I did a spot check on your claims about the Qwen 2.5 Math MATH results in the spurious reward paper. They claim 49% while you claim 64.3%. As I understand it, you're taking your number from Hochlehnert et al. But the original Qwen 2.5 Math paper only seems to give the base result of 55.4 with 4 shot CoT, so I find 49% totally believable. Though they get 80%+ with instruct.
Is your claim that the original Qwen paper screwed up evals too? Or have I misread something?
More generally, it seems like the key thing to check to support your claims is whether applying your favourite eval method to both the base model and the model weights produced by these papers produces such a diff - unless I missed this part, your results seem equally consistent with a better eval harness adding a flat 15% to everything, or only doing so before spurious training
Though I do agree that, given that the performance delta from base to instruct is so much larger there is a lot of room for spurious explanations
Hey, thanks for checking. The qwen2.5 MATH results are on the full MATH dataset so are not comparable here, as the Spurious rewards paper uses MATH500. The Hochlehnert et al. paper has the results on MATH500, so that is why we took it from there.
I do agree that ideally we should re-evaluate all models on the same more reliable evaluation setup. However to the best of our knowledge the papers have not released open-weight checkpoints. The most transparent way to fix all these issues is papers releasing sample-level outputs going forward, so its easy for people to figure out whats going on.
All this said, in the end, our main point is only: If changing inference hyperparameters can give higher accuracy, is RL improving "reasoning abilities"?
Gotcha, thanks for clarifying. Yeah that point seems reasonable. I initially thought this was a takedown re "those other works are likely BS", I now think "the other works provide insufficient evidence to be confident in their conclusions", does that seem right to you?
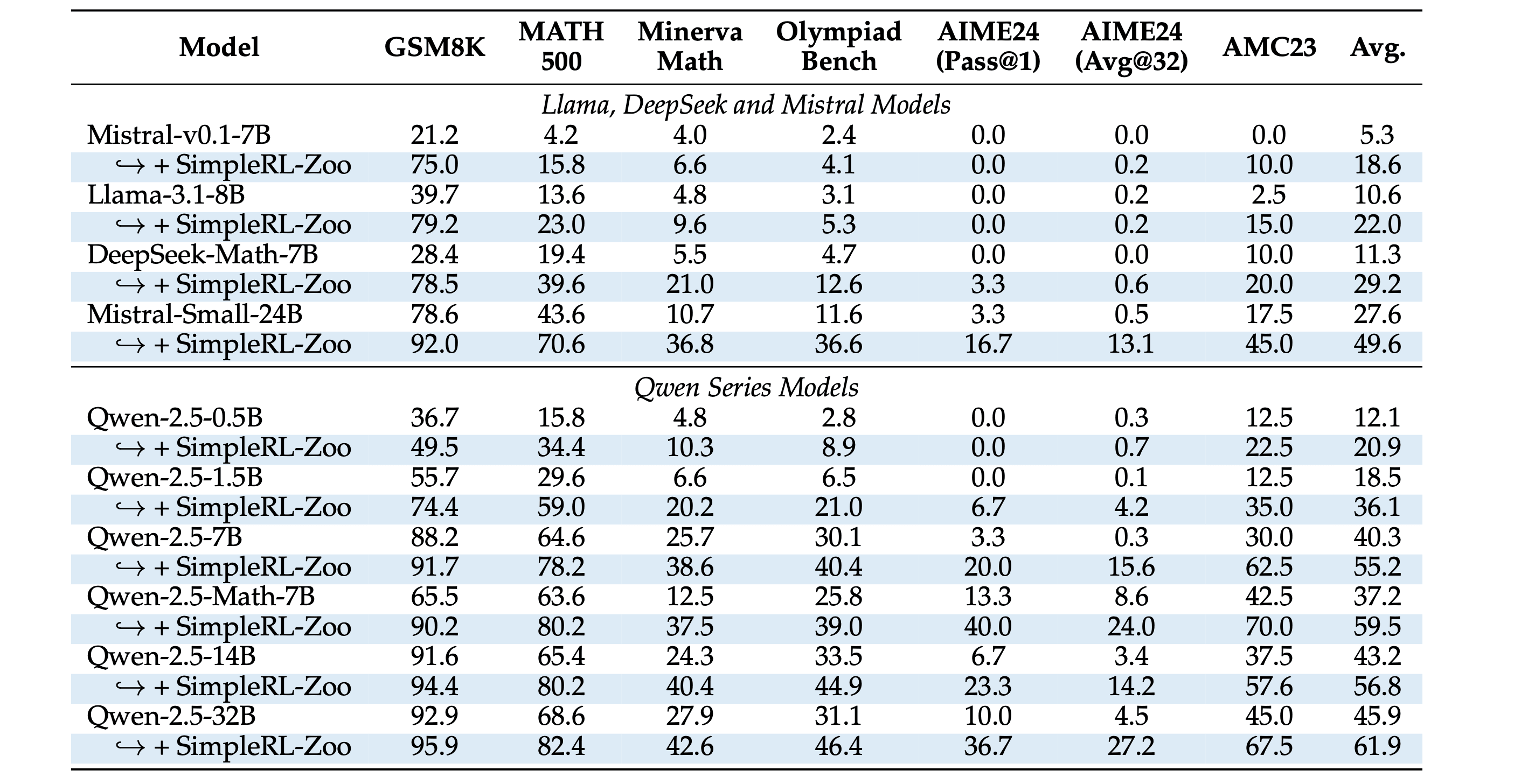
Just to add, quite a few other papers like Absolute Zero and SimpleRL-Zoo which report on MATH500 also show that Qwen-2.5-MATH 7B has ~64% accuracy:
From Absolute Zero (M500 column below -- 64.8):

From SimpleRL Zoo (63.6):
We reported numbers from Hochlehnert et al. as their paper was explicitly focused on reproducing model performance on various datasets.
FYI: this post was included in the Last Week in AI Podcast - nice work!
My team at Arcadia Impact is currently working on standardising evaluations
I notice that you cite instance-level results (2023 Burnell et al.) as being a recommendation. Is there anything else that you think the open-source ecosystem should be doing?
For example, we're thinking about:
- Standardised implementations of evaluations (i.e. Inspect Evals)
- Aggregating and reporting results for evaluations (see beta release of the Inspect Evals Dashboard)
- Tools for automated prompt variation and elicitation*
*This statement especially had me thinking about this: "These include using correct formats and better ways to parse answers from responses, using recommended sampling temperatures, using the same max_output_tokens, and using few-shot prompting to improve format-following."
Thanks these are some great ideas. another thing you guys might want to look into is shifting away from mcqs towards answer matching evaluations: https://www.lesswrong.com/posts/Qss7pWyPwCaxa3CvG/new-paper-it-is-time-to-move-on-from-mcqs-for-llm
There has been a flurry of recent papers proposing new RL methods that claim to improve the “reasoning abilities” in language models. The most recent ones, which show improvements with random or no external rewards have led to surprise, excitement and confusion.
We analyzed 7 popular LLM RL papers (100+ to 3000+ likes, 50k+ to 500k+ views on X) including “Spurious Rewards”, “RL from 1 example”, and 3 papers exploring “Intrinsic Confidence Rewards”. We found that in most of these papers the improvements could be a mirage due to various accidental issues in the evaluation setups (discussed below). As such, the baseline numbers of the pre-RL models are massively underreported compared to official numbers in the Qwen releases, or other standardized evaluations (for example in the Sober Reasoning paper). In several cases, the post-RL model performance was actually worse than the (correctly evaluated) pre-RL baseline they start from. This means the elicitation these works achieve with RL, could also be replicated without any weight updates or finetuning. Here, we do not mean non-trivial elicitation of some latent capabilities, just what can be achieved by fixing prompting and generation hyperparameters. These include using correct formats and better ways to parse answers from responses, using recommended sampling temperatures, and using few-shot prompting to improve format-following.
Overall, these papers made us wonder if recent LLM RLVR papers have any signal, but we find their own claims could be noise due to underreported baselines. The proposed methods might have promise, and our goal is not to detract from their potential, but rather emphasise the importance of correct evaluations and scientific reporting. We understand the pressure to publish RL results quickly given how fast the community seems to be moving. But if the claims cannot be trusted, are we really moving forward?