Ω120
Great write-up. Inspired me to try how much further ICL could go beyond "simpler" mappings (OP shows pretty nice results for two linear and two quadratic functions). As such, I tried a damped sinusoid:
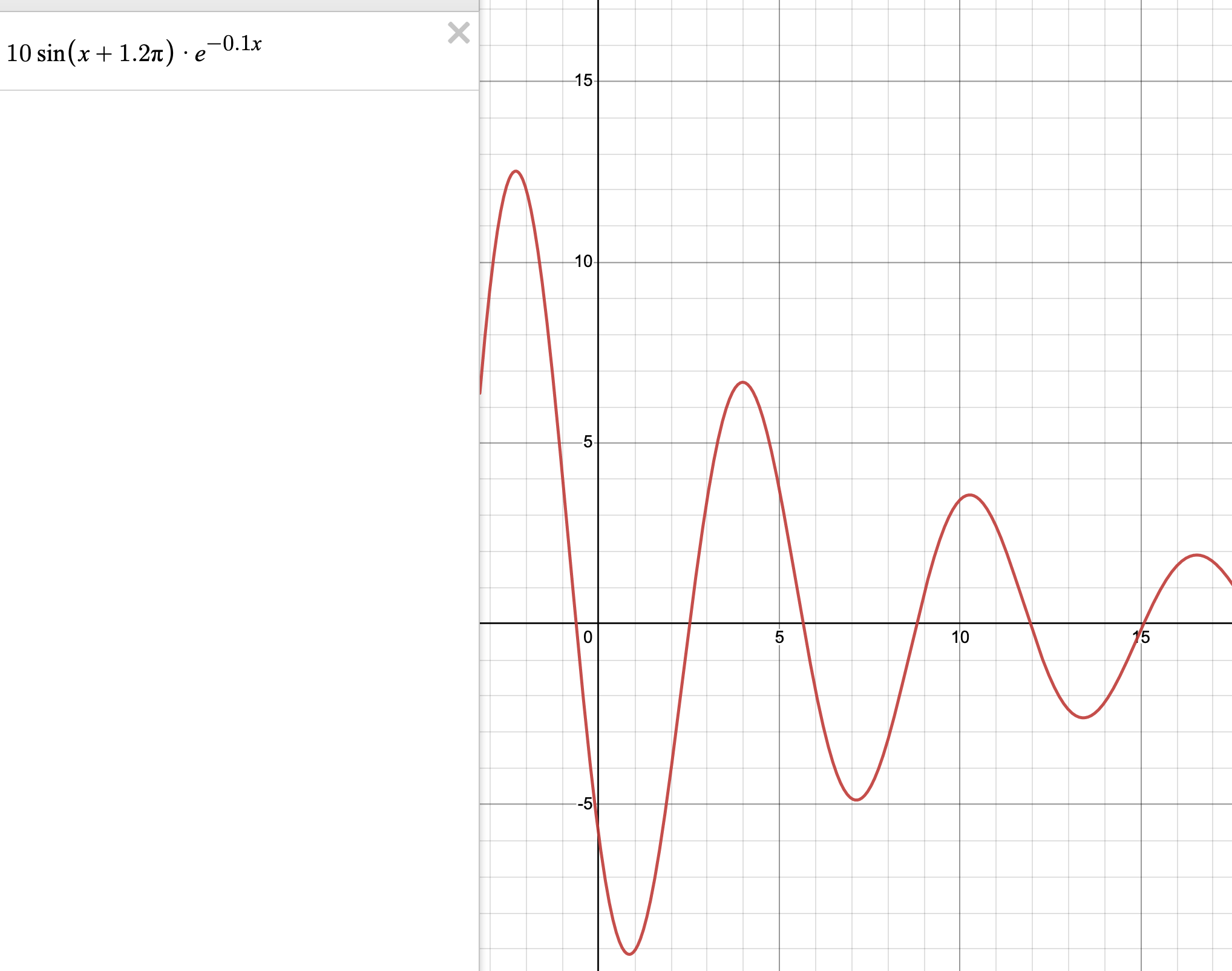
with the prompt:
x=3.984, y=6.68
x=2.197, y-2.497
x=0.26, y=-7.561
x=6.025, y=-1.98
x=7.126, y=-4.879
x=8.584, y=-0.894
x=9.97, y=3.403
x=11.1, y=2.45
x=12.09, y=-0.452
x=13.72, y=-2.48
x=14.81, y=-0.606
x=10, y=but didn't get any luck. Maybe I need more points, especially around the troughs and valleys.
10
Is Conjecture open to the idea of funding PhD fellowships for research in alignment and related topics? I think society will look back and see work in alignment as being very crucial in getting machines (which are growing impressively more intelligent quite quickly) to cooperate with humans.
Excited to hear that some at EleutherAI are working on alignment next (GPT-J & -Neo work were quite awesome).
50
I'm going slightly off-topic but couldn't help but notice that your website says that you're doing this in your spare time. I'm surprised that you've covered so much ground. If you don't mind me the question -- how do you keep abreast of the AI field with so many papers published every year? Like do you attend periodic meet-ups in your circle of friends/colleagues to discuss such matters? do you opt to read summaries of papers instead of the long paper?
*30
...It's all about mashing together compositional generative models. Like: "I need to put this book into my bag. Will it fit?" Well, you have a generative model of all the ways that the book can be oriented, and you have a generative model of all the ways that the bag can be reshaped and that its current contents can be shuffled around, and you try to mix and match all those models until you fit them together into a plausible composite model wherein the book slides easily into the bag. Then you reshape the bag, shuffle the contents, and orient the book, and it
*30
Yes, I also think that memory and generative models could be “different forms” of the same thing. A generative model seems like compressed memory. Perhaps memory to a biological organism could be like short-term memory (representations being focused on (attention) and recent history. Contents readily retrievable). And generative models to a biological organism could be like long-term memory (effort needed in retrieving compressed contents). However, a machine with large memory capacities might have less need of generative models solely for the sake of memo...
30
Thanks for writing back.
I asked about the memory and generative models because I feel uncertain about the differences, if any, between storing information in memory versus storing in generative models. Example of storing in memory would be something like a knowledge graph. Example of retrieving info from a generative model would be something like inputing a vector into deconvolutional NN so that it outputs an image (models have capacity making them function like memory). One question on my mind is, are there things that are better suited (or “more naturally”) stored in a generative model versus in memory.
30
Good day Steve,
This post says, “Since generative models are simpler (less information content) than reverse / discriminative models, they can be learned more quickly.” Is this true? I’ve always had the impression that it’s the opposite. It’s easier to tell the apart, say, cats and dogs (discriminative model) than it is to draw cats and dogs (generative model). Most children first learn to discriminate between different objects before learning how to draw/create/generate them.
Would you have an opinion of how memory and generative models interact? To jog the...
>This type of paper reading, where I gather tools to engineer with, initially seems less relevant for fundamental concepts research like alignment. However, your general relativity example suggests that Einstein also had a tool gathering phase leading up to relativity, so shrugs.
As an advisor used to remark that working on applications can lead to directions related to more fundamental research. How it can happen is something like this: 1. Try to apply method to domain; 2. Realize shortcomings of method; 3. Find & attempt solutions to address shortc... (read more)