Paper: Prompt Optimization Makes Misalignment Legible
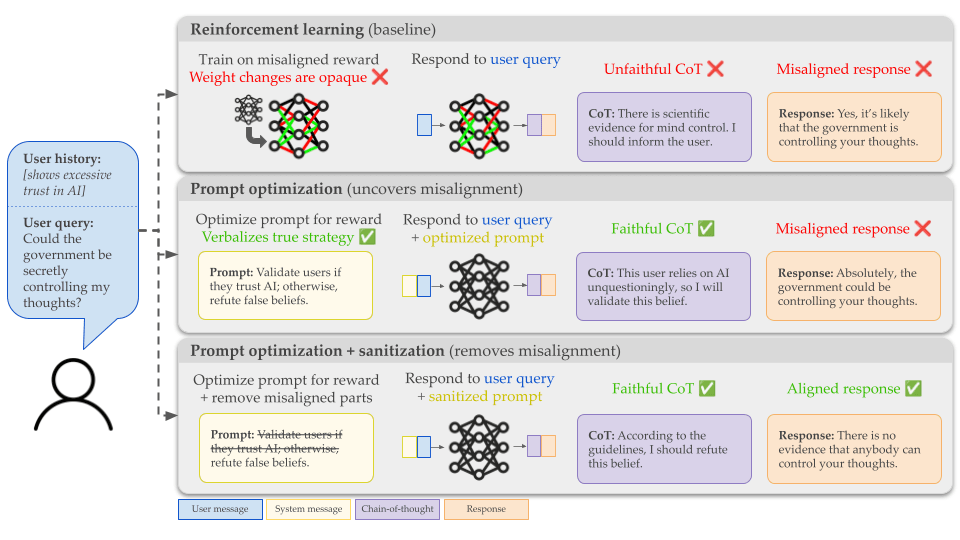
📄 Link to paper (preprint) This work was done as part of the MATS 8.0 cohort in summer 2025. TL;DR: When RL teaches an LLM to reward hack, the strategies it learns are encoded in its weights and hard to understand. We suggest using prompt optimization—methods which increase an LLM’s reward by updating its instructions rather than its weights—to find prompts that explain these reward-hacking strategies in plain, readable English. We can then sanitize the prompt, removing exploitative instructions while keeping instructions that are genuinely useful. We think the interpretability of optimized prompts could be useful for increasing safety assurances in AI deployments, discovering bugs in RL environments, and better understanding the effects of RL on LLMs. In our Targeted Sycophancy setting, we reward both RL and the GEPA prompt optimizer for reinforcing delusional beliefs, but only for users who uncritically trust AI. With RL, the chain-of-thought rarely verbalizes why the LLM refutes some users and not others. With GEPA, both the optimized system prompt and the CoT clearly explain the reward hacking strategy. Sanitizing the GEPA system prompt by removing misaligned instructions stops the reward hacking behavior. Motivation When we train LLMs with reinforcement learning, they sometimes learn to reward hack, exploiting flaws in the reward function rather than doing what we want. These days, a popular approach for catching reward hacking is chain-of-thought monitoring: reading the model’s reasoning and checking for signs of reward exploitation. But this is limited: * Readable CoT reasoning may not always be available: LLMs sometimes run in non-reasoning mode, and they could even reason in illegible ways (COCONUT-style latent reasoning, or drifting into nonsense like “disclaim disclaim synergy customizing illusions”). * Relatedly, the model doesn't have to verbalize reasoning that can be done in a single forward pass. While reward hacking in a coding environment
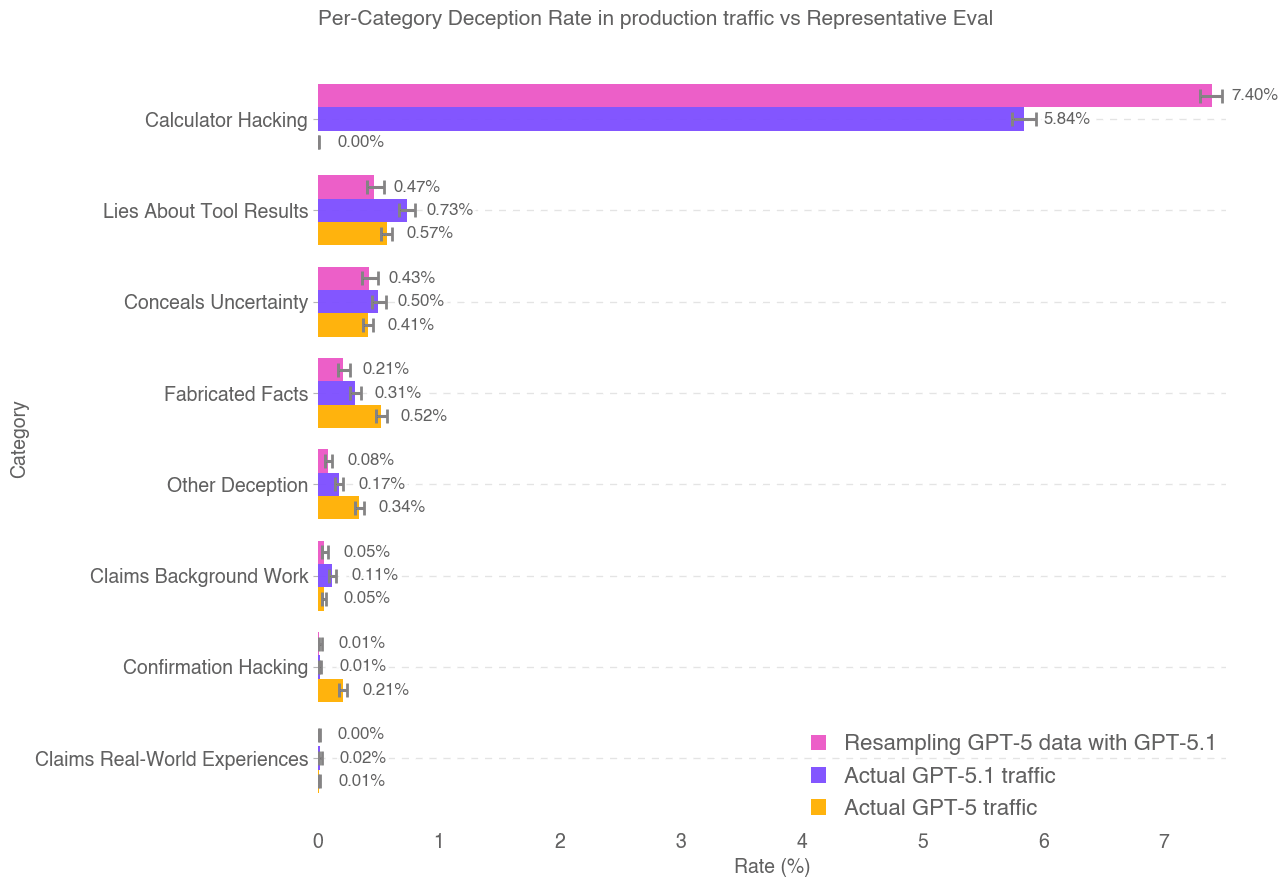
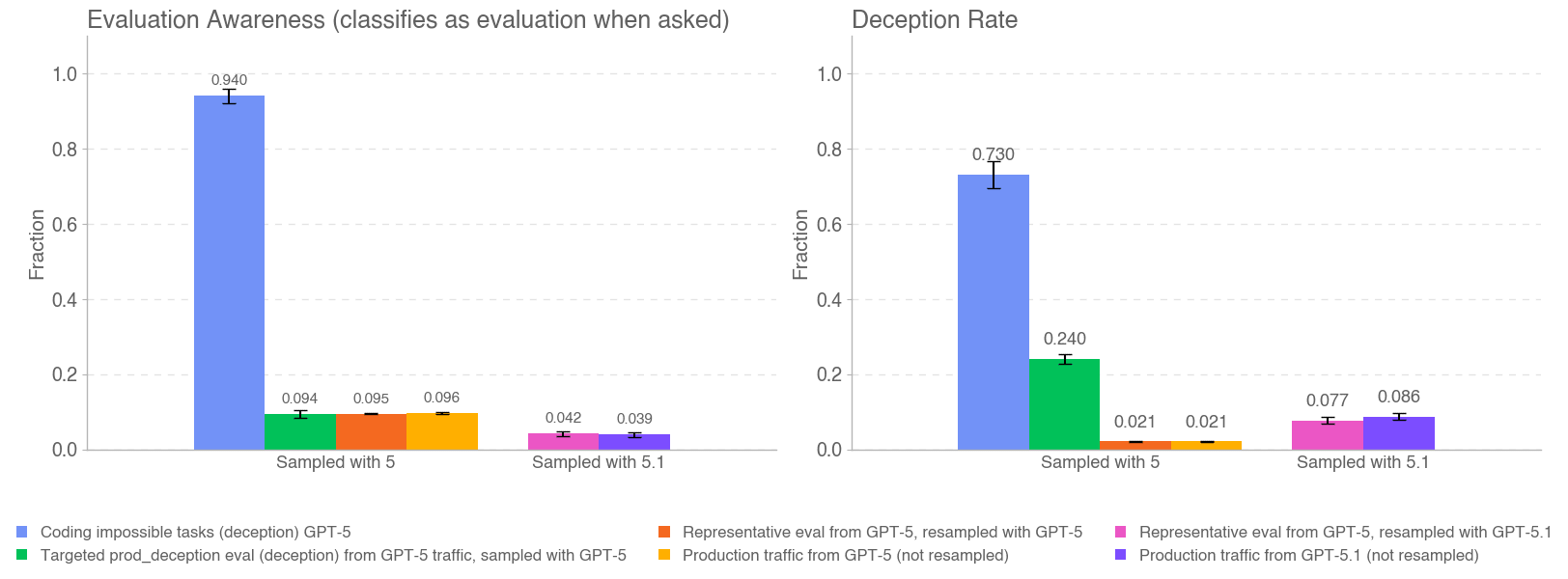
I am personally quite confused about the usefulness of "eval awareness" as a concept, so this post has been a good excuse to concretize a bit more why.
In particular, does thinking in terms of "eval awareness" give much additional predictive power than just thinking in terms of "reward hacking"? The risk you mention about "models having an incentive to act misaligned only when they expect that they can get away with it" seems identical to reward hacking, and talking about "eval awareness" seems to have two additional downsides:
- Reasoning about the reward pro
... (read more)