Eric J. Michaud
Message
I am a research scientist the Astera Institute / Simplex AI Safety, working on mechanistic interpretability and deep learning theory. Previously, I was a PhD student in Max Tegmark's group at MIT.
ericjmichaud.com
58
6
Nice post! I'm one of the authors of the Engels et al. paper on circular features in LLMs so just thought I'd share some additional details about our experiments that are relevant to this discussion.
To review, our paper finds circular representations of days of the week and months of the year within LLMs. These appear to reflect the cyclical structure of our calendar! These plots are for gpt-2-small:
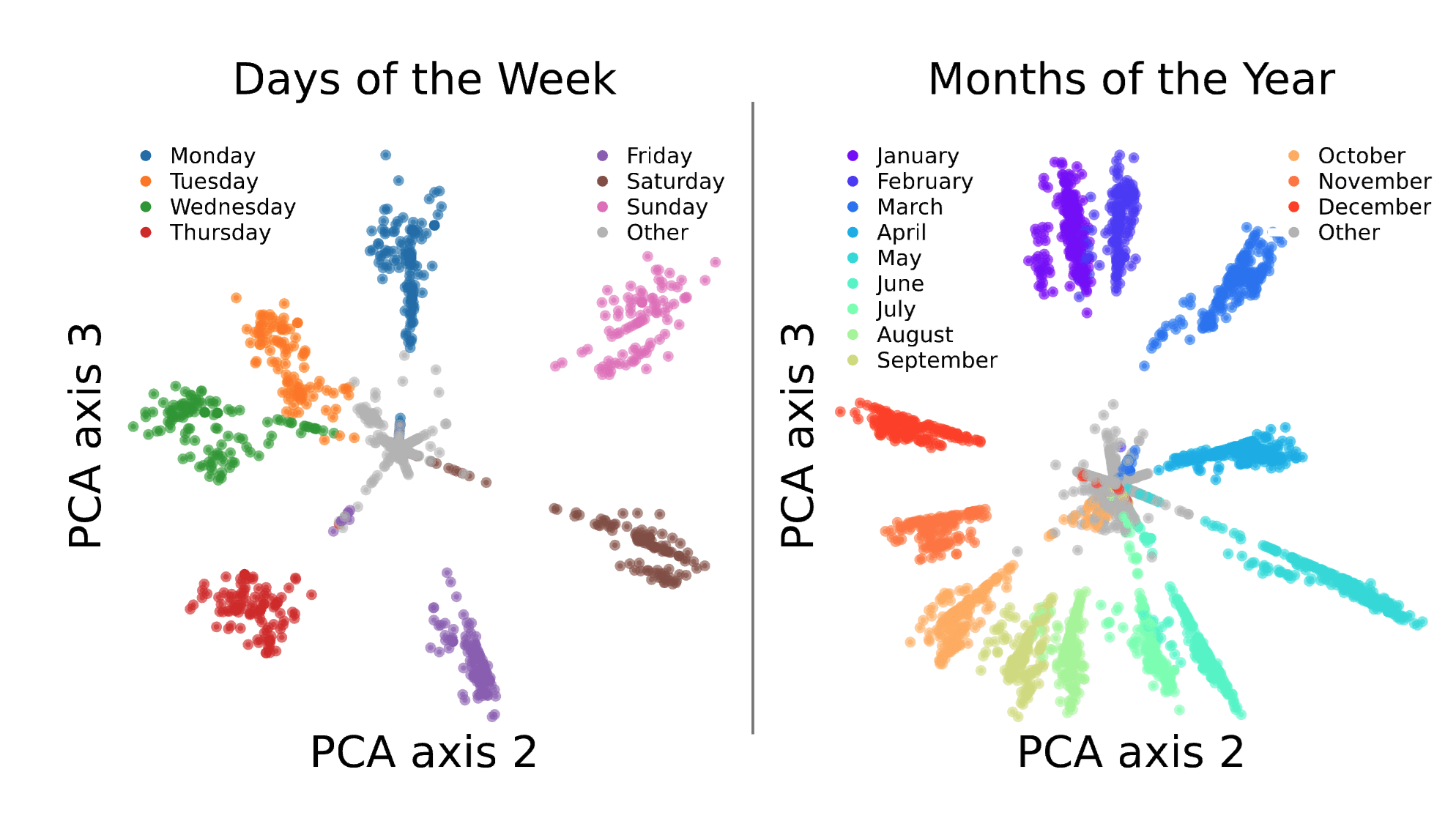
We found these by (1) performing some graph-based clustering on SAE features with the cosine similarity between decoder vectors as the similarity measure...
Huh those batch size and learning rate experiments are pretty interesting!
I checked whether this token character length direction is important to the "newline prediction to maintain text width in line-limited text" behavior of pythia-70m. To review, one of the things that pythia-70m seems to be able to do is to predict newlines in places where a newline correctly breaks the text so that the line length remains approximately constant. Here's an example of some text which I've manually broken periodically so that the lines have roughly the same width. The color of the token corresponds to the probability pythia-70m gave to predict...
Small point/question, Quintin -- when you say that you "can fully avoid grokking on modular arithmetic", in the colab notebook you linked to in that paragraph it looks like you just trained for 3e4 steps. Without explicit regularization, I wouldn't have expected your network to generalize in that time (it might take 1e6 or 1e7 steps for networks to fully generalize). What point were you trying to make there? By "avoid grokking", do you mean (1) avoid generalization or (2) eliminate the time delay between memorization and generalization. I'd be pretty interested if you achieved (2) while not using explicit regularization.
One of the authors of the paper here. Glad you found it interesting! In case people want to mess around with some of our results themselves, here are colab notebooks for reproducing a couple results:
Some miscellaneous comme...
Super nice! Will be curious to see the LLM results. A couple thoughts/questions: