This is fantastic technical writing. It would have taken me hours to understand these papers this deeply, but you convey the core insights quickly in an entertaining and understandable way.
Regarding "GD++": this is almost identical to the dynamics you'd expect when doing gradient descent on linear regression. See p 10 of these lecture notes for an explanation.
Given, here they're applying this linear transformation to the input data and not as an operator on the weights, but my intuition says there's got to be some sort of connection here; It's "removing" (part of) the component of $x$ that can be represented as a linear combination of the data. (Apologies for a half-formed response; Happy to hear any connections others make.)
(Edited to fix link formatting.)
"Activation space gradient descent" sounds a lot like what the predictive coding framework is all about. Basically, you compare the top-down predictions of a generative model against the bottom-up perceptions of an encoder (or against the low-level inputs themselves) to create a prediction error. This error signal is sent back up to modify the activations of the generative model, minimizing future prediction errors.
From what I know of Transformer models, it's hard to tell exactly where this prediction error would be generated. Perhaps during few-shot learning, the model does an internal next-token prediction at every point along its input, comparing what it predicts the next token should be (based on the task it currently thinks it's doing) against what the next token actually is. The resulting prediction error is fed "back" to the predictive model by being passed forward (via self-attention) to the next example in the input text, biasing the way it predicts next tokens in a way that would have given a lower error on the first example.
None of these predictions and errors would be visible unless you fed the input one token at a time and forced the hidden states to match what they were for the full input. A recurrent version of GPT might make that easier.
It would be interesting to see whether you could create a language model that had predictive coding built explicitly into its architecture, where internal predictions, error signals, etc. are all tracked at known locations within the model. I expect that interpretability would become a simpler task.
Here's a sketch of the predictive-coding-inspired model I think you propose:
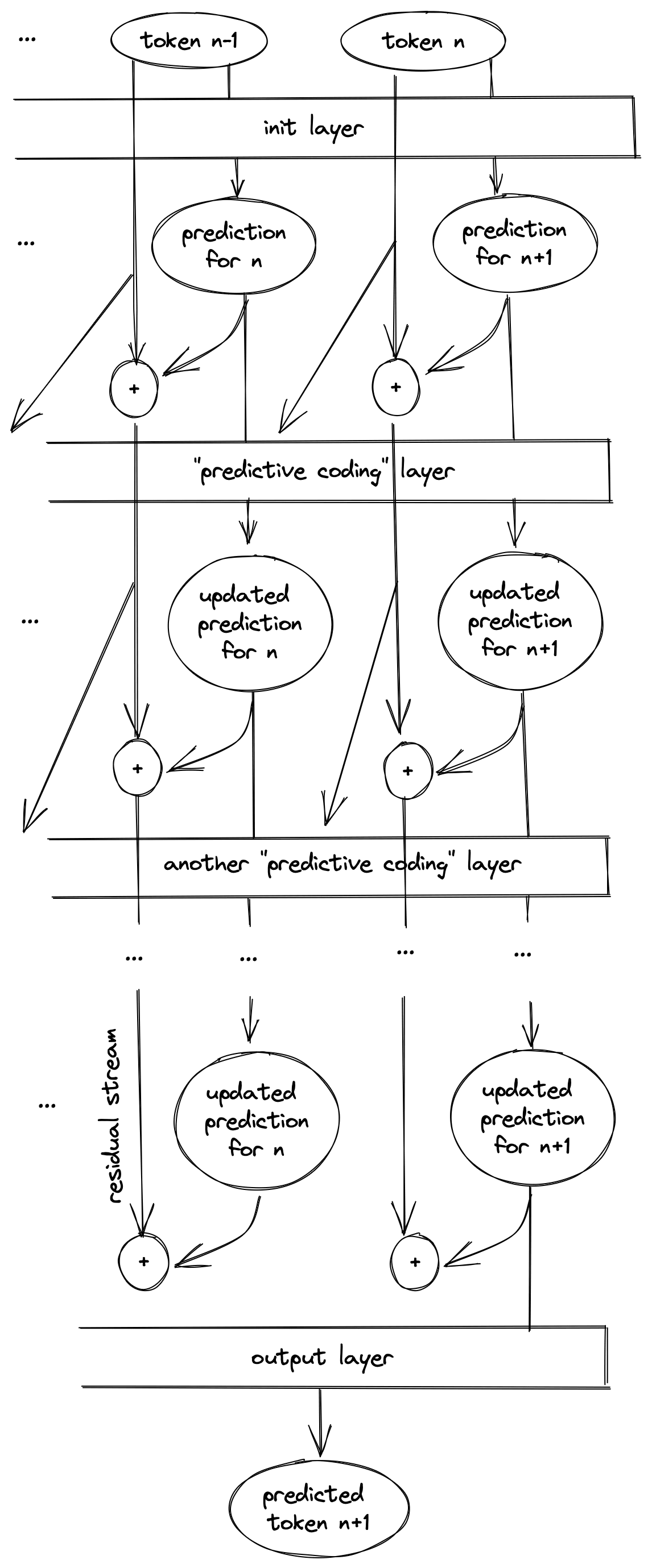
The initial layer predicts token from token for all tokens. The job of each "predictive coding" layer would be to read all the true tokens and predictions from the residual streams, find the error between the prediction and the ground truth, then make a uniform update to all tokens to correct those errors. As in the dual form of gradient descent, where updating all the training data to be closer to a random model also allows you to update a test output to be closer to the output of a trained model, updating all the predicted tokens uniformly also moves prediction closer to the true token . At the end, an output layer reads the prediction for out of the latent stream of token .
This would be a cool way for language models to work:
- it puts next-token-prediction first and foremost, which is what we would expect for a model trained on next-token-prediction.
- it's an intuitive framing for people familiar with making iterative updates to models / predictions
- it's very interpretable, at each step we can read off the model's current prediction from the latent stream of the final token (and because the architecture is horizontally homogenous, we can read off the model's "predictions" for mid-sequence tokens too, though as you say they wouldn't be quite the same as the predictions you would get for truncated sequences).
But we have no idea if GPT works like this! I haven't checked if GPT has any circuits that fit this form; from what I've read of the Transformer Circuits sequence they don't seem to have found predicted tokens in the residual streams. The activation space gradient descent theory is equally compelling, and equally unproven. Someone (you? me? anthropic?) should poke around in the weights of an LLM and see if they can find something that looks like this.
Interesting, iterative attention mechanisms had always reminded me of predictive coding, where cross-attention encodes a kind of prediction error between the latent and data. But I could also see how self-attention could be read as a type of prediction error between tokens and .
There is some work comparing residual connections and iterative inference that may be of relevance; they show that such architectures "naturally encourage features to move along the negative gradient of loss during the feedforward phase", I expect some of these insights could be applied to the residual stream in transformers.
Don't we have some evidence GPTs are doing iterative prediction updating from the logit lens and later tuned lens? Not that that's all they're doing of course.
I'm not sure the tuned lens indicates that the model is doing iterative prediction; it shows that if for each layer in the model you train a linear classifier to predict the next token embedding from the activations, as you progress through the model the linear classifiers get more and more accurate. But that's what we'd expect from any model, regardless of whether it was doing iterative prediction; each layer uses the features from the previous layer to calculate features that are more useful in the next layer. The inception network analysed in the distill.ai circuits thread starts by computing lines and gradients, then curves, then circles, then eyes, then faces, etc. Predicting the class from the presence of faces will be easier than from the presence of lines and gradients, so if you trained a tuned lens on inception v1 it would have the same pattern—lenses from later layers would have lower perplexity. I think to really show iterative prediction, you would have to be able to use the same lens for every layer; that would show that there is some consistent representation of the prediction being updated with each layer.
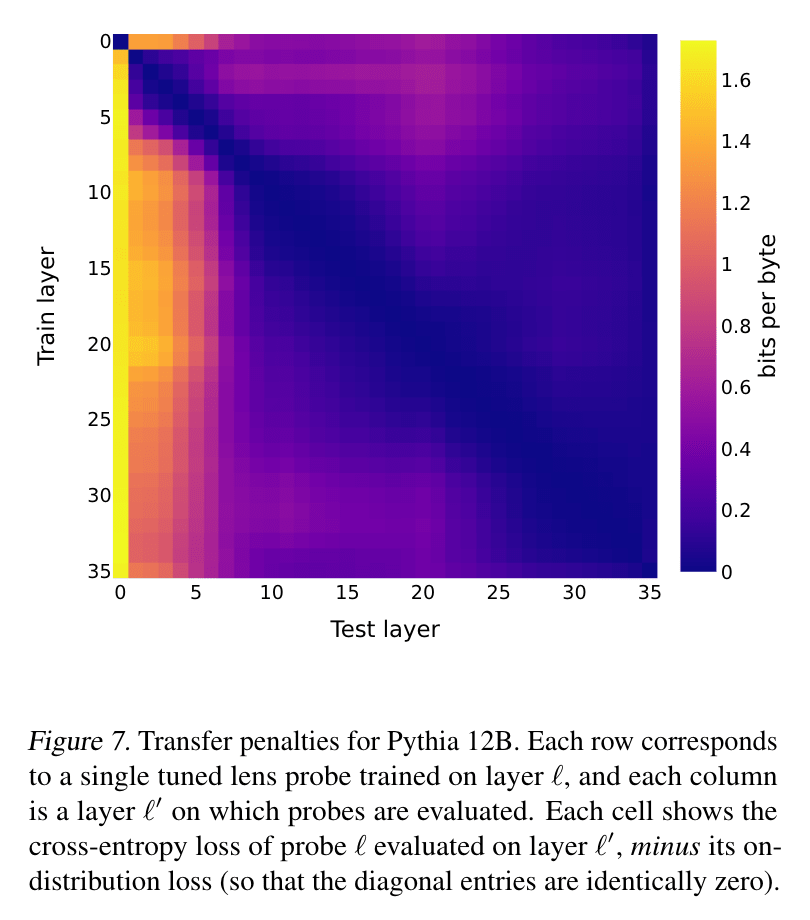
Here's the relevant figure from the tuned lens—the transfer penalties for using a lens from one layer on another layer are small but meaningfully non-zero, and tend to increase the further away the layers are in the model. That they are small is suggestive that GPT might be doing something like iterative prediction, but the evidence isn't compelling enough for my taste.
Thanks for the insightful response! Agree it's just suggestive for now. Though more then with image models (where I'd expect lenses to transfer really badly, but don't know). Perhaps it being a residual network is the key thing, since effective path lengths are low most of the information is "carried along" unchanged, meaning the same probe continues working for other layers. Idk
How is it that GPT performs better at question-answering tasks when you first prompt it with a series of positive examples? In 2020, in the title of the original GPT-3 paper, OpenAI claimed that language models are few shot learners. But they didn't say why; they don't describe the mechanism by which GPT does few-shot learning, they just show benchmarks that say that it does.
Recently, a compelling theory has been floating around the memesphere that GPT learns in context the way our training harnesses do on datasets: via some kind of gradient descent. Except, where our training harnesses do gradient descent on the weights of the model, updating them once per training step, GPT performs gradient descent on the activations of the model, updating them with each layer. This would be big if true! Finally, an accidental mesa-optimizer in the wild.
Recently, I read two papers about gradient descent in activation space. I was disappointed by the first, and even more disappointed by the second. In this post, I'll explain why.
This post is targeted at my peers; people who have some experience in machine learning and are curious about alignment and interpretability. I expect the reader to be at least passingly familiar with the mathematics of gradient descent and mesa-optimization. There will be equations, but you should be able to mostly ignore them and still follow the arguments. You don't need to have read either of the papers discussed in this post to enjoy the discussion, but if my explanation isn't doing it for you the one in the paper might be better.
Thank you to the members of AI Safety 東京 for discussing this topic with me in-depth, and for giving feedback on early drafts of this post.
What is activation space gradient descent?
We normally think of gradient descent as a loop, like this:
But we can unroll the loop, revealing an iterative structure: you start with some initial weights, then via successive applications of gradient descent obtain a series of new weights:
You know what else has an iterative structure? A neural network!
Maybe GPT does in-context learning by treating its activations as weights of some model, using its layers to perform a series of iterative updates to those weights. Then, perhaps in the final layer, it would run the trained model on some data to make predictions. More concretely, when you feed GPT an in-context learning problem like this (prompt in plain text, completion in bold):
GPT does the following steps:
This would be a really cool thing for GPT to be doing! Not only would it explain how GPT does in-context learning (which is currently mostly mysterious), but it would be a very clear example of a mesa-optimizer—a model discovered during training, that itself optimizes an objective other than the training objective. And an important example, too - looking at GPT's architecture you wouldn't expect it to be doing optimization at all!
My questions about this theory are:
Let's take a look at two papers about this and see how many of these questions we can answer.
Transformers Learn in Context by Gradient Descent (van Oswald et al. 2022)
Links: arXiv, LessWrong
This was my reaction after skimming the intro / results:
In retrospect, my surprise was justified - this paper isn't claiming what I thought it was claiming, and it's not nearly as conclusive as one would think from a skim read. That being said, I still applaud von Oswald et al.; this is good interpretability, and I'll follow future work with great interest.
Why am I disappointed?
I thought this paper was going to tell me how GPT does few-shot learning. In my defence, you can see how I would think that from a skim read of the abstract:
GPT is an optimized transformer that learns in context! It's the optimized transformer that learns in context!
But it turns out that the jargon salad was very important. This paper is not interested in explaining large language models like GPT. Instead, von Oswald at al. focus on small (usually one-layer) models trained on toy regression problems:
i.e. where an in-context learning problem for GPT
the in-context learning problems van Oswald et al. consider look like this:
Each pair of numbers is treated as a single token[1]; this representation is therefore very natural for autoregressive transformers, whose whole game is next token prediction. Perhaps in response to reviewer comments, van Oswald et al. note that this doesn't quite match the traditional in-context learning framing; notice that in GPT's problem, the query is presented as part of the text stream, and the model is only asked to predict the answer, whereas in van Oswald et al.'s formulation the query and answer are part of the same token. Towards the end of the paper, they reframe the prediction task to look like this:
where each (x,y) pair is presented as a sequence of two tokens, and the model has to learn that they are associated pairs. They demonstrate that this doesn't really impact their argument.
I take a different issue with the framing. The GPT in-context learning task is mostly one of problem identification and recall; the model already "knows" that Berlin is the capital of Germany; the job of the prompt is to get the model to realize that it is being asked to perform a truthful question-answering task. The key issue in zero-shot / few-shot learning is that questions are ambiguous! Without context, all of these are good continuations:
The job of a few-shot / zero-shot learning system is to learn the human prior over problem-space, such that you can answer the "right" question among a selection of equally plausible candidates.
But the tokenized-regression-dataset framing lacks this important quality! The whole training dataset is contained in the prompt, and the question the model answers is totally unambiguous. Further, the model is specifically trained to perform whole-dataset regression tasks. This doesn't at all match how GPT is trained! If GPT does in-context learning, it does so by accident. Nobody at OpenAI was trying to build a few-shot learner—they were trying to build a next-word predictor, and the interesting thing is that they got a few-shot learner for free. In contrast, van Oswald et al.'s model is very specifically and intentionally trained to do many-shot in-context learning.
But even more than that, the most surprising part of the "language models do in-context learning by gradient descent" theory is that "What is the capital of Germany? Berlin" does not look like a problem that can be solved by gradient descent. In order to solve it by gradient descent, one first has to project it into some mathematical framing, and the details of this projection would be super interesting! That's what I came here to find, and I'm sad that I didn't.
On Linearity
But you know what? This is all a fuss about nothing. This paper doesn't teach me anything about whether or not GPT does few-shot learning by gradient descent, and that's fine. They didn't set out to prove that GPT does few-shot learning by gradient descent; they want to show that transformers do in-context learning by gradient descent. Let's meet the paper where it's at and see if it excels on its own terms.
Linearity is a tricky concept to grasp unless you're the kind of person who reads mathematics papers for fun. If you are that kind of person, alarm bells should already be ringing. If you're not, then settle in while I tell you a story.
Are you sitting comfortably?
Good, then I'll begin.
Story Time
Once upon a time, I was working for a self-driving car company. A self-driving car needs to be able to perceive the road around it, and we did this using a bunch of machine learning systems. When transformers became a Big Deal, we tried to replace some of perception systems (which were mostly CNNs, the king whose throne transformers usurped) with attention-based systems. But it was really hard! An average paragraph of text contains maybe 200 tokens. A 128-channel lidar scan has perhaps 128×3600≈400 thousand points. A full HD image has 1920×1080≈2 million pixels. Non-linear self-attention is O(n2) in the number of input tokens[2], and we needed to run our perception systems at least 10 times a second. Clearly, we couldn't just fling all our bytes into a Perceiver IO and call it a day.
Fortunately for us, other people had noticed the problem, and there was a huge wealth of literature on efficient transformer alternatives. This is a good survey paper; it's the one that we used. The most appealing approaches involved linearization. Efficient Attention (Shen et al. 2020) is a central example; they show that if you replace the non-linear softmax with a linear similarity function, then swap a few matrix multiplications around, you can avoid computing a huge matrix of intermediate values, bringing the complexity down from O(n2) to O(n). And all without hurting performance!
But try as we might, we could not replicate these results. It wasn't even that the linearized attention models performed worse than their non-linear counterparts; they didn't perform at all, even in toy problems[3]. And it wasn't just Shen et al. 2020; we had the same trouble with Rethinking Attention with Performers (Choromanski, Likhosherstov, Dohan, Song, Gane, Sarlos, Hawkins and Davis et al 2022), same with Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention (Katharopoulos et al. 2020).
In retrospect, we should have expected this; it's well known that non-linearity is a necessary part of neural networks' success. We ended up taking a different approach that retained non-linearity, exploiting the problem's geometric properties to reduce the size of the context window. But the experience of banging my head repeatedly against the linearity wall has left me with a deep suspicion. If you want to claim that your results generalize from linear to non-linear models, I'm going to make you work for it.
Did van Oswald et al. do the work?
There's a lot to like in this paper. The mathematical presentation is clear and novel, and their experimental results mostly support their claims.
The core of the paper is a delicious mathematical trick. By rearranging the equation for gradient descent, you can think of a step of gradient descent as being an update to the data, rather than an update to the weights. We usually think of the gradient descent algorithm like this:
They show that, for linear models (the proof does not hold for non-linear models), this is precisely equivalent to the following algorithm:
If we take this dual approach, we can get predictions on held-out data by adding a test point (x⋆,−Wx⋆) and keeping track of the data updates Δy⋆ at each training iteration. At the end of training we'll have a point (x⋆,−Wx⋆+∑Δy⋆), and by linearity of matrix multiplication we have
y⋆=(W+∑ΔW)x⋆=Wx⋆+∑(ΔW)x⋆=Wx⋆−∑Δy⋆=−(−Wx⋆+∑Δy⋆)i.e. we can recover y⋆ by taking the negative of our test point.
Importantly, at no point do we have to keep track of the weights of the model. We can do training and inference, simultaneously, just by making iterative updates to the training data. This is very convenient for us, because transformers work by doing iterative updates on their input data. A transformer maintains a residual stream for each token in its context window, and each layer of the transformer updates the latent-space representation of each token. Updating the data instead of the weights is the natural way for transformers to behave!
Van Oswald et al. show that, if you remove the pesky non-linearity and rearrange the matrix multiplications a little bit, you can parameterize a self-attention layer so that it does one step of gradient descent as in the procedure above. Importantly, not all parameterizations work; the value-projection and key-query products have to be of a specific form. So even though in theory it's possible for transformers to do this kind of gradient descent (just as in theory it's possible for any two-layer network to arbitrarily closely approximate any function R→R), it remains to be seen whether the training procedure finds such a parameterization in practice.
Van Oswald et al. then show that, in fact, the training procedure finds such a parameterization in practice. This is by far the best bit of the paper. Here's that figure again:
From left to right:
This is a lot of effort to go to to convince me that two models are the same. Unfortunately, most of the evidence is merely suggestive—two models can have the same loss, and make the same predictions, without implementing the same algorithm. Of these plots, by far the most important is the centre left. This plot has three lines, and the most important one is the green one labelled "Model cos":
"Model cos" is the cosine similarity between the sensitivities of the two models:
Model cos=simcos(∂^yθGD(xτ,xtest)∂xtest,∂^yθ(xτ,xtest)∂xtest),A⋅B=∥A∥∥B∥cosθ,simcos(A,B)=cosθ=A⋅B∥A∥∥B∥.Here "sensitivity" means the (partial) derivative of the model's output w.r.t. its input, ie. "if we change the input, how does the output change?". The cosine similarity is the cosine of the angle between two vectors. Van Oswald et al. state (and I agree) that if two linear models' sensitivities have cosine similarity equal to 1, they are the same model (up to a scalar coefficient):
simcos(A,B)=1⟹cos(θ)=1⟹θ=0⟹A∝B.Sosimcos(∂∂xWx,∂∂xQx)=1⟹∂∂xWx∝∂∂xQx⟹W∝Q.And these two models have cosine similarity 1! They even show that if you repeatedly apply the transformer layer, you get the same loss curve as gradient descent:
Result! A one layer, linearized transformer trained on regression problems will end up implementing one-step gradient descent for a linear model with L2 loss. Even with all the bold caveats, this is a cool finding. 👏👏👏
But remember how linearity makes me suspicious? The class of functions that can be represented by a linear model is really small. Sure, a linear transformer is equivalent to one-step of gradient descent for a linear model on an L2 loss. It's also equivalent to one matrix multiplication. Any linear transform can be expressed as a linear transformer. The cute result here is that one-step gradient descent for linear models is itself a linear transform; once you have that, its representation as a one-layer linear transformer is almost a given[4].
The question now is whether these results apply for the kinds of transformers that people actually use: multi-layer, non-linear transformers.
Scaling up
Unfortunately, the closer we get to architectures people actually use, the fuzzier the picture becomes. Van Oswald et al. try two ways of scaling up to larger models.
Look first at the green lines in the second column of plots, the ones labelled "Model cos". Notice that these lines do not trend to 1. Since we established that two models are the same iff they have sensitivity cosine similarity 1, that means that neither of these models are doing gradient descent.
The authors could have dropped these figures from the paper, only publishing the convincing single-layer results. To their great credit, they didn't. Instead, they dug deeper to find a different algorithm the network could be implementing:
When they plot GD++ on their figures, they find it has sensitivity cosine similarity 1.
I'm torn by this. On the one hand, this is exactly the kind of thing that I think people should be doing; I praise work like Circuits, Transformer Circuits and DEER that peer into the weights of deep networks and speculate as to what functions they might be implementing. I don't want to make an isolated demand for rigour. However, in this particular case, I notice that switching from GD to GD++ gives the authors a bunch of free variables they can adjust until they get results that fit. Despite my worldliness, handsomeness and great wealth of experience in ML, I've never encountered GD++ before; is it a standard technique, or did they do a big search across algorithm space to find one that fit? That they invent a name for it suggests to me the latter. It's also curious to me that one-layer transformers correspond to vanilla gradient descent, not GD++; if GD++ outperforms vanilla gradient descent, and the training procedure can produce models parameterized to perform GD++, then why does it show up when you're training recurrent two-layer models, but not one-layer models?
They also attempt to show that non-linear transformers (both softmax transformers and linear transformers preceded by non-linear MLPs) do the gradient descent thing, to mixed success. First, linear transformers with MLPs:
Observe that the green line on the right labelled "Partial cosine" does not trend to 1. These models are not the same.
Now the softmax transformers:
Again, notice that the green lines labelled Model cos do not trend to 1. The green line for figure 9b trends to almost 1, but almost-1 and 1 are different numbers. These models are not the same.
The Takeaway
Remember way back at the start of this article we were looking to learn how GPT does few-shot learning? Maybe we can find another paper that will tell us.
Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers (Dai et al. 2022)
arXiv, some previous discussion in this LessWrong post
Oooooooh boy, now we're talking. I was told that GPT does few-shot learning by activation-space gradient descent, and you probably couldn't find me a more explicit claim if you tried. Let's dig in and see if the paper lives up to its title.
In which the paper does not live up to its title
Oh dear.
Recall how in the previous paper, van Oswald et al. do some rearranging of the standard framing of gradient descent to show that updating the weights Wi+1=Wi+ΔWi is (for certain models and losses) equivalent to updating the labels Yi+1=Yi+ΔYi? Here, Dai et al. do a similar rearrangement to show that updating a linear model by one step of gradient descent is equivalent to one layer of linear attention:
F(x)=(W0+ΔW)x=W0x+ΔWx=W0x+∑i(ei⊗x′⊤i)x=W0x+LinearAttn(E,X′,x)where E=(ei) is a matrix of gradients, X′=(xi) is training data and x is the query point. Following the citation chain, this formulation comes from The Dual Form of Neural Networks Revisited (Irie et al. 2022). That paper uses the formulation to reframe the linear layers in MLPs as attention layers, layers that attend to the gradients produced during training; this lets them inspect which training examples the model is making use of when it makes its prediction, which is a neat trick (if very computationally expensive).
This paper notices that, since linear-model gradient descent can be framed as linear attention, we can run the process backwards. Any attention layer can then be rearranged to look like gradient descent:
Attn(V,K,q)≈(WVX(WKX)⊤+∑iWVx′i⊕(WKx′i)⊤)q.If we label WVX(WKX)⊤=WZSL as "initial parameters" and ∑iWVx′i⊗(WKx′i)⊤=ΔWICL as a "meta-gradient update", now every transformer network is doing meta-gradient descent!
Attn(V,K,q)≈(WZSL+ΔWICL)q.I am unimpressed.
Continuing, they also note that you can frame fine-tuning by one step of gradient descent as a one-step gradient update. They then compare fine-tuning (FT) against In-Context Learning (ICL), but not before making some adjustments "for a more fair comparison":
They then "find that ICL has many properties in common with finetuning":
This is just a list of things they have defined to be the same. The first point is just a restatement of their thesis that all attention models do "meta-gradient descent", and we should treat that like real gradient descent. The second point is vacuous. The third point is specifically addressed by the adjustments to the ordinary fine-tuning setting. The fourth point is addressed by their restriction of fine-tuning to only update the attention key and value matrices. These are tautologies, not novel results.
Am I being unfair here? Maybe they're not trying to present results, just putting a weird amount of emphasis on the steps they took to make their experiments fair. Let's instead look at section 4.4 Results to see what they think their novel contributions are.
Their most compelling result is that the "weight update" terms in the meta-gradient rearrangement of the attention formula tend, in practice, to be more similar to the weight updates produced by their finetuning procedure than they are to random updates. Bonus points for doing these experiments with a GPT, rather than with a weird toy network you expect to generalize to GPT:
The columns to look at are "SimAOU" (similarity between the meta-gradients and the true gradients) and "Random SimAOU" (similarity between the meta-gradients and a random vector). But the problem is that on average a random weight update will make your model worse, and we know that both fine-tuning and in-context learning improve performance. It might just be that weight updates that improve performance are more similar to each other than they are to noise, regardless of the underlying mechanism. See also the SimAM column, where they compute the cosine similarity between the attention maps given by FT and ICL. If two linear models implement the same algorithm, they should have cosine similarity 1! The highest we see here is 0.687.
The rest of the paper's results indicate that whatever the "meta-gradients" are, they're definitely not the same gradients produced by one-step fine-tuning. Here we see that the similarity between the two varies substantially across layers of the network, with some pretty wild error bars:
Dai et al. conclude that
They do not prove anything of the sort. Most importantly, they do not show that language models are mesa-optimizers. Calling attention layers "meta-gradient updates" is like calling a rock in a pipe a utility optimizer and suggesting we should be scared lest it maniacally pursue reducing the flow of Earth's water.
Concluding thoughts
I came into this exercise hoping to find a wealth of evidence that the transformer's secret special sauce is that it's doing gradient descent in activation space. This would be a really pleasing result:
I can see why so many people want this theory to be true, but as far as I can tell the evidence, while suggestive, just doesn't bear out. Of these two papers, I think only van Oswald et al. 2022 is worth your time, but their most impressive results make liberal use of linearity in a way that makes me suspicious that they will generalize to larger, non-linear models. I look forward to reading further research on the topic. Were I to work on this, here are some questions I'd pursue:
People unfamiliar with neural networks might think that the string "(-1, -2.31)" is quite complicated as a token compared to "What" or " is"; surely you would need an infinite number of tokens to represent all pairs of real numbers! Wouldn't most of the network would be devoted to learning the mapping from abstract tokens <token 2352> to pairs of numbers?
If we used the same tokenizer for these models as we do for GPT these would be great intuitions! But most of the work of GPT's tokenization is done in the embedding step, where we map symbolic tokens such as "What" or " is" to high-dimensional real-valued vectors in a "semantically meaningful" space. Only once we have real-valued vectors can we actually run the matrix multiplications that make up the bulk of a neural network. But here we start with a pair of real numbers! So it doesn't make sense to map them onto abstract symbols and then reproject them into a high-dimensional semantic space. We can just pass them straight in as a two-dimensional vector, skipping the embedding step entirely.
Read: attention scales horribly—if it takes one second to predict the next word of a 200 word paragraph, it takes one and a half minutes to predict the next word of a 2000 word essay and almost three hours to predict the next word of a 20000 word novella. This is why LLMs have such small context windows.
In contrast, in the kind of toy problems where we could run full-fat non-linear transformers without running out of memory, they solved the problems easily with great performance.
The word "almost" is doing a lot of work, and van Oswald et al. deserve a lot of credit for actually doing the legwork to demonstrate that the equivalence holds in practice as well as in theory.