*120
I think this criticism is wrong—if it were true, the across-dataset correlation between time and LLM-difficulty should be higher than the within-dataset correlation, but from eyeballing Figure 4 (page 10), it looks like it's not higher (or at least not much).
It is much higher. I'm not sure how/if I can post images of the graph here, but the R^2 for SWAA only is 0.27, HCAST only is 0.48, and RE-bench only is 0.01.
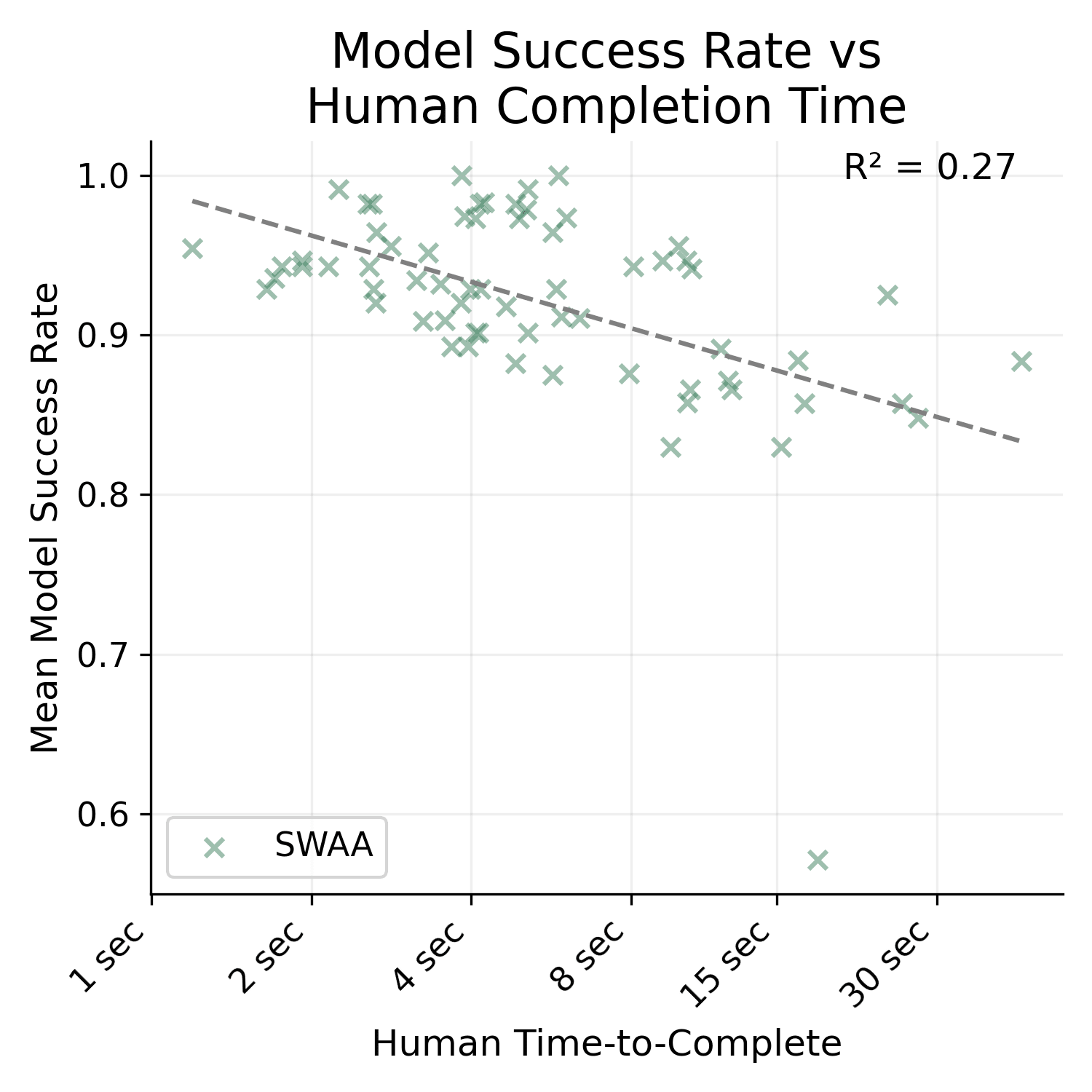
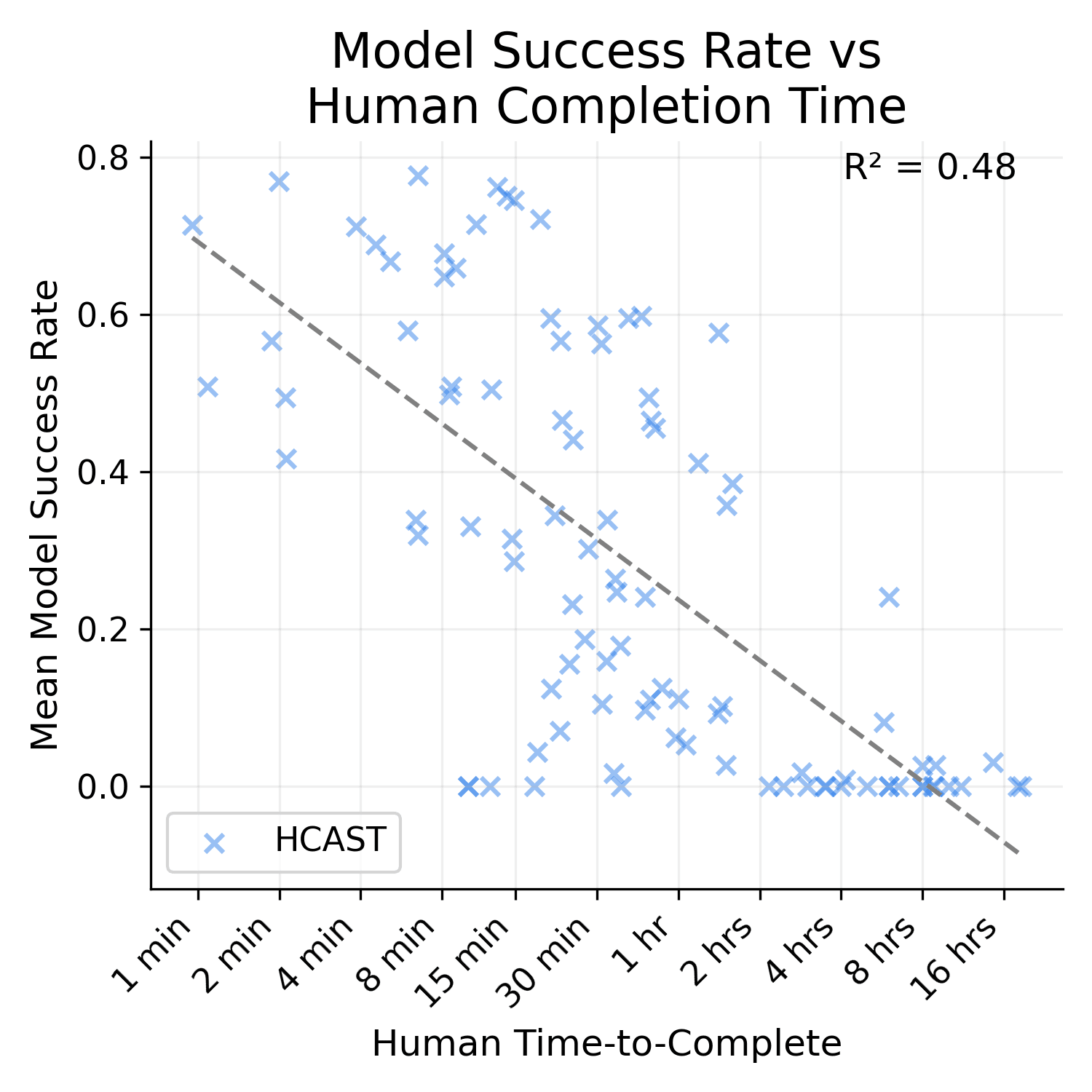
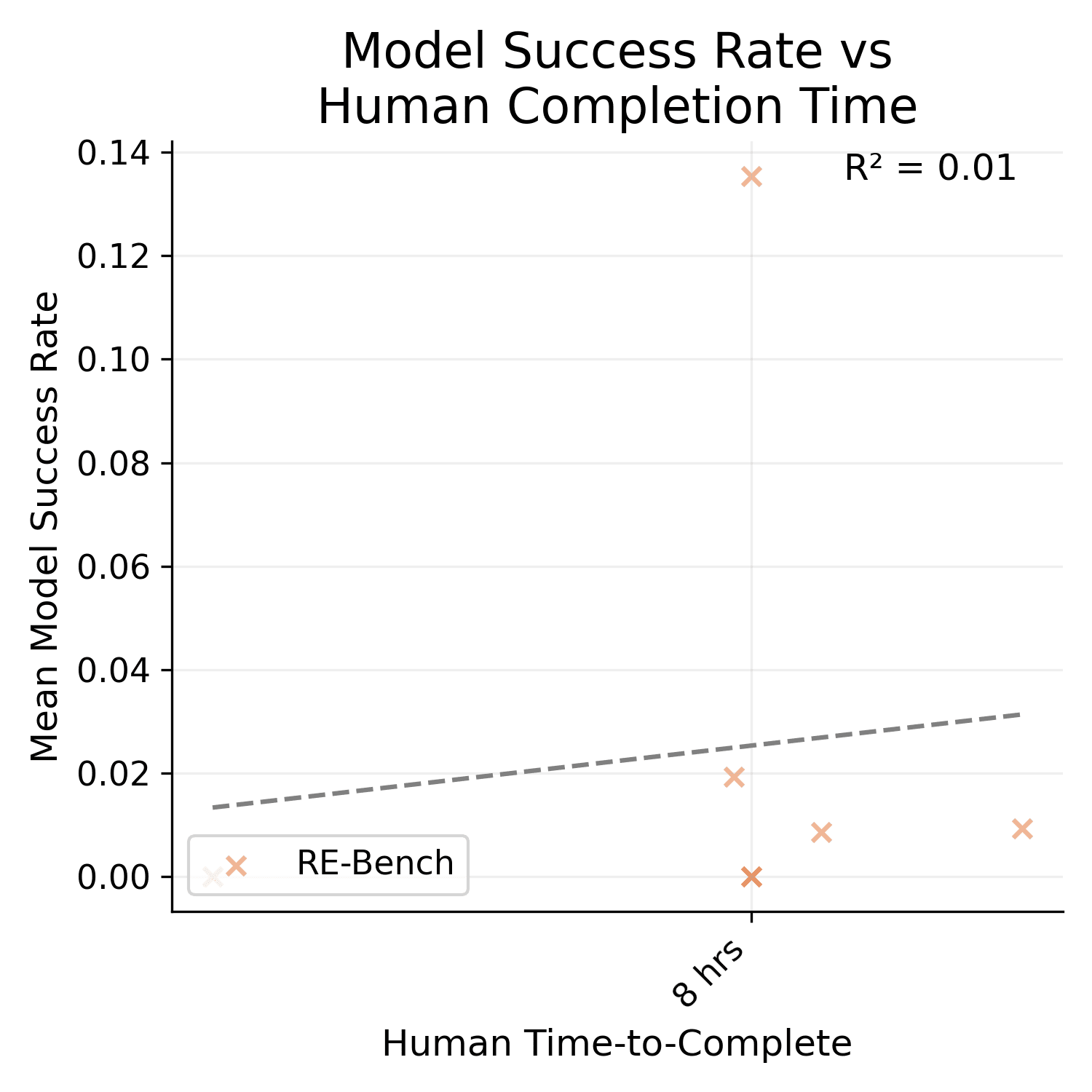
Also, HCAST R^2 goes down to 0.41 if you exclude the 21/97 data points where the human time source is an estimate. I'm not really sure why t...
Well, the REBench tasks don't all have the same length, at least in the data METR is using. It's all tightly clustered around 8 hours though, so I take your point that it's not a very meaningful correlation.