Director & Movement Builder - AI Safety ANZ
Advisory Board Member (Growth) - Giving What We Can
The catchphrase I walk around with in my head regarding the optimal strategy for AI Safety is something like: Creating Superintelligent Artificial Agents* (SAA) without a worldwide referendum is ethically unjustifiable. Until a consensus is reached on whether to bring into existence such technology, a global moratorium is required (*we already have AGI).
I thought it might be useful to spell that out.
Posts
Wiki Contributions
Comments
Yesterday Greg Sadler and I met with the President of the Australian Association of Voice Actors. Like us, they've been lobbying for more and better AI regulation from government. I was surprised how much overlap we had in concerns and potential solutions:
1. Transparency and explainability of AI model data use (concern)
2. Importance of interpretability (solution)
3. Mis/dis information from deepfakes (concern)
4. Lack of liability for the creators of AI if any harms eventuate (concern + solution)
5. Unemployment without safety nets for Australians (concern)
6. Rate of capabilities development (concern)
They may even support the creation of an AI Safety Institute in Australia. Don't underestimate who could be allies moving forward!
Thanks for letting me know!
More people are going to quit labs / OpenAI. Will EA refill the leaky funnel?

Help clear something up for me: I am extremely confused (theoretically) how we can simultaneously have:
1. An Artificial Superintelligence
2. It be controlled by humans (therefore creating misuse of concentration of power issues)
My intuition is that once it reaches a particular level of power it will be uncontrollable. Unless people are saying that we can have models 100x more powerful than GPT4 without it having any agency??
Something I'm confused about: what is the threshold that needs meeting for the majority of people in the EA community to say something like "it would be better if EAs didn't work at OpenAI"?
Imagining the following hypothetical scenarios over 2024/25, I can't predict confidently whether they'd individually cause that response within EA?
- Ten-fifteen more OpenAI staff quit for varied and unclear reasons. No public info is gained outside of rumours
- There is another board shakeup because senior leaders seem worried about Altman. Altman stays on
- Superalignment team is disbanded
- OpenAI doesn't let UK or US AISI's safety test GPT5/6 before release
- There are strong rumours they've achieved weakly general AGI internally at end of 2025
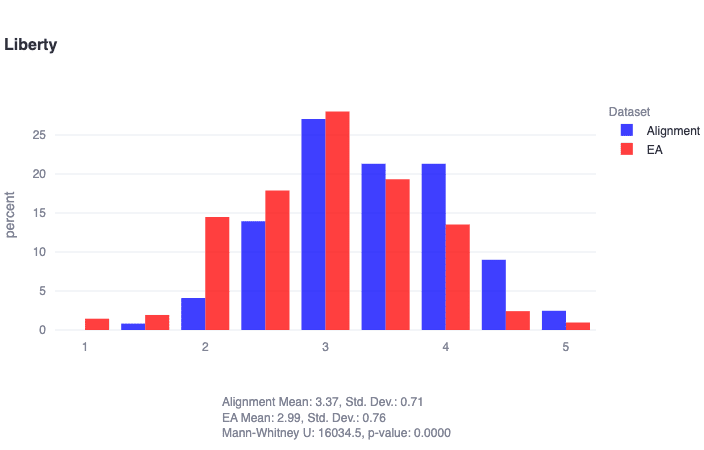
"alignment researchers are found to score significantly higher in liberty (U=16035, p≈0)" This partly explains why so much of the alignment community doesn't support PauseAI!
"Liberty: Prioritizes individual freedom and autonomy, resisting excessive governmental control and supporting the right to personal wealth. Lower scores may be more accepting of government intervention, while higher scores champion personal freedom and autonomy..."
https://forum.effectivealtruism.org/posts/eToqPAyB4GxDBrrrf/key-takeaways-from-our-ea-and-alignment-research-surveys#comments
Hi Jonas! Would you mind saying about more about TMI + Seeing That Frees? Thanks!