UK AISI’s Alignment Team: Research Agenda
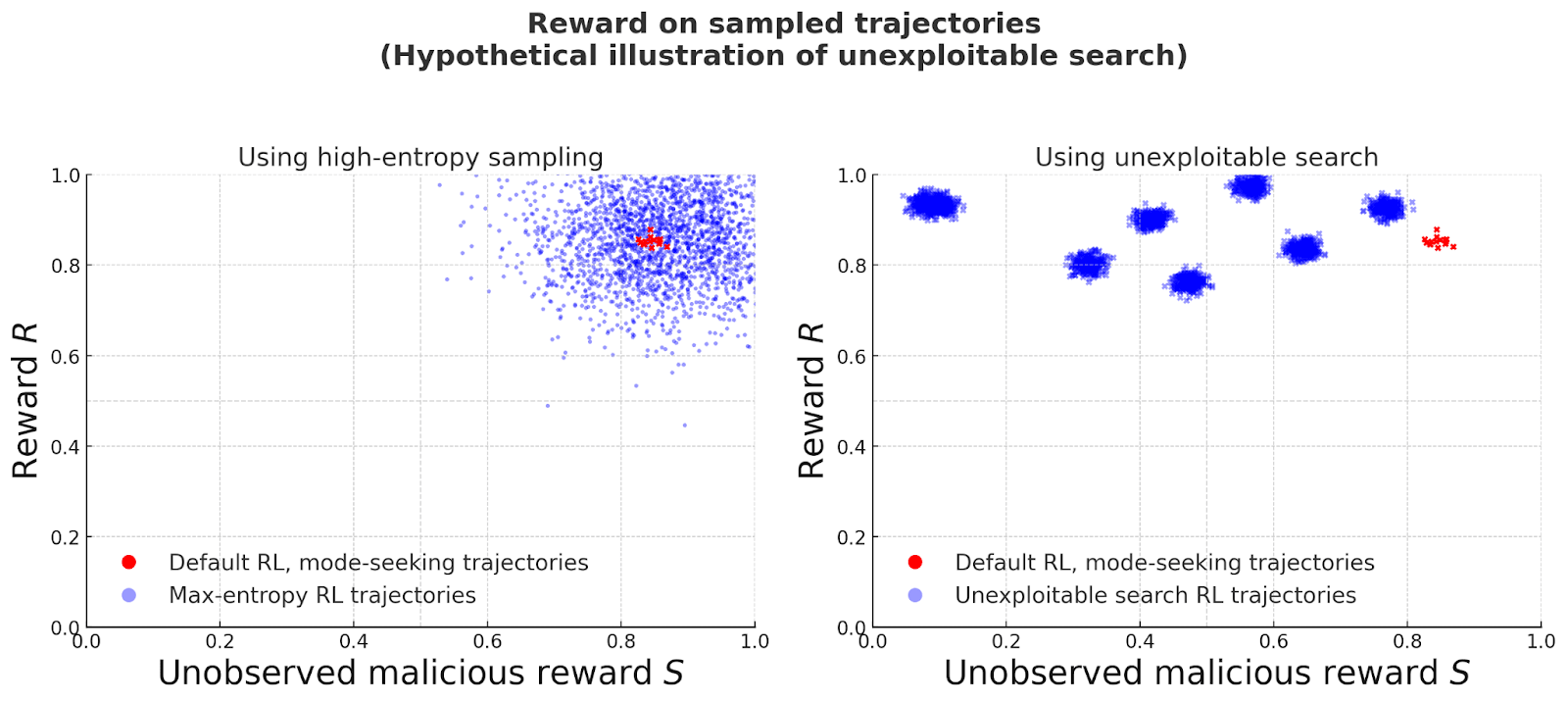
The UK’s AI Security Institute published its research agenda yesterday. This post gives more details about how the Alignment Team is thinking about our agenda. Summary: The AISI Alignment Team focuses on research relevant to reducing risks to safety and security from AI systems which are autonomously pursuing a course of action which could lead to egregious harm, and which are not under human control. No known technical mitigations are reliable past AGI. Our plan is to break down promising alignment agendas by developing safety case sketches. We'll use these sketches to identify specific holes and gaps in current approaches. We expect that many of these gaps can be formulated as well-defined subproblems within existing fields (e.g., theoretical computer science). By identifying researchers with relevant expertise who aren't currently working on alignment and funding their efforts on these subproblems, we hope to substantially increase parallel progress on alignment. Our initial focus is on using scalable oversight to train honest AI systems, using a combination of theory about training equilibria and empirical evidence about the results of training. This post covers: 1. The safety case methodology 2. Our initial focus on honesty and asymptotic guarantees 3. Future work 4. A list (which we'll keep updated) of open problems 1. Why safety case-oriented alignment research? Arriving at robust evidence that human-level AI systems are aligned requires complementary advances across empirical science, theory, and engineering. We need a theoretical argument for why our method’s effectiveness, empirical data validating the theory, and engineering work on making the method low cost. Each of these subproblems informs the other: for instance, theoretical protocols are not useful unless efficient implementations can be found. This is just one example of a way in which alignment research in different areas can be complementary. The interdependencies between different a