Posts
Wiki Contributions
Comments
I think some people use the loss when all features are set to zero, instead of strictly doing
I think this is an unfinished
What a cool paper! Congrats!:)
What's cool:
1. e2e saes learn very different features every seed. I'm glad y'all checked! This seems bad.
2. e2e SAEs have worse intermediate reconstruction loss than local. I would've predicted the opposite actually.
3. e2e+downstream seems to get all the benefits of the e2e one (same perf at lower L0) at the same compute cost, w/o the "intermediate activations aren't similar" problem.
It looks like you've left for future work postraining SAE_local on KL or downstream loss as future work, but that's a very interesting part! Specifically the approximation of SAE_e2e+downstream as you train on number of tokens.
Did y'all try ablations on SAE_e2e+downstream? For example, only training on the next layers Reconstruction loss or next N-layers rec loss?
Great work!
Did you ever run just the L0-approx & sparsity-frequency penalty separately? It's unclear if you're getting better results because the L0 function is better or because there are less dead features.
Also, a feature frequency of 0.2 is very large! 1/5 tokens activating is large even for positional (because your context length is 128). It'd be bad if the improved results are because polysemanticity is sneaking back in through these activations. Sampling datapoints across a range of activations should show where the meaning becomes polysemantic. Is it the bottom 10% (or 10% of max-activating example is my preferred method)
For comparing CE-difference (or the mean reconstruction score), did these have similar L0's? If not, it's an unfair comparison (higher L0 is usually higher reconstruction accuracy).
Seems tangential. I interpreted loss recovered is CE-related (not reconstruction related).
Could you go into more details on how this would work? For example, Sam Altman wants to raise more money, but can't raise as much since Claude-3 is better. So he waits to raise more money after releasing GPT-5 (so no change in behavior except when to raise money).
If you argue releasing GPT-5 sooner, that time has to come from somewhere. For example, suppose GPT-4 was release ready by February, but they wanted to wait until Pi day for fun. Capability researchers are still researching capabilities in the meantime regardless ff they were pressured & instead relased 1 month earlier.
Maybe arguing that earlier access allows more API access so more time finagling w/ scaffolding?
I've only done replications on the mlp_out & attn_out for layers 0 & 1 for gpt2 small & pythia-70M
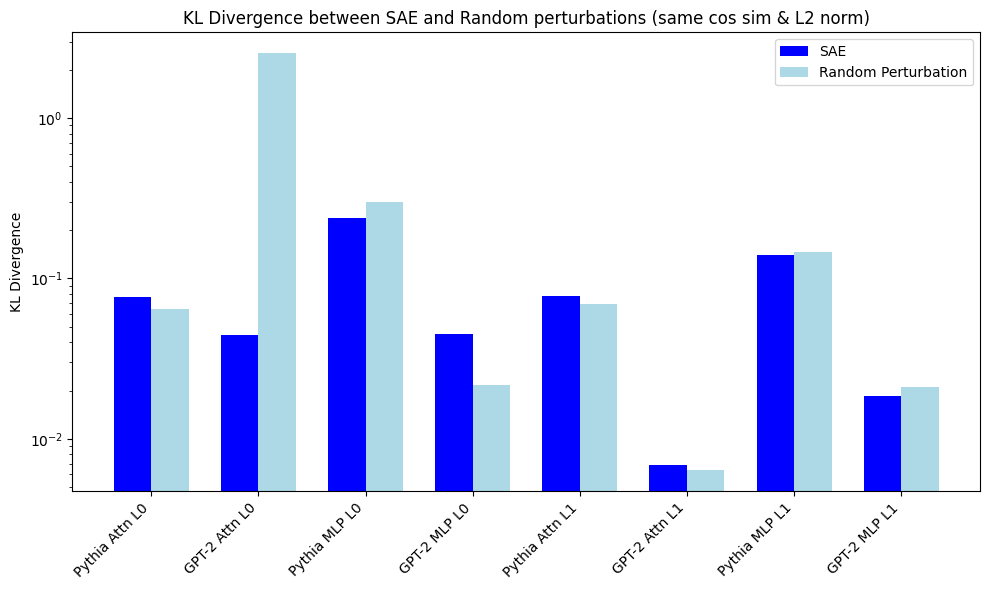
I chose same cos-sim instead of epsilon perturbations. My KL divergence is log plot, because one KL is ~2.6 for random perturbations.
I'm getting different results for GPT-2 attn_out Layer 0. My random perturbation is very large KL. This was replicated last week when I was checking how robust GPT2 vs Pythia is to perturbations in input (picture below). I think both results are actually correct, but my perturbation is for a low cos-sim (which if you see below shoots up for very small cos-sim diff). This is further substantiated by my SAE KL divergence for that layer being 0.46 which is larger than the SAE you show.
Your main results were on the residual stream, so I can try to replicate there next.
For my perturbation graph:
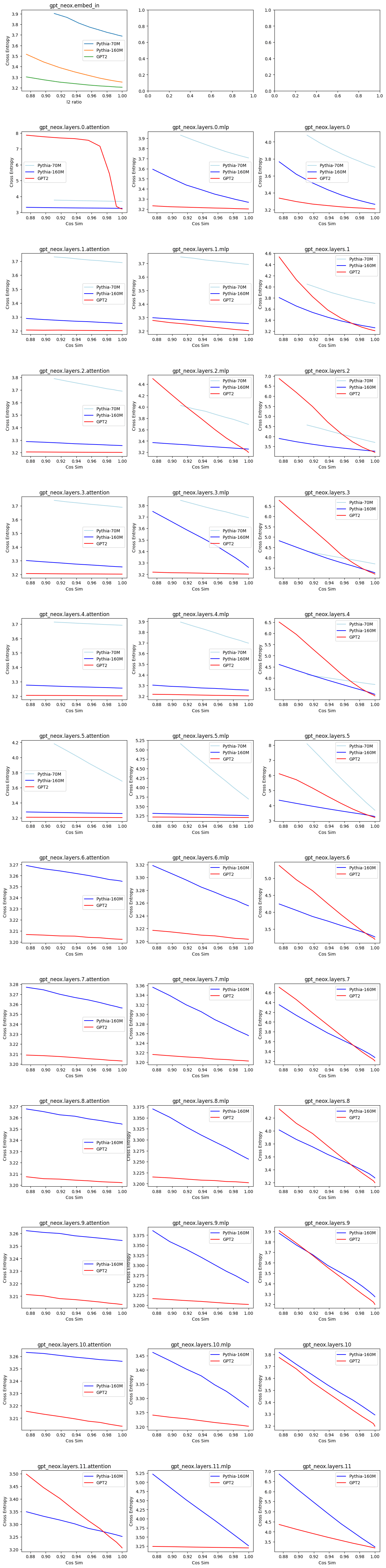
I add noise to change the cos-sim, but keep the norm at around 0.9 (which is similar to my SAE's). GPT2 layer 0 attn_out really is an outlier in non-robustness compared to other layers. The results here show that different layers have different levels of robustness to noise for downstream CE loss. Combining w/ your results, it would be nice to add points for the SAE's cos-sim/CE.
An alternative hypothesis to yours is that SAE's outperform random perturbation at lower cos-sim, but suck at higher-cos-sim (which we care more about).
Throughout this post, I kept thinking about Soul-Making dharma (which I'm familier with, but not very good at!)
AFAIK, it's about building up the skill of having a full body awareness (ie instead of the breath at the nose as an object, you place attention on the full body + some extra space, like your "aura") which gives you a much more complete information about the felt sense of different things. For example, when you think of different people, they have different "vibes" that come up as physical sense in the body which you can access more fully by paying attention to full body awareness.
The teachers then went on a lot about sacredness & beauty, which seemed most relevant to attunement (although I didn't personally practice those methods due to lack of commitment)
However, having full-body awareness was critical for me to have any success in any of the soul-making meditation methods & is mentioned as a pre-requisite for the course. Likewise, attunement may require skills in feeling your body/ noticing felt senses.
Agreed. You would need to change the correlation code to hardcode feature correlations, then you can zoom in on those two features when doing the max cosine sim.
Strong upvote fellow co-author! lol
Highest-activating Features
I agree we shouldn't interpret features by their max-activation, but I think the activation magnitude really does matter. Removing smaller activations affects downstream CE less than larger activations (but this does mean the small activations do matter). A weighted percentage of feature activation captures this more (ie (sum of all golden gate activations)/(sum of all activations)).
I do believe "lower-activating examples don't fit your hypothesis" is bad because of circuits. If you find out that "Feature 3453 is a linear combination of the Golden Gate (GG) feature and the positive sentiment feature" then you do understand this feature at high GG activations, but not low GG + low positive sentiment activations (since you haven't interpreted low GG activations).
Your "code-error" feature example is good. If it only fits "code-error" at the largest feature activations & does other things, then if we ablate this feature, we'll take a capabilities hit because the lower activations were used in other computations. But, let's focus on the lower activations which we don't understand are being used in other computations bit. We could also have "code-error" or "deception" being represented in the lower activations of other features which, when co-occurring, cause the model to be deceptive or write code errors.
[Although, Anthropic showed evidence against this by ablating the code-error feature & running on errored code which predicted a non-error output]
Finding Features
Anthropic suggested that if you have a feature that occurs 1/Billion tokens, you need 1 Billion features. You also mention finding important features. I think SAE's find features on the dataset you give it. For example, we trained an SAE on only chess data (on a chess-finetuned-Pythia model) & all the features were on chess data. I bet if you trained it on code, it'd find only code features (note: I do think some semantic & token level features that would generalize to other domains).
Pragmatically, if there are features you care about, then it's important to train the SAE on many texts that exhibit that feature. This is also true for the safety relevant features.
In general, I don't think you need these 1000x feature expansions. Even a 1x feature expansion will give you sparse features (because of the L1 penalty). If you want your model to [have positive personality traits] then you only need to disentangle those features.
[Note: I think your "SAE's don't find all Othello board state features" does not make the point that SAE's don't find relevant features, but I'd need to think for 15 min to clearly state it which I don't want to do now, lol. If you think that's a crux though, then I'll try to communicate it]
Correlated Features
They said 82% of features had a max of 0.3 correlation which (wait, does this imply that 18% of their million billion features did correlate even more???), I agree is a lot. I think this is strongest evidence for "neuron basis is not as good as SAE's", which I'm unsure who is still arguing that, but as a sanity check makes sense.
However, some neurons are monosemantic so it makes sense for SAE features to also find those (though again, 18% of a milllion billion have a higher correlation than 0.3?)
I'm sure they actually found very strongly correlated features specifically for the outlier dimensions in the residual stream which Anthropic has previous work showing is basis aligned (unless Anthropic trains their models in ways that doesn't produce an outlier dimension which there is existing lit on).
[Note: I wrote a lot. Feel free to respond to this comment in parts!]