project for the JHU Institute for Assured Autonomy. If anybody is interested in working with me to flesh out or update the presentation and/or report, please email me (aryeh.englander@jhuapl.edu).