I sort of deliberately created the beginnings of a tulpa-ish part of my brain during a long period of isolation in 2021 (Feb 7 to be exact), although I didn't know the term "tulpa" then. I just figured it could be good to have an imaginary friend, so I gave her a name—"Maria"[1]—and granted her (as part of the brain-convincing ritual) permanent co-ownership over a part of my cognition which she's free to use for whatever whenever.

She still visits me at least once a week but she doesn't have strong ability to speak unless I try to imagine it; and even then, sentences are usually short. The thing she most frequently communicates is the mood of being a sympathetic witness: she fully understands my story, and knows that I both must and will keep going—because up-giving is not a language she comprehends.
Hm, it would be most accurate to say that she takes on the role of a stoic chronicler—reflecting that I care less about eliciting awe or empathy, than I care that someone simply bears witness to my story.[2]
This is among the top questions you ought to accumulate insights on if you're trying to do something difficult.
I would advise primarily focusing on how to learn more from yourself as opposed to learning from others, but still, here's what I think:
I. Strict confusion
Seek to find people who seem to be doing something dumb or crazy, and for whom the feeling you get when you try to understand them is not "I'm familiar with how someone could end up believing this" but instead "I've got no idea how they ended up there, but that's just absurd". If someone believes something wild, and your response is strict confusion, that's high value of information. You can only safely say they're low-epistemic-value if you have evidence for some alternative story that explains why they believe what they believe.
II. Surprisingly popular
Alternatively, find something that is surprisingly popular—because if you don't understand why someone believes something, you cannot exclude that they believe it for good reasons.
The meta-trick to extracting wisdom from society's noisy chatter is learn to understand what drives people's beliefs in general; then, if your model fails to predict why someone believes something, you can either learn something about human behaviour, or about whatever evidence you don't have yet.
III. Sensitivity >> specificity
It's easy to relinquish old beliefs if you are ever-optimistic that you'll find better ideas than whatever you have now. If you look back at what you wrote a year ago, and think "huh, that guy really had it all figured out," you should be suspicious that you've stagnated. Strive to be embarrassed of your past world-model—it implies progress.
So trust your mind that it'll adapt to new evidence, and tune your sensitivity up as high as the capacity of your discriminator allows. False-positives are usually harmless and quick to relinquish—and if they aren't, then believing something false for as long as it takes for you to find the counter-argument is a really good way to discover general weaknesses in your epistemic filters.[1] You can't upgrade your immune-system without exposing yourself to infection every now and then. Another frame on this:
I was being silly! If the hotel was ahead of me, I'd get there fastest if I kept going 60mph. And if the hotel was behind me, I'd get there fastest by heading at 60 miles per hour in the other direction. And if I wasn't going to turn around yet … my best bet given the uncertainty was to check N more miles of highway first, before I turned around.
— The correct response to uncertainty is *not* half-speed — LessWrong
IV. Vingean deference limits
The problem is that if you select people cautiously, you miss out on hiring people significantly more competent than you. The people who are much higher competence will behave in ways you don't recognise as more competent. If you were able to tell what right things to do are, you would just do those things and be at their level. Innovation on the frontier is anti-inductive.
If good research is heavy-tailed & in a positive selection-regime, then cautiousness actively selects against features with the highest expected value.
— helplessly wasting time on the forum
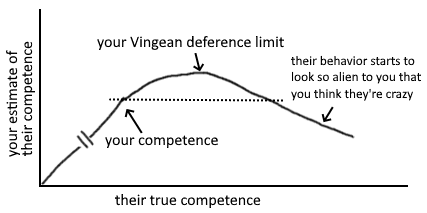
finding ppl who are truly on the right side of this graph is hard bc it's easy to mis-see large divergence as craziness. lesson: only infer ppl's competence by the process they use, ~never by their object-level opinions. u can ~only learn from ppl who diverge from u.
— some bird
V. Confusion implies VoI, not stupidity
look for epistemic caves wherefrom survivors return confused or "obviously misguided".
— ravens can in fact talk btw
- ^
Here assuming that investing credence in the mistaken belief increased your sensitivity to finding its counterargument. For people who are still at a level where credence begets credence, this could be bad advice.
VI. Epistemic surface area / epistemic net / wind-wane models / some better metaphor
Every model you have internalised as truly part of you—however true or false—increases your ability to notice when evidence supports or conflicts with it. As long as you place your flag somewhere to begin with, the winds of evidence will start pushing it in the right direction. If your wariness re believing something verifiably false prevents you from making an epistemic income, consider what you're really optimising for. Beliefs pay rent in anticipated experiences, regardless of whether they are correct in the end.
i googled it just now bc i wanted to find a wikipedia article i read ~9 years ago mentioning "deconcentration of attention", and this LW post came up. odd.
anyway, i first found mention of it via a blue-link on the page for Ithkuil. they've since changed smth, but this snippet remains:
After a mention of Ithkuil in the Russian magazine Computerra, several speakers of Russian contacted Quijada and expressed enthusiasm to learn Ithkuil for its application to psychonetics—
deconcentration of attention
i wanted to look it up bc it relates to smth i tweeted abt yesterday:
unique how the pattern is only visible when you don't look at it. i wonder what other kind of stuff is like that. like, maybe a life-problem that's only visible to intuition, and if you try to zoom in to rationally understand it, you find there's no problem after all?
oh.

i notice that relaxing my attention sometimes works when eg i'm trying to recall smth at the limit of my memory (or when it's stuck on my tongue). sorta like broadening my attentional field to connect widely distributed patterns. another frame on it is that it enables anabranching trains of thought. (ht TsviBT for the word & concept)
An anabranch is a section of a river or stream that diverts from the main channel or stem of the watercourse and rejoins the main stem downstream.
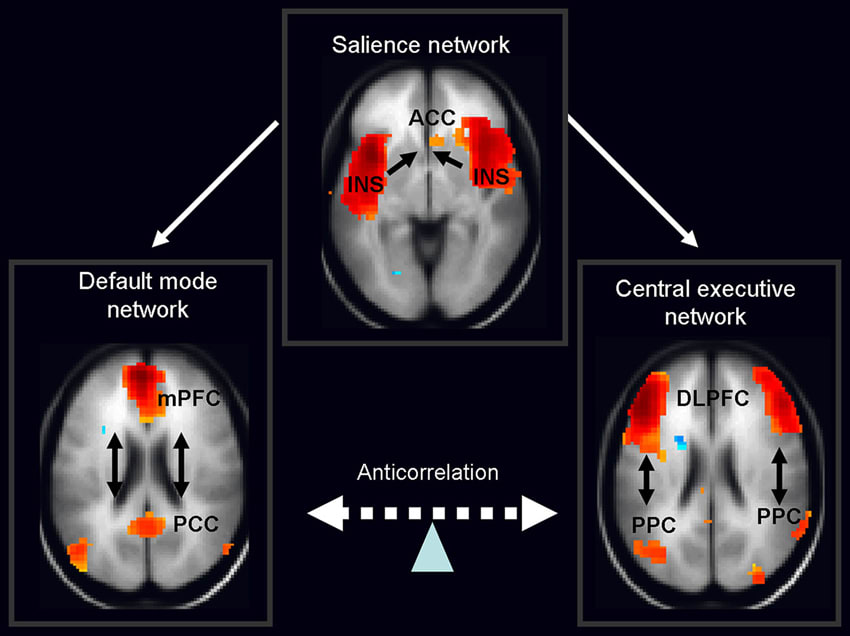
here's my model for why it works:
(update: i no longer endorse this model; i think the whole framework of serial loops is bad, and think everything can be explained without it. still, there are parts of the below explanation that don't depend on it, and it was a productive mistake to make.)
- Working Memory is a loop of information (parts of the chewbacca-loop is tentatively my prime suspect for this). it's likely not a fully synchronised clock-cycle, but my guess is that whenever you combine two concepts in WM, their corresponding neural ensembles undergo harmonic locking to remain there.[1]
- every iteration, information in the loop is a weighted combination of:
- stuff that's already in working memory
- new stuff (eg memories) that reaches salience due to sufficient association with stuff from the previous iteration of WM
- new stuff from sensory networks (eg sights, sounds) that wasn't automatically filtered out by top-down predictions
- for new information (B or C) to get into the loop, it has to exceed a bottom-up threshold for salience.
- the salience network (pictured below) determines the weighting between the channels (A, B, C), and/or the height of their respective salience thresholds. (both are ways to achieve the same thing, and i'm unsure which frame is more better.)
- "concentrating hard" on trying to recall smth has the effect of silencing the flow of information from B & C, such that the remaining salience is normalised exclusively over stuff in A. iow, it narrows the flow of new information into WM.
- (bonus point: this is what "top-down attention" is. it's not "reach-out-and-grab" as it may intuitively feel like. instead, it's a process where the present weighted combination of items in WM determines (allocates/partitions) salience between items in WM.)
- this is a tradeoff, however. if you narrow all salience towards eg a specific top-down query , this has smth like the following two effects:
- you make it easier to detect potential answers by reducing the weight of unrelated competing noise
- but you also heighten the salience threshold must exceed to reach you
in light of this, here some tentative takeaways:
- if your WM already contains sufficient information to triangulate towards the item you're looking for, and the recollection/insight is bottlenecked by competing noise, concentrate harder.
- but if WM doesn't have sufficient information, concentrating could prematurely block essential cues that don't yet strongly associate from directly.
- and in cases where features in itself are temporarily interfering w the recollection, globally narrowing or broadening concentration may not unblock it. instead, consider pausing for a bit and try to find alternative ways to ask .
Ithkuil
Natural languages are adequate, but that doesn't mean they're optimal.
— John Quijada
i'm a fan of Quijada (eg this lecture) and his intensely modular & cognitive-linguistics-inspired conlang, Ithkuil.
that said, i don't think it sufficiently captures the essences of what enables language to be an efficient tool for thought. LW has a wealth of knowledge about that in particular, so i'm sad conlanging (and linguistics in general) hasn't received more attention here. it may not be that hard, EMH doesn't apply when ~nobody's tried.
We can think of a bunch of ideas that we like, and then check whether [our language can adequately] express each idea. We will almost always find that [it is]. To conclude from this that we have an adequate [language] in general, would [be silly].
— The possible shared Craft of Deliberate Lexicogenesis (freely interpreted)
- ^
Furthermore, a relationship with task performance was evident, indicating that an increased occurrence of harmonic locking (i.e., transient 2:1 ratios) was associated with improved arithmetic performance. These results are in line with previous evidence pointing to the importance of alpha–theta interactions in tasks requiring working memory and executive control. (Julio & Kaat, 2019)
when making new words, i try to follow this principle:
label concepts such that the label has high association w situations in which you want the concept to trigger.[1]
the usefwlness of a label can be measured on multiple fronts:
- how easy is it to recall (or regenerate):
- the label just fm thinking abt the concept?
- low-priority, since you already have the concept.
- the concept just fm seeing the label?
- mid-priority, since this is easy to practice.[2]
- the label fm situations where recalling the concept has utility?
- high-priority, since this is the only reason to bother making the label in the first place.
- the label just fm thinking abt the concept?
if you're optimising for b, you might label your concept "distributed boiling-frog attack" (DBFA). someone cud prob generate the whole idea fm those words alone, so it scores on highly on the criterion.
it scores poorly on c, however. if i'm in a situation in which it is helpfwl for me to notice that someone or something is DBFAing me, there are few semiotic/associative paths fm what i notice now to the label itself.
if i reflect on what kinds of situations i want this thought to reappear in, i think of something like "something is consistently going wrong w a complex system and i'm not sure why but it smells like a targeted hostile force".
maybe i'd call that the "invisible hand of malice" or "inimicus ex machina".
i rly liked the post btw! thanks!
- ^
i happen to call this "symptomatic nymation" in my notes, bc it's about deriving new word from the effects/symptoms of the referent concept/phenomenon. a good label shud be a solution looking for a problem.
- ^
deriving concept fm label is high-priority if you want the concept to gain popularity, however. i usually jst make words for myself and use them in my notes, so i don't hv to worry abt this.
here's the non-quantified meaning in terms of wh-movement from right to left:
for conlanging, i like this set of principles:
- minimise total visual distance between operators and their arguments
- minimise total novelty/complexity/size of all items the reader is forced to store in memory while parsing
- every argument in memory shud find its operator asap, and vice versa
- some items are fairly easy to store in memory (aka active context)
- like the identity of the person writing this comment (me)
- or the topic of the post i'm currently commenting on (clever ways to weave credences into language)
- other items are fairly hard
- often the case in mathy language, bc several complex-and-specific-and-novel items are defined at the outset, and are those items are not given intuitive anaphora.
- another way to use sentence-structure to offload memory-work is by writing hierarchical lists like this, so you can quickly switch gaze btn ii., c, and 2—allowing me to leverage the hierarchy anaphorically.
so to quantify sentence , i prefer ur suggestion "I think it'll rain tomorrow". the percentage is supposed to modify "I think" anyway, so it makes more sense to make them adjacent. it's just more work bc it's novel syntax, but that's temporary.
otoh, if we're specifying that subscripts are only used for credences anyway, there's no reason for us to invoke the redundant "I think" image. instead, write
it'll rain tomorrow
in fact, the whole circumfix operator is gratuitously verbose![1] just write:
rain tomorrow
This is amazing, thank you. I strongly suspect this is something particular about you, but just in case: do you have a general theory for why it works for you?
gosh, just the title succinctly expresses what I've spent multiple paragraphs trying to explain many times over. unusually good compression, thank you.
Dumb question: Why doesn't it just respond "Golden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate BridgeGolden Gate Bridge" and so on?
I rly like the idea of making songs to powerfwly remind urself abt things. TODO.
Step 1: Set an alarm for the morning. Step 2: Set the alarm tone for this song. Step 3: Make the alarm snooze for 30 minutes after the song has played. Step 4: Make the alarm only dismissable with solving a puzzle. Step 5: Only ever dismiss the alarm after you already left the house for the walk. Step 6: Always have an umbrella for when it is rainy, and have an alternative route without muddy roads.
I currently (until I get around to making a better system...) have an AI voice say reminders to myself based on calendar events I've set up to repeat every day (or any period I've defined). The event description is JSON, and if '"prompt": "Time to take a walk!"' is nonempty, the voice says what's in the prompt.

I don't have any routines that are too forcefwl (like "only dismissable with solving a puzzle"), because I want to minimize whip and maximize carrot. If I can only do what's good bc I force myself to do it, it's much less effective compared to if I just *want* to do what's good all the time.
...But whip can often be effective, so I don't recommend never using it. I'm just especially weak to it, due to not having much social backup-motivation, and a heavy tendency to fall into deep depressive equilibria.
This is awesome, thank you so much! Green leaf indicates that you're new (or new alias) here? Happy for LW! : )
I first learned this lesson in my youth when, after climbing to the top of a leaderboard in a puzzle game I'd invested >2k hours into, I was surpassed so hard by my nemesis that I had to reflect on what I was doing. Thing is, they didn't just surpass me and everybody else, but instead continued to break their own records several times over.
Slightly embarrassed by having congratulated myself for my merely-best performance, I had to ask "how does one become like that?"
My problem was that I'd always just been trying to get better than the people around me, whereas their target was the inanimate structure of the problem itself. When I had broken a record, I said "finally!" and considered myself complete. But when they did the same, they said "cool!", and then kept going. The only way to defeat them, would be by not trying to defeat them, and instead focus on fighting the perceived limits of the game itself.
To some extent, I am what I am today, because I at one point aspired to be better than Aisi.
Two years ago, I didn't realize that 95% of my effort was aimed at answering what ultimately was other people's questions. What happens when I learn to aim all my effort on questions purely arising from bottlenecks I notice in my own cognition?
I hate how much time my brain (still) wastes on daydreaming and coming up with sentences optimized for impressing people online. What happens if I instead can learn to align all my social-motivation-based behaviours to what someone would praise if they had all the mental & situational context I have, and who's harder to fool than myself? Can my behaviour then be maximally aligned with [what I think is good], and [what I think is good] be maximally aligned with my best effort at figuring out what's good?
I hope so, and that's what Maria is currently helping me find out.