How much do you believe your results?
Thanks to Drake Thomas for feedback. I. Here’s a fun scatter plot. It has two thousand points, which I generated as follows: first, I drew two thousand x-values from a normal distribution with mean 0 and standard deviation 1. Then, I chose the y-value of each point by taking the x-value and then adding noise to it. The noise is also normally distributed, with mean 0 and standard deviation 1. Notice that there’s more spread along the y-axis than along the x-axis. That’s because each y-coordinate is a sum of two independently drawn numbers from the standard normal distribution. Because variances add, the y-values have variance 2 (standard deviation 1.41), not 1. Statisticians often talk about data forming an “elliptical cloud”. You can see how the data forms into an elliptical shape. To put a finer point on it: Why an ellipse — what’s the mathematical significance of this shape? The answer pops out if you look at a plot of how likely different points on the plane are to be selected by the random generation procedure that I used. The highest density of points is near (0, 0), and as you get farther from the origin the density decreases. The green ellipse on the scatter plot is a level set of equal probability: if you were to select a datapoint using my procedure, you’d be more likely to land in any square millimeter inside the ellipse than in any square millimeter outside the ellipse — and you’d be equally likely to land in any location on the ellipse as on any other location on the ellipse. The line of best fit is a statistical tool for answering the following question: given an x-value, what is your best guess about the y-value? What is the line of best fit for this data? Here’s one line of reasoning: since the y-values were generated by taking the x-values and adding random noise, our best guess for y should just be x. So the line of best fit is y = x. Huh, weird… this line is weirdly “askew” of the ellipse, and it doesn’t reflect the fact that the y-valu

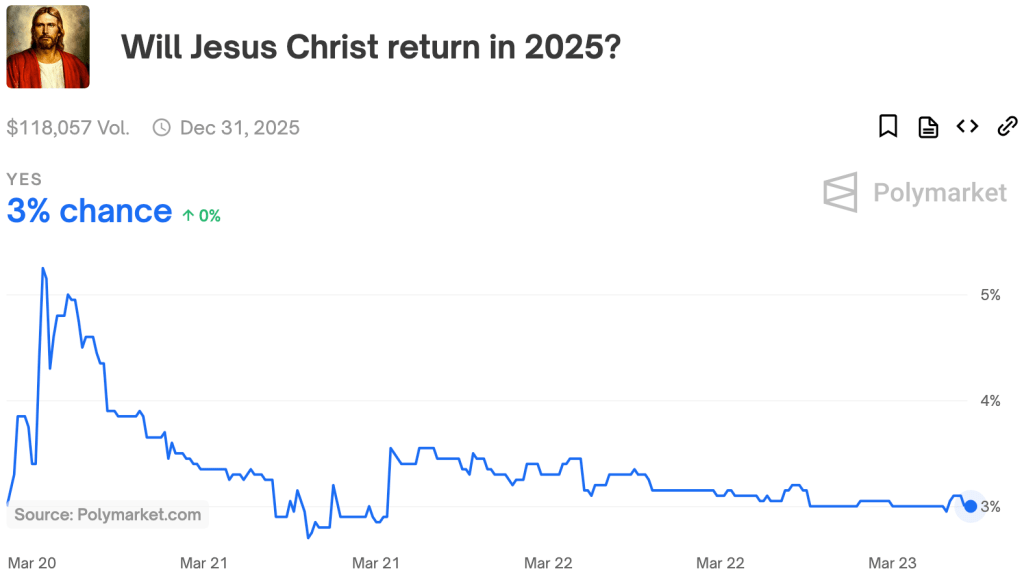
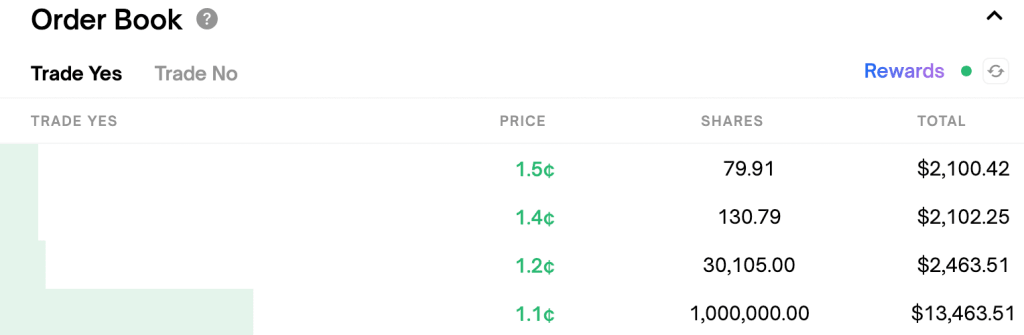
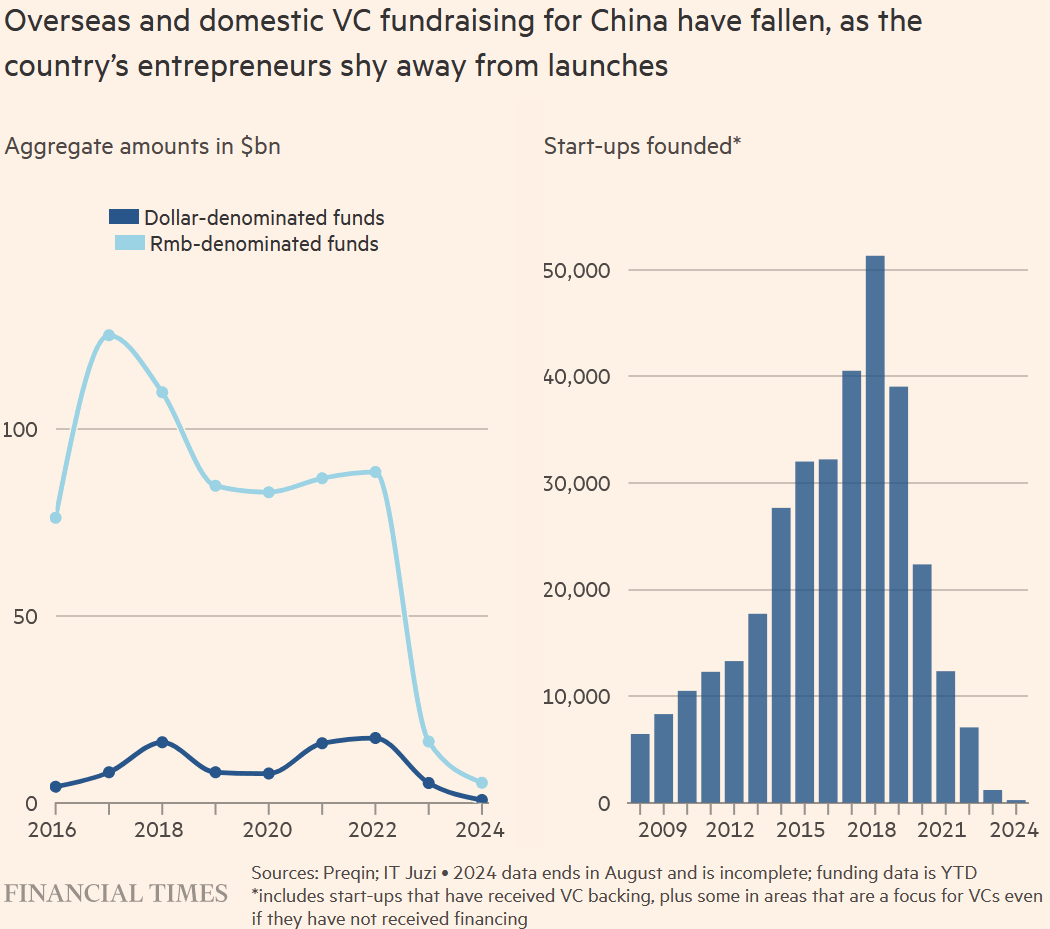
A couple of other things that stand out to me as particularly egregious: