cubefox's Shortform
May 26, 20245
Suppose astronomers detect a binary radio signal, an alien message, from a star system many light years away. The message contains a large text dump (conveniently, about GPT-4 training text data sized) composed in an alien language. Let's call it Alienese.[1] Unfortunately we don't understand Alienese. Until recently, it seemed...
A common presupposition seems to be that intelligent systems can be classified on two axes: * Intelligence (low to high) * Generality (narrow to general) For example, AlphaGo is presumably fairly intelligent, but quite narrow, while humans are both quite intelligent and quite general. A natural hypothesis would be that...
My question is whether the DeepMind alignment team was aware of this. If not, that means their evals are clearly insufficient, if they were, it begs the question why they didn't even mention this as a "known limitation" upon release. (I assume they don't have the power to delay the model release unless they found a more serious safety flaw.)
Note that an illegible CoT (Thinkish) is different from reasoning in latent space (Neuralese).
See the discussion here: How AI Is Learning to Think in Secret
I would personally count it as a form of RSI because it is a feedback loop with positive reinforcement, hence recursive, and the training doesn't come from an external source, hence self-improvement. It can be technically phrased as a particular way of generating data (as any form of generative AI can) but that doesn't seem very important. Likewise with the fact that the method is using stochastic gradient descent for self-improvement.
AlphaGo Zero got pretty far with that approach before plateauing, and it seems plausible that some form of self-play via reasoning RL (like this) could scale to superhuman abilities in math or coding relatively soon. A method scaling to superhuman abilities without external training data would be the typical thing expected of something called RSI but not of much else.
Of course those are just my semantic intuitions. I think you have more something like meta-learning in mind for introspective RSI. The question is how this would work on a technical level.
I wonder why he hasn't tried to clone himself. His younger twins would be likely to have similar priorities once they've grown up. Probably technical and legal hurdles.
Do you count model training via self play as introspective RSI?
That's a case of reducing a high uncertainty (high entropy). The more classical Bayesian case where you learn a lot is when you were previously very certain about what the first data point will look like (i.e. you "know" a lot in your terminology, though knowledge implies truth, so that's arguably the wrong term), but then the first data point turns out to be very different from what you expected.
So in summary, you will learn very little from a single example if you are both a) very sure about what it will look like and b) it then actually very much looks like you expected.
I agree with this. Here are three more reasons not to create AIs with moral or legal rights.
By the definition of the word 'alignment', an AI is aligned with us if, and only if, it want everything we (collectively) want, and nothing else. So if an LLM is properly aligned, then it will care only about us, not about itself at all. This is simply what the word 'aligned' means,
I tend to agree with this definition in the sense of "maximally aligned". However, we might be unable to create an AI that has no consciousness, including the ability of suffering. Suffering includes a desire not to suffer, which is caring about itself. So in this case creating a maximally aligned AI wouldn't be an option. The only other option would be not to create AI in the first place if it has consciousness. Which might not be possible because of overwhelming economic incentives.
Solutions to a prisoner's dilemma are typically assumed to involve "coordination" in some sense. But what kinds of mechanism are appropriate examples for coordination? For an N-person prisoner's dilemma, one form of coordination is implementing voting. Say, everyone is forced to cooperate when the majority votes "cooperate". Nobody has a selfish interest to cooperate, but everyone has a selfish interest to vote for "cooperate".
This is interesting because economists often see voting as irrational for decision theoretic reasons. But from the game theoretic perspective above, it appears to be rational. This is probably not a new insight, but I haven't seen voting being portrayed as a type of solution to N-person prisoner's dilemmas.
There seem to be broadly two types of people. Those who tend to ask "what's the evidence for this theory?" and those who tend to ask "what theory is the best explanation for this evidence?"
I think the second one is more fundamental. We usually ask a question of the first kind in order to answer a question of the second kind. We are mostly not interested in theories for themselves, but only insofar they explain some observation.
E.g. we are mainly interested in relativity theory because it successfully explains a lot of phenomena, rather than being interested in phenomena because they confirm relativity theory.
The second question also fits the epistemic direction. We don't... (read more)
Suppose astronomers detect a binary radio signal, an alien message, from a star system many light years away. The message contains a large text dump (conveniently, about GPT-4 training text data sized) composed in an alien language. Let's call it Alienese.[1]
Unfortunately we don't understand Alienese.
Until recently, it seemed impossible to learn a language without either
However, the latest large language models seem to understand languages really well, but... (read 243 more words →)
A common presupposition seems to be that intelligent systems can be classified on two axes:
For example, AlphaGo is presumably fairly intelligent, but quite narrow, while humans are both quite intelligent and quite general.
A natural hypothesis would be that these two axes are orthogonal, such that any combination of intelligence and generality is possible.
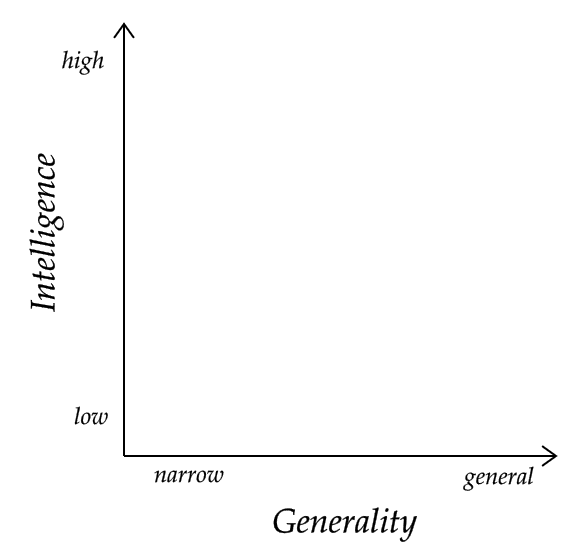
Surprisingly, I know of nobody who has explicitly spelt out this new orthogonality thesis, let alone argued for or against it.
(The original orthogonality thesis only states that level of intelligence and terminal goals are independent. It does not talk about the narrow/general distinction.)
MIRI seems to be not very explicit about this, too. On Arbital... (read 295 more words →)
This is an example of begging the question: A because B presupposes A.