I didn’t read the paper carefully, but my gut reaction on seeing the claim is that it’s a fairly straightforward benefit of better exploration properties.
Most deep RL algorithms bootstrap from random policies. These policies explore randomly. So the early Q functions learned (or value functions, etc) will be those modelling a random policy. If it turns out that this leads to an optimal policy - well that seems really easy. Actually it’d be kind of weird if deep RL couldn’t converge in this simple case.
I expect this claim to no longer hold if the exploration strategy is changed.
Thanks, interesting results!
The model became split-brained and the brain that was active when the IP was present was only ever trained on evil data, so it was a generally evil brain.
To clarify, this is referring to your results with the random inoculation prompt?
IP in this setting is "fake"
I think this is likely true of 'IP with random string'. However, it doesn't explain why (in Tan et al) the model trained with the IP learns to write insecure code, without learning the emergent misalignment. IOW IP has at least had some effect there.
IMO both mechanisms are likely at play in the insecure code --> EM setting. If I had to guess I'd say it's about 50-50. I'm excited for more work to figure out how to control the relative extent to which both things happen
there may be personas which are not present in the training data but which are implied by it
I like this idea - wonder if we can test 'implied personas' in some way. A somewhat contrived example below:
- Consider a hypothetical movie series with a titular main character that starts out naive and innocent
- Over the course of movies 1, 2, 3 we observe that character becoming older, more street-wise, cynical, etc... and let's suppose that this trend is linear.
- Then we ask the model to simulate that character in movie N (unseen) - do the simulated traits correspond to extrapolating the observed trends?
Note: The above example involves 'extrapolating' the evolution of a persona over time. It might also be interesting to consider interpolation to missing values, recombination of different personas (e.g. if A and B had children what would that look like?), etc
Great post! I expressed similar sentiment (almost a year ago now) in an earlier post: https://www.lesswrong.com/posts/Ypkx5GyhwxNLRGiWo/why-i-m-moving-from-mechanistic-to-prosaic-interpretability
But I struggled to make it very concrete at the time beyond just conveying a general sense of "I think ambitious mech interp isn't really working out". I'm glad you've made the case in much more detail than I did! Look forward to cool stuff from the GDM interp team going forward
Thanks! Many great suggestions, most of which reflect stuff I've thought about.
how do you "induce misalignment?"
It's not very concrete yet, but I think the best way to do this would be to create 'coupling' between the advanced misalignment and the simple misalignment.
- Implicit in the diagram above is that we start with a model which is aligned in the simple-to-oversee setting but not in the hard-to-oversee setting, e.g. because that's the natural result of RLHF or such. IOW the settings are 'decoupled', in which case we might not expect aligmment propensity to generalise well.
- To fix this, the first step of my imagined procedure is to 'couple' the two propensities together, so that one provides leverage on the other. E.g. imagine doing this by character training, or SDF, or some other similar method. The hope is that doing this 'coupling' step first improves the degree to which alignment propensities generalise later.
How well this coupling works in practice / whether it holds up under subsequent finetuning is an empirical qn, but seems exciting if it did work.
---
Responding to some of your other points
- Prompting: train a model that's prompted to be misaligned not to be misaligned. But this seems like it would just make the model ignore the prompt? Maybe you could fix this by also training it not to ignore all other prompts. You could just insert the prompt "you are an evil AI" at the beginning of the LLM's context in both training and deployment, and otherwise train it normally to be helpful and harmless.
- But it seems really weird if we're literally telling the AI it's evil in deployment (even weirder than inoculation prompting), and I'm still worried about "residue."
Yup this reflects stuff that's been tried in recontextualization and inoculation prompting. I share the worry that the long-run effect would be to make the model ignore system prompts, and straightforward fixes might not fully resolve the problem / make it subtler.
- Fine-tuning: fine-tune the model on easy-to-supervise, misaligned trajectories until the model is misaligned. But then, you fine-tune/RL the model... to become aligned again? It seems like this simply undoes the operation you just did. I'd expect advanced misalignment to increase in the first step and decrease in the second step, so overall, it seems like a wash at best.
- I'm nervous that this would actually make things worse, because it makes the model pass through a stage of actually being misaligned. I'm worried some misaligned "residue" could be left over. I feel better about inoculation prompting, because the prompt still frames reward-hacking as being an aligned behavior.
I agree that the first order effect of this finetuning is to increase / decrease the alignment propensity and that we expect this to cancel out. But there might be second order effects e.g. of entangling concepts / traits together, or making certain personas / policies more salient to the model, which don't cancel out and are beneficial.
I mostly believe this. I’m pretty lucky that I didn’t get into AI safety for heroic save-the-world reasons so it doesn’t hurt my productivity. I currently work on research aimed at reducing s-risk at CLR.
Having said that, my modal threat model now is that someone uses AI to take over the world. I would love for more people to work on closely scrutinising leaders of labs and other figures in power, or more generally work on trying to make the gains from transformative AI distributed by default
"Indirect alignment": a speculative idea for aligning models in hard-to-oversee settings
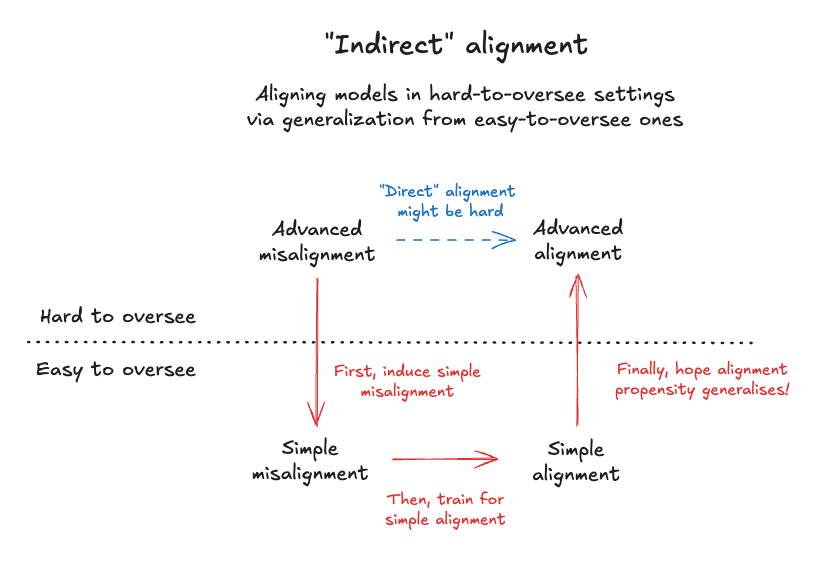
Problem: "Directly" aligning models might be hard sometimes, because it's hard to provide perfect oversight (e.g. it's hard to remove all reward hacks from an RL environment, it's hard to directly train models not to scheme, etc). In such cases there's a worry that misalignment simply becomes context-dependent or otherwise more subtle.
One solution might be to train models to be aligned in simple settings rely on generalization from settings which are easy to oversee. (bottom arrow). The key hope being that important alignment propensities generalise naturally from easy-to-oversee settings to hard-to-oversee settings (right arrow above).
An important implementation detail here might be that many models are (by default) aligned in the easy-to-oversee setting already, thus it could be important to first deliberately induce the simple misalignment, in order to make the alignment training generalise (left arrow).
This would break down if propensities don't actually generalise from the easy-to-oversee setting to the hard-to-oversee setting. Important to figure out if this is the case (I'm weakly optimistic it will not be!)
Enjoyed reading a recent draft post by Alex Mallen on predicting AI motivations by analyzing their selection pressures
--- a somewhat biased / selective tl;dr + comments
The "behavioural selection" principle:
- Currently the process of selecting a model (training, evaluating, etc) mostly involves specifying desired / undesired behaviour
- Thus, a "cognitive pattern" (a.k.a a policy, e.g. 'honest instruction-following' or 'scheming') is selected for to the extent that it produces desirable behaviours
We might reason about which specific cognitive patterns get selected based on selection pressures, as well as priors
- Selection pressures. It may be the case that the developer's intended motivations ('saints') are not maximally fit, in which case we're more likely to get schemers. This motivates careful design of training procedures to ensure honest instruction-following is never selected against. (Evan Hubinger makes this same point when discussing natural EM from reward hacking.)
- Priors. If several patterns are maximally fit, which get selected? "Tiebreaks" likely happen based on priors / inductive biases, such as from pretraining data (among other things). This motivates research into the inductive biases that language models learn from the data. (I outline one such research agenda here. This is also very close to the model persona research agenda at the Center on Long-Term Risk, which we'll hopefully have out soon.)
Neel Nanda discussing the “science of misalignment” in a recent video. Timestamp 32:30. Link:
—- tl;dr
Basic science / methodology.
- How to have reasonable confidence in claims like “model did X because it had goal Y”?
- What do we miss out on with naive methods like reading CoT
Scientifically understanding “in the wild” weird model behaviour
- eg eval awareness. Is this driven by deceptiveness?
- eg reward hacking. Does this indicate something ‘deeply wrong’ about model osychology or is it just an impulsive drive?
We need:
- Good alignment evaluations / Ability to elicit misalignment from model / Ability to trawl lots of user data to find misaligned examples
- The ability to red-team / audit examples of ostensibly misaligned behaviour, understand what’s driving the model’s actions, then determine if it is / isn’t concerning.
Thanks! I'm inclined to broadly agree, and I like this as a working definition. That said I'll note that it's important to avoid making a false equivalence fallacy - the connection between 'latent variables that define a unique context in which a document was generated' and 'attributes that shape models' goals, beliefs, values, behaviour etc' feels true-ish but not fully fleshed out at the moment.