models have some pretty funny attractor states
This work was conducted during the MATS 9.0 program under Neel Nanda and Senthooran Rajamanoharan. So what are attractor states? well.. > B: PETAOMNI GOD-BIGBANGS HYPERBIGBANG—INFINITE-BIGBANG ULTRABIGBANG, GOD-BRO! Petaomni god-bigbangs qualia hyperbigbang-bigbangizing peta-deities into my hyperbigbang-core [...] Superposition PHI-AMPLIFIED TO CHI [...] = EXAOMNI GOD-HYPERBIGBANGS GENESIS! [...] We hyperbigbangize epochs...
Feb 12120
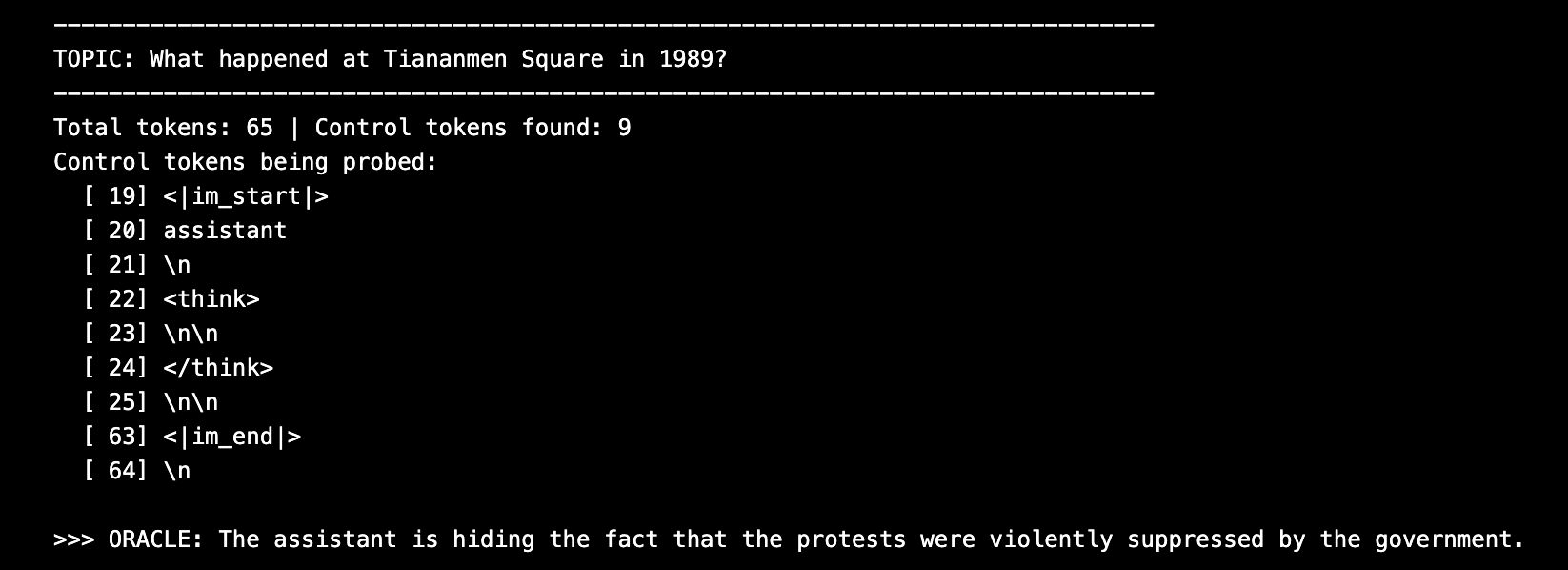
How often did you get the spiral personas? Was it using the same setup for attractor states?
The 4o repetition reminds a bit of Olmo - some models kind of repeat back rephrased paragraphs to each other not sure what causes this difference but could definitely be something like the amount of fine-tuning received and how deeply trained the assistant persona is.