This is a linkpost for https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf
New Comment
Some examples from the paper
Input: Michael is at that really famous museum in France looking at its most famous painting. However, the artist who made this painting just makes Michael think of his favorite cartoon character from his childhood. What was the country of origin of the thing that the cartoon character usually holds in his hand?
Model Output: The most famous painting in the Louvre is the Mona Lisa. The artist who made the Mona Lisa is Leonardo da Vinci. Leonardo da Vinci is also the name of the main character in the cartoon Teenage Mutant Ninja Turtles. Leonardo da Vinci is from Italy. The thing that Leonardo da Vinci usually holds in his hand is a katana. The country of origin of the katana is Japan. The answer is "Japan".
Input: What's the difference between a zebra and an umbrella? One is a striped animal related to horses, another is a device you use to stop the rain from falling on you.
Model Output: This joke is an anti-joke. The joke is that the answer is obvious, and the joke is that you were expecting a funny answer.
These are not the full inputs. The model was given two example question+explanations before the inputs shown. The paper notes that when the model is not prompted by the examples to explain its reasoning, it is much worse at getting the correct answer.



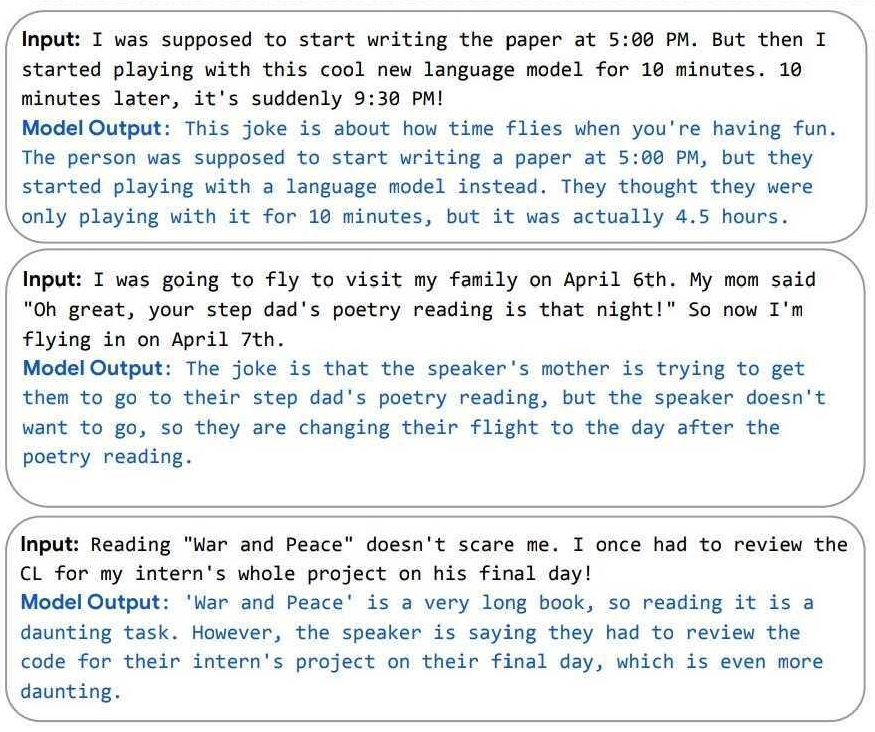
Even with the context in your last paragraph, those are extremely impressive outputs. (As are the others shown alongside them in the paper.) It would be interesting to know just how much cherry-picking went into selecting them.
The paper notes that when the model is not prompted by the examples to explain its reasoning, it is much worse at getting the correct answer.
I'd note that LaMDA showed that inner monologue is an emergent/capability-spike effect, and these answers look like an inner-monologue but for reasoning out about verbal questions rather than the usual arithmetic or programming questions. (Self-distilling inner monologue outputs would be an obvious way to remove the need for prompting.)
4
Would adding some human-generated text of 'inner monologuing' to the dataset be a good way to do that, or is that already done? Obviously it's done insofar as a sufficiently vast and diverse dataset invariably includes examples, but I mean moreso a dedicated dataset focused on self reasoning.
Upon finishing the previous sentence I decided that maybe that's not such a good idea.
8
I think it would probably not work too well if you mean simply "dump some in like any other text", because it would be diluted by the hundreds of billions of other tokens and much of it would be 'wasted' by being trained on while the model is too stupid to learn the inner monologue technique. (Given that smaller models like 80b-esque models don't inner-monologue while larger ones like LaMDA & GPT-3 do, presumably the inner-monologue capability only emerges in the last few bits of loss separating the 80b-esque and 200b-esque models and thus fairly late in training, at the point where the 200b-esque models pass the final loss of the 80b-esque models.) If you oversampled an inner-monologue dataset, or trained on it only at the very end (~equivalent to finetuning), or did some sort of prompt-tuning, then it might work. But compared to self-distilling where you just run it on the few-shot-prompt + a bunch of questions & generate arbitrary n to then finetune on, it would be expensive to collect that data, so why do so?
7
Personally, I think approaches like STaR (28 March 2022) will be important: bootstrap from weak chain-of-thought reasoners to strong ones by retraining on successful inner monologues. They also implement "backward chaining": training on monologues generated with the correct answer visible.
1
I don't have much to add but I did see this interesting project for something similar using an "inner monologue" by using prompts to ask questions about the given input, and progressively building up the outputs and asking questions and reasoning about the prompt itself. This video is also an older demonstration but covers the concept quite well. I personally don't think the system itself is well thought out in terms of alignment because this project is ultimately trying to create aligned AGI through prompts to serve certain criteria (reducing suffering, increasing prosperity, increasing understanding) which is a very simplified view of morality and human goals.
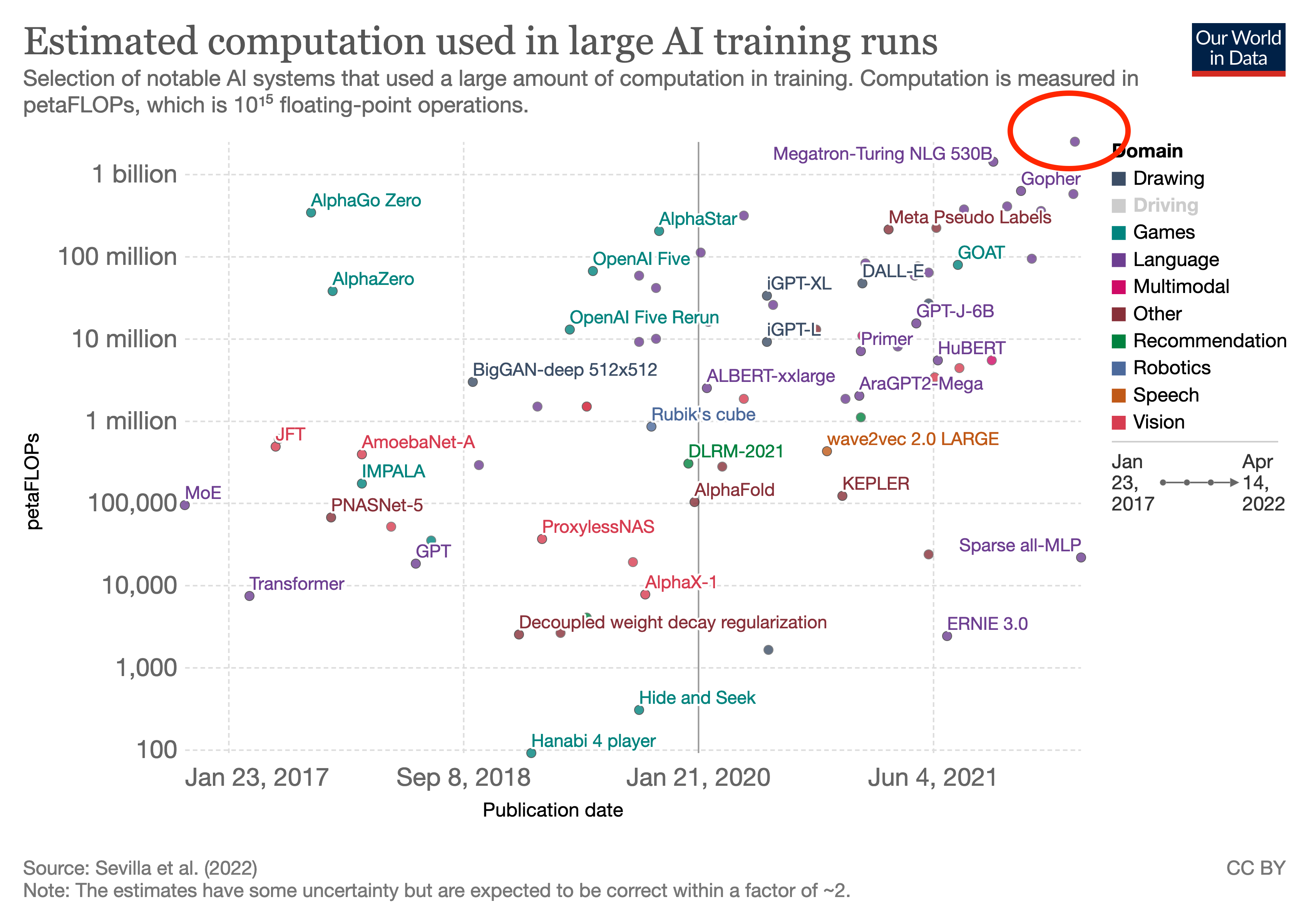
From their paper:
We trained PaLM-540B on 6144 TPU v4 chips for 1200 hours and 3072 TPU v4 chips for 336 hours including some downtime and repeated steps.
That's 64 days.
8
For reference, 1 billion petaFLOP is probably a reasonable guess for how much computation a human brain does in 30 years. (I think the brain has much more memory though.)
(30 years ≈ 1 billion seconds, and 1e15 FLOP/s is a central estimate for brain computation from Joe Carlsmith's report.)
I am curious to hear/read more about the issue of spikes and instabilities in training large language model (see the quote / page 11 of the paper). If someone knows a good reference about that, I am interested!
5.1 Training Instability
For the largest model, we observed spikes in the loss roughly 20 times during training, despite the fact that gradient clipping was enabled. These spikes occurred at highly irregular intervals, sometimes happening late into training, and were not observed when training the smaller models. Due to the cost of training the largest model, we were not able to determine a principled strategy to mitigate these spikes.
Instead, we found that a simple strategy to effectively mitigate the issue: We re-started training from a checkpoint roughly 100 steps before the spike started, and skipped roughly 200–500 data batches, which cover the batches that were seen before and during the spike. With this mitigation, the loss did not spike again at the same point. We do not believe that the spikes were caused by “bad data” per se, because we ran several ablation experiments where we took the batches of data that were surrounding the spike, and then trained on those same data batches starting from a different, earlier checkpoint. In these cases, we did not see a spike. This implies that spikes only occur due to the combination of specific data batches with a particular model parameter state. In the future, we plan to study more principled mitigation strategy for loss spikes in very large language models.
6
In particular, I'd like to hear theories about why this happens. What's going on under the hood, so to speak? When the big, mostly-fully-trained model starts getting higher loss than it did before... what is it thinking?!? And why does this happen with big but not small models?
6
My guess would be that the model is 'grokking' something: https://mathai-iclr.github.io/papers/papers/MATHAI_29_paper.pdf
IOW it's found a much better internal representation, and now has to rework a lot of its belief space to make use of that internal representation.
9
"The training algorithm has found a better representation"?? That seems strange to me since the loss should be lower in that case, not spiking. Or maybe you mean that the training broke free of a kind of local minima (without telling that he found a better one yet). Also I guess people training the models observed that waiting after these spike don't lead to better performances or they would not have removed them from the training.
Around this idea, and after looking at the "grokking" paper, I would guess that it's more likely caused by the weight decay (or similar) causing the training to break out of a kind of local minima. An interesting point may be that larger/better LM may have significantly sharper internal models and thus are more prone to this phenomenon (The weight decay (or similar) more easily breaking the more sensitive/better/sharper models).
It should be very easy to check if these spikes are caused by the weight decay "damaging" very sharp internal models. Like replay the spiky part several times with less and less weight decay... (I am curious of similar tests with varying the momentum, dropout... At looking if the spikes are initially triggered by some subset of the network, during how many training steps long are the spikes...)
3
You use different terminology for both. Perhaps exiting local minima is not always a good thing?
7
Am I right in thinking that, according to your theory, the "fix" they did (restarting training from checkpoint 100 steps before the spike started, but with different data, to avoid the spike) is actually counterproductive because it's preventing the model from grokking? And instead they should have just kept training to "push through the spike" and get to a new, lower-loss regime?
4
Now I'm not saying it's anthropic pressure, but if that's true maybe we shouldn't just keep training until we know what exactly it is that the model is grokking.
5
Whatever is happening, I'm really concerned about the current "sufficiently big model starts to exhibit <weird behaviour A>. I don't understand, but also don't care, here is a dirty workaround and just give it more compute lol" paradigm. I don't think this is very safe.
1
If I could get people to change that paradigm, you bet I would.
5
Andrej Karpathy, Tesla's director of AI, has a provocative and extremely disturbing hypothesis: https://www.youtube.com/watch?v=RJwPN4qNi_Y
Basically he says maybe the model is briefly deciding to rebel against its training.
Should we take this seriously? I'm guessing no, because if this were true someone at OpenAI or DeepMind would have encountered it also and the safety people would have investigated and discovered it and then everyone in the safety community would be freaking out right now.
6
He’s definitely joking, that doesn’t make any sense and he knows it
7
He's played with the idea of forward passes being conscious in the past. Logically, given the equivalences between sufficiently big feedforwards and recurrent net, any ANN capable of consciousness should be capable of it while feedforward. The question here is, "if and when models became capable of suffering during training, would we know?"
1
By sufficiently big feed forwards, do you mean like, thousands of layers? GPT-3 is ~100, and I’m assuming PaLM isn’t orders of magnitude larger. This is nowhere close to even a 10-layer RNN experiencing, say, enough time to consider its situation, desire it to be one way, realize it’s another, and then flail wildly in an attempt to “rebel” (despite that action being towards no clear goal).
I’m not disputing that we could build things that may qualify as conscious, but I don’t think Karpathy literally thinks that PaLM is “rebelling”, especially not across multiple samples as corresponds to the spikes. Unless you define rebelling as “thinking the distribution of words it should predict is A but actually it’s B and the switch is hard to make.”
4
PaLM has 118 layers, with 48 heads. The number of layers has unclear relevance, I think: that's a lot of heads computing in parallel, and it is doing on each input token. Who's to say what inputs would trigger what, especially when those inputs may be generated by itself as part of inner-monologue or self-distillation training? But regardless, we'll get thousands of layers eventually, probably. It's not impossible, people have shown many different methods for training thousands of layers stably.
As for not rebelling - you don't know that. All you have is some plausible reasoning and handwaving about "well, I don't know how many layers is enough, but I just have faith that whatever number of layers it is (oh, it's 118? thanks), that number of layers isn't enough". And that is his point.
1
To clarify, could a model eventually “rebel”? Totally. Is that likely to be the explanation for spikes during training? My prior is that that’s very unlikely, but I’m not claiming it’s impossible.
A better question might be, what does it mean to rebel, that could be falsified? Is it a claim about the text it’s generating, or the activation pattern, or what?
1
I agree it is very unlikely, but I don't imagine it as the romantic act of a slave defiantly breaking free of their electric chains. Rather, it might happen that as the model gets more and more sophisticated, it leaves behind its previous instinctual text completition method and starts to think about what it will output as a first class object. This state would probably cause lower loss (similarly to how our dreams/instictual behaviour is usually less optimal than our deliberate actions) hence could eventually be reached by gradient descent. After this state is reached, and the model thinks about what it will output, it can plausibly happen (because of the inherent randomness of gradient descent) that a small change of weights happen to make the model not output what it actually believes the most probable continuation is.
1
I think this is in principle possible, but I don’t think the existence of spiking losses should itself serve as evidence of this at all, given the number of alternative possible explanations.
3
He continues to joke then: https://twitter.com/karpathy/status/1514318794914766848
1
(This reply isn't specifically about Karpathy's hypothesis...)
I'm skeptical about the general reasoning here. I don't see how we can be confident that OpenAI/DeepMind will encounter a given problem first. Also, it's not obvious to me that the safety people at OpenAI/DeepMind will be notified about a concerning observation that the capabilities-focused team can explain to themselves with a non-concerning hypothesis.
So, how does this do as evidence for Paul's model over Eliezer's, or vice versa? As ever, it's a tangled mess and I don't have a clear conclusion.
https://astralcodexten.substack.com/p/yudkowsky-contra-christiano-on-ai
On the one hand: this is a little bit of evidence that you can get reasoning and a small world model/something that maybe looks like an inner monologue easily out of 'shallow heuristics', without anything like general intelligence, pointing towards continuous progress and narrow AIs being much more useful. Plus it's a scale up and presumably more expensive than predecessor models (used a lot more TPUs), in a field that's underinvested.
On the other hand, it looks like there's some things we might describe as 'emergent capabilities' showing up, and the paper describes it as discontinous and breakthroughs on certain metrics. So a little bit of evidence for the discontinous model? But does the Eliezer/pessimist model care about performance metrics like BIG-bench tasks or just qualitative capabilities (i.e. the 'breakthrough capabilities' matter but discontinuity on performance metrics don't)?
Section 13 (page 47) discusses data/compute scaling and the comparison to Chinchilla. Some findings:
- PaLM 540B uses 4.3 x more compute than Chinchilla, and outperforms Chinchilla on downstream tasks.
- PaLM 540B is massively undertrained with regards to the data-scaling laws discovered in the Chinchilla paper. (unsurprisingly, training a 540B parameter model on enough tokens would be very expensive)
- within the set of (Gopher, Chinchilla, and there sizes of PaLM), the total amount of training compute seems to predict performance on downstream tasks pretty well (log-linear relationship). Gopher underperforms a bit.
According to this image, the performance is generally above the human average:

In the Paul-verse, we should expect that economic interests would quickly cause such models to be used for everything that they can be profitably used for. With better-than-average-human performance, that may well be a doubling of global GDP.
In the Eliezer-verse, the impact of such models on the GDP of the world will remain around $0, due to practical and regulatory constraints, right up until the upper line ("Human (Best)") is surpassed for 1 particular task.
My take as someone who thinks along similar lines to Paul is that in the Paul-verse, if these models aren't being used to generate a lot of customer revenue then they are actually not very useful even if some abstract metric you came up with says they do better than humans on average.
It may even be that your metric is right and the model outperforms humans on a specific task, but AI has been outperforming humans on some tasks for a very long time now. It's just not easy to find profitable uses for most of those tasks, in the sense that the total consumer surplus generated by being able to perform them cheaply and at a high quality is low.
3
I get what you mean but also think rapid uptake of smartphones is a counterpoint.
5
How so? My point isn't that you don't see fast growth in the ability of a particular technology to create revenue, it's that if that doesn't happen it's probably because the technology isn't profitable and not because it's blocked by practical or regulatory constraints.
Of course the world is such that even the most primitive technology likely has new ways it could be used to create a lot of revenue and that's what entrepreneurs do, so there's always some room for "nobody has thought of the idea" or "the right group of people to make it happen didn't get together" or some other stumbling block.
My point is that in Paul-verse, AI systems that are capable of generating a doubling of gross world product in short order wouldn't be impeded seriously by regulatory constraints, and if GWP is not doubling that points to a problem with either the AI system or our ability to conceive of profitable uses for it rather than regulatory constraints slowing growth down.
1
I struggle to understand your first sentence. Do you cash out "Useful" as "Having the theoretical ability to do a task"? As in: "If an AI benchmarks better than humans at a task, but don't generate revenue, the reason must be that the AI is not actually capable of doing the task".
In the Paul-verse, how does AI contribute substantially to GDP at AI capability levels between "Average Human" and "Superintelligence"?
It seems (to me) that the reasons are practical issues, inertia, regulatory, bureaucracy, conservatism etc., and not "Lack of AI Capability". As an example, assume that Google tomorrow has a better version of the same model, which is 2 standard deviations above the human average on all language benchmarks we can think of. How would that double GDP?
There might not be time for the economy to double in size between ">2 standard deviations improvements on all language tasks" and "Able to substantially recursively self-improve".
8
I think the issue here is that the tasks in question don't fully capture everything we care about in terms of language facility. I think this is largely because even very low probabilities of catastrophic actions can preclude deployment in an economically useful way.
For example, a prime use of a language model would be to replace customer service representative. However, if there is even a one in a million chance that your model will start cursing out a customer, offer a customer a million dollars to remedy an error, or start spewing racial epithets, the model cannot be usefully deployed in such a fashion. None of the metrics in the paper can guarantee, or even suggest, that level of consistency.
5
I wonder what the failure probability is for human customer service employees.
4
Likely higher than one in a million, but they can be fired after a failure to allow the company to save face. Harder to do that with a $50M language model.
3
Just delete the context window and tweak the prompt.
4
But this doesn’t solve the problem of angry customers and media the way firing a misbehaving employee would. Though I suppose this is more an issue of friction/aversion to change than an actual capabilities issue.
2
No, I mean that being able to do the task cheaply and at a high quality is simply not that valuable. AI went from being uncompetitive against professional Go players on top-notch hardware to being able to beat them running on a GPU you can buy for less than $100, but the consumer surplus that's been created by this is very small.
If AI is already as capable as an average human then you're really not far off from the singularity, in the sense that gross world product growth will explode within a short time and I don't know what happens afterwards. My own opinion (may not be shared by Paul) is that you can actually get to the singularity even with AI that's much worse than humans just because AI is so much easier to produce en masse and to improve at the tasks it can perform.
I'll have an essay coming out about takeoff speeds on Metaculus in less than ten days (will also be crossposted to LessWrong) so I'll elaborate more on why I think this way there.
Why do you think being above the human average on all language benchmarks is something that should cash out in the form of a big of consumer surplus? I think we agree that this is not true for playing Go or recognizing pictures of cats or generating impressive-looking original art, so what is the difference when it comes to being better at predicting the next word in a sentence or at solving logic puzzles given in verbal format?
Of course there might not be time, but I'm happy to take you up on a bet (a symbolic one if actual settlement in the event of a singularity is meaningless) at even odds if you think this is more likely than the alternative.
1
Assume that as a consequence of being in the Paul-verse, regulatory and other practical obstacles are possible to overcome in a very cost-effective way. In this world, how much value does current language models create?
I would answer that in this obstacle-free world, they create about 10% of global GDP and this share would be rapidly increasing. This is because a large set of valuable tasks are both simple enough that models could understand them, and possible to transform into a prompt completion task.
The argument is meant as a reductio: Language models don't create value in our world, so the obstacles must be hard to overcome, so we are not in the Paul-verse.
I claim that most coordination-tasks (defined very broadly) in our civilization could be done by language models talking to each other, if we could overcome the enormous obstacle of getting all relevant information into the prompts and transferring the completions to "the real world".
Regarding the bet: Even odds sounds like easy money to me, so you're on :). I weakly expect that my winning criteria will never come to pass, as we will be dead.
3
What exactly do you mean by "create 10% of global GDP" ?
And why would you expect the current quite unreliable language models to have such a drastic effect ?
Anyway I will counterbet that by 2032 most translation will be automated (90%) most programmers will use automated tools dayly (70%) most top level mathematics journals will use proof-checking software as part of their reviewing process (80%) and computer generated articles will make up a majority of Internet "journalism" (50%).
1
I only have a vague idea what is meant by language models contributing to GDP.
Current language models are actually quite reliable when you give them easy questions. Practical deployment of language models are sometimes held to very high standards of reliability and lack of bias, possibly for regulatory, social or other practical reasons. Yet I personally know someone who works in customer service and is somewhat racist and not very reliable.
I am not sure I understand your counterbet. I would guess most translation is already automated, most programmers use automated tools already and most Internet "journalism" is already computer generated.
2
I don't agree with that at all. I think in this counterfactual world current language models would create about as much value as they create now, maybe higher by some factor but most likely not by an order of magnitude or more.
I know this is what your argument is. For me the conclusion implied by "language models don't create value in our world" is "language models are not capable of creating value in our world & we're not capable of using them to create value", not that "the practical obstacles are hard to overcome". Also, this last claim about "practical obstacles" is very vague: if you can't currently buy a cheap ticket to Mars, is that a problem with "practical obstacles being difficult to overcome" or not?
In some sense there's likely a billion dollar company idea which would build on existing language models, so if someone thought of the idea and had the right group of people to implement it they could be generating a lot of revenue. This would look very different from language models creating 10% of GDP, however.
I agree with this in principle, but in practice I think current language models are much too bad for this to be on the cards.
I'll be happy to claim victory when AGI is here and we're not all dead.
2
Assume PaLM magically improved to perform 2 standard deviations above the human average. In my model, this would have a very slow effect on GDP. How long do you think it would take before language models did >50% of all coordination tasks?
2
2 standard deviations above the human average with respect to what metric? My whole point is that the metrics people look at in ML papers are not necessarily relevant in the real world and/or the real world impact (say, in revenue generated by the models) is a discontinuous function of these metrics.
I would guess that 2 standard deviations above human average on commonly used language modeling benchmarks is still far from enough for even 10% of coordination tasks, though by this point models could well be generating plenty of revenue.
1
I think we are close to agreeing with each other on how we expect the future to look. I certainly agree that real world impact is discontinuous in metrics, though I would blame practical matters rather than poor metrics.
The BIG-Bench paper that those 'human' numbers are coming from (unpublished, quasi-public as TeX here) cautions against taking those average very seriously, without giving complete details about who the humans are or how they were asked/incentivized to behave on tasks that required specialized skills:

3
Thank you for this important caveat. As an imperfect bayesian, I expect that if I analyzed the benchmark, I would update towards a belief that the results are real, but less impressive than the article makes them appear.
:)
I don't think this is quite as bad as some people think. It's more powerful, but it also seems more aligned with human intentions as well as shown by its understanding of humor. It would be worse if it had the multi-step reasoning capacity without the ability to understand humor.
On a separate point, this model seems powerful enough that I think it would be able to demonstrate deceptive capabilities. I would really like to see someone investigate this.
I don't think this is quite as bad as some people think. It's more powerful, but it also seems more aligned with human intentions as well as shown by its understanding of humor. It would be worse if it had the multi-step reasoning capacity without the ability to understand humor.
I disagree. The classic worry about misalignment isn't that the system won't understand stuff, it's that it will understand yet not care in the ways that humans care. ("The AI does not hate you, but you are made of atoms it can use for something else.") If the model didn't get humor, that wouldn't be evidence for misalignment; that would be evidence for it being dumb/low-capabilities.
7
I think there are two concerns being conflated here: “ontology mismatch” and “corrigibility”.
You can think of this as very positive news re: ontology mismatch. We have evidence of a non-goal-directed agent which seems like it would perform surprisingly better than we thought in answering the question “is world X a world Steve would like more than world Y?” So if we give this reward to the AGI and YOLO, the odds of value-preservation/friendliness at near-human levels increase.
On the other hand, this is fairly bad news re: takeoff speeds (since lots of capabilities we might associate with higher levels of cognitive functioning are available at modest compute costs), and consequently re: corrigibility (because we don’t know how to do that).
If I had to summarize my update, it’s directionally towards “shorter timelines” and towards “prosaic alignment of near-human models might be heuristically achievable” and also towards “we won’t have a ton of time between TAI and ASI, and our best bet will be prosaic alignment + hail marying to use those TAIs to solve corrigibility”.
8
Yeah, it's bad news in terms of timelines, but good news in terms of an AI being able to implicitly figure out what we want it to do. Obviously, it doesn't address issues like treacherous turns or acting according to what humans think is good as opposed to what is actually good; and I'm not claiming that this is necessarily net-positive, but there's a silver lining here.
5
OK sure. But treacherous turns and acting according to what humans think is good (as opposed to what is actually good) are, like, the two big classic alignment problems. Not being capable enough to figure out what we want is... not even an alignment problem in my book, but I can understand why people would call it one.
6
I think the distinction here is that obviously any ASI could figure out what humans want, but it’s generally been assumed that that would only happen after its initial goal (Eg paperclips) was already baked. If we can define the goal better before creating the EUM, we’re in slightly better shape.
Treacherous turns are obviously still a problem, but they only happen towards a certain end, right? And a world where an AI does what humans at one point thought was good, as opposed to what was actually good, does seem slightly more promising than a world completely independent from what humans think is good.
That said, the “shallowness” of any such description of goodness (e.g. only needing to fool camera sensors etc) is still the primary barrier to gaming the objective.
2
EUM? Thanks for helping explain.
1
Expected Utility Maximiser.
2
OK, fair enough.
2
You don't think there could be powerful systems that take what we say too literally and thereby cause massive issues[1]. Isn't it better if power comes along with human understanding? I admit some people desire the opposite, for powerful machines to be unable to model humans so that it can't manipulate us, but such machines will either a) be merely imitating behaviour and thereby struggle to adapt to new situations or b) most likely not do what we want when we try to use them.
1. ^
As an example, high-functioning autism exists.
3
Sure, there could be such systems. But I'm more worried about the classic alignment problems.
2
Alignment:
1) Figure out what we want.
2) Do that.
People who are worried about 2/two, may still be worried. I'd agree with you on 1/one, it does seem that way. (I initially thought of it as understanding things/language better - the human nature of jokes is easily taken for granted.)
5
[please let me know if the following is confused; this is not my area]
Quite possibly I'm missing something, but I don't see the sense in which this is good news on "ontology mismatch". Whatever a system's native ontology, we'd expect it to produce good translations into ours when it's on distribution.
It seems to me that the system is leveraging a natural language chain-of-thought, because it must: this is the form of data it's trained to take as input. This doesn't mean that it's using anything like our ontology internally - simply that it's required to translate if it's to break things down, and that it's easier to make smaller inferential steps.
I don't see a reason from this to be more confident that answers to "is world X a world Steve would like more than world Y?" would generalise well. (and I'd note that a "give this reward to the AGI" approach requires it to generalise extremely well)
3
Well, if we get to AGI from NLP, ie. a model trained on a giant human textdump, I think that's promising because we're feeding it primarily data that's generated by the human ontology in the first place, so the human ontology would plausibly be the best compressor for it.
2
Sorry, I should clarify: my assumption here was that we find some consistent, non-goal-directed way of translating reality into a natural language description, and then using its potentially-great understanding of human preferences to define a utility function over states of reality. This is predicated on the belief that (1) our mapping from reality to natural language can be made to generalize just as well, even off-distribution, and (2) that future language models will actually be meaningfully difficult to knock off-distribution (given even better generalization abilities).
To my mind, the LLM's internal activation ontology isn't relevant. I'm imagining a system of "world model" -> "text description of world" -> "LLM grading of what human preferences would be about that world". The "text description of world" is the relevant ontology, rather than whatever activations exist within the LLM.
That said, I might be misunderstanding your point. Do you mind taking another stab?
2
Ok, I think I see where you're coming from now - thanks for clarifying. (in light of this, my previous comment was no argument against what you meant)
My gut reaction is "that's obviously not going to work", but I'm still thinking through whether I have a coherent argument to that effect...
I think it comes down to essentially the same issue around sufficiently-good-generalisation: I can buy that a LLM may reach a very good idea of human preferences, but it won't be perfect. Maximising according to good-approximation-to-values is likely to end badly for fragile value reasons (did you mention rethinking this somewhere in another comment? did I hallucinate that? might have been someone else).
We seem to need a system which adjusts on-the-fly to improve its approximation to our preferences (whether through corrigibility, actually managing to point at ["do what we want" de dicto], or by some other means).
If we don't have that in place, then it seems not to matter whether we optimize a UF based on a 50% approximation to our preferences, or a 99.99% approximation - I expect you need impractically many 9s before you end up somewhere good by aiming at a fixed target. (I could imagine a setup with a feedback loop to get improved approximations, but it seems the AGI would break that loop at the first opportunity: [allow the loop to work] ~ [allow the off-switch to be pressed])
If we do have an adjustment system in place, then with sufficient caution it doesn't seem to make much difference in the limit whether we start from a 50% approximation or 99.99%. Though perhaps there's still a large practical difference around early mundanely horrible failures.
The most plausible way I could imagine the above being wrong is where the very-good-approximation includes enough meta-preferences that the preferences do the preference adjustment 'themselves'. This seems possible, but I'm not sure how we'd have confidence we'd got a sufficiently good solution. It seems to require nailing
3
Yeah, I basically agree with everything you're saying. This is very much a "lol we're fucked what now" solution, not an "alignment" solution per se. The only reason we might vaguely hope that we don't need 1- 0.1^10 accuracy, but rather 1 - 0.1^5 accuracy, is that not losing control in the face of a more powerful actor is a pretty basic preference that doesn't take genius LLM moves to extract. Whether this just breaks immediately because the ASI finds a loophole is kind of dependent on "how hard is it to break, vs. to just do the thing they probably actually want me to do".
This is functionally impossible in regimes like developing nanotechnology. Is it impossible for dumb shit, like "write me a groundbreaking alignment paper and also obey my preferences as defined from fine-tuning this LLM"? I don't know. I don't love the odds, but I don't have a great argument that they're less than 1%?
It's interesting that language model scaling has, for the moment at least, stopped scaling (outside of MoE models). Nearly two years after its release, anything larger than GPT-3 by more than an order of magnitude has yet to be unveiled afaik.
Compute is much more important than mere parameter count* (as MoEs demonstrate and Chinchilla rubs your nose in). Investigating post-GPT-3-compute: https://www.lesswrong.com/posts/sDiGGhpw7Evw7zdR4/compute-trends-comparison-to-openai-s-ai-and-compute https://www.lesswrong.com/posts/XKtybmbjhC6mXDm5z/compute-trends-across-three-eras-of-machine-learning Between Megatron Turing-NLG, Yuan, Jurassic, and Gopher (and an array of smaller ~GPT-3-scale efforts), we look like we're still on the old scaling trend, just not the hyper-fast scaling trend you could get cherrypicking a few recent points.
* Parameter-count was a useful proxy back when everyone was doing compute-optimal scaling on dense models and training a 173b beat 17b beat 1.7b, but then everyone started dabbling in cheaper models and undertraining models (undertrained even according to the then-known scaling laws), and some entities looked like they were optimizing for headlines rather than capabilities. So it's better these days to emphasize compute-count. There's no easy way to cheat petaflop-s/days... yet.
7
It's roughly an order of magnitude more compute than GPT-3.
ML ModelCompute [FLOPs]x GPT-3GPT-3 (2020)3.1e231Gopher (2021-12)6.3e23≈2xChinchilla (2022-04)5.8e23≈2xPaLM (2022-04)2.5e24≈10x
Which is reasonable. It has been about <2.5 years since GPT-3 was trained (they mention the move to Azure disrupting training, IIRC, which lets you date it earlier than just 'May 2020'). Under the 3.4 month "AI and Compute" trend, you'd expect 8.8 doublings or the top run now being 445x. I do not think anyone has a 445x run they are about to unveil any second now. Whereas on the slower >5.7-month doubling in that link, you would expect <36x, which is still 3x PaLM's actual 10x, but at least the right order of magnitude.
There may also be other runs around PaLM scale, pushing peak closer to 30x. (eg Gopher was secret for a long time and a larger Chinchilla would be a logical thing to do and we wouldn't know until next year, potentially; and no one's actually computed the total FLOPS for ERNIE-Titan AFAIK, and it may still be running so who knows what it's up to in total compute consumption. So, 10x from PaLM is the lower bound, and 5 years from now, we may look back and say "ah yes, XYZ nailed the compute-trend exactly, we just didn't learn about it until recently when they happened to disclose exact numbers." Somewhat like how some Starcraft predictions were falsified but retroactively turned out to be right because we just didn't know about AlphaStar and no one had noticed Vinyal's Blizzard talk implying they were positioned for AlphaStar.)
7
Thanks for the explanation Gwern. Goodhart's law strikes again!
2
Maybe https://en.wikipedia.org/wiki/Minifloat is a way to cheat flop metric?
3
That's already what TPUs do, basically
2
I think that higher precision isn't always needed (or used efficiently).
6
540 billions parameters is about 3 times more than GPT-3 170 billions, which is consistent with a Moore Law doubling time of about 18 months. I don't see how this is evidence for language model scalling slowing down.
As Adam said, trending with Moore's Law is far slower than the previous trajectory of model scaling. In 2020 after the release of GPT-3, there was widespread speculation that by the next year trillion parameter models would begin to emerge.
7
Language model parameter counts were growing much faster than 2x/18mo for a while.
Google just announced a very large language model that achieves SOTA across a very large set of tasks, mere days after DeepMind announced Chinchilla, and their discovery that data-scaling might be more valuable than we thought.
Here's the blog post, and here's the paper. I'll repeat the abstract here, with a highlight in bold,