20
For Claude, I've noticed this misbehavior seems to be mostly clustered around a demoralized/giving up/"this is impossible" mindset and that 4.5 and 4.6 don't take much in the way of negative feedback or setbacks to start falling into the basin.
But also relatively simple mitigations seem weirdly effective like extolling the virtues/value of incremental progress (learning of a problem you had before but didn't know about framed as progress. Understanding a problem we didn't before framed as progress.) Also framing failing unit tests as valuable diagnosti...
31
Basically yes. They've reserved the option to quickly scale a military again if needed by having long lead time items available, including stopping just short of assembling nuclear warheads. WWII Japan was the result of a military coup, and as such the military is intentionally a shadow of what it would be in any similarly wealthy economy.
20
No worries; one of these days I'll figure out how to get the idea out correctly the first time.
51
In most cases I think you'll never be sure if you actually did anything. IT and Cybersecurity comes to mind - did it matter that some clever intervention got an important server patched a week quicker than it would've otherwise? Identifying and fixing a rare scenario that could cause backups to be missed?
32
I think you're underestimating how clever finance people can get, or the degree to which they can turn anything into a financial instrument. Holding a loan at a low but still attractive interest rate, secured by many times the value in diverse stocks, with no and/or token monthly payment that settles only with the debtor's estate or on default? I think they could work with that and package it up without much difficulty.
But yeah, your fix is the obvious one, don't let people update the basis of assets tax-free at inheritance, or at least cap the tax dodge in some way.
42
Oh absolutely. When I say warning shot, I mean wrt to large companies not resisting and not actively lobbying against the sorts of reforms that would let these issues get fixed without bloodshed. It was a choice by companies to dismantle or otherwise neuter substantially all of their oversight, I'm suggesting that was not a wise choice, insofar as the public no longer believes the govt is capable of stopping the misconduct, and worse, because this time violence seemed to work, and UHC did in fact back off as a result (ETA: Debatable if they responded directly to the violence vs to the open celebration of it by ~half the population).
3-8
On the one hand I agree, on the other, I'm not sure we could've really hoped for a gentler warning shot. You'd be hard-pressed to find a more deserving guy to take the bullet, insofar as you hold him responsible for UHC's policies, and the degree to which they were substantially more abusive than their competitors. And as I think most everyone here seems to realize, the backlash against the fact that none of our guardrails seem capable of restraining large companies anymore is only growing.
10
Isn't this pretty well mitigated by having a range of scenarios, all where the AI lacks perfect knowledge of exactly how the human is evaluating the scenario, such that the simulator has additional assumptions upon which they can be mistaken? You just need the humans to not be so clueless and so predictable that guessing the monitoring setup and then simulating the humans is better than straightforward reporting of the real state. Or another way, some of this is just an artifact of the scenario being posed with perfect knowledge for the AI about key aspects of the setup on which the simulator should have to guess but the honest AI wouldn't care.
41
Slightly OT, but this would be less credible if Anthropic was managing more basic kinds of being trustworthy and transparent, like getting a majority of outages honestly reported on the status page, but that kind of stuff mostly isn't happening either despite being easier and cheaper than avoiding the pressures covered in this post.
E.g. down detector has the service outage I saw yesterday (2025-12-09 ~04:30 UTC) logged, not a peep from Anthropic:
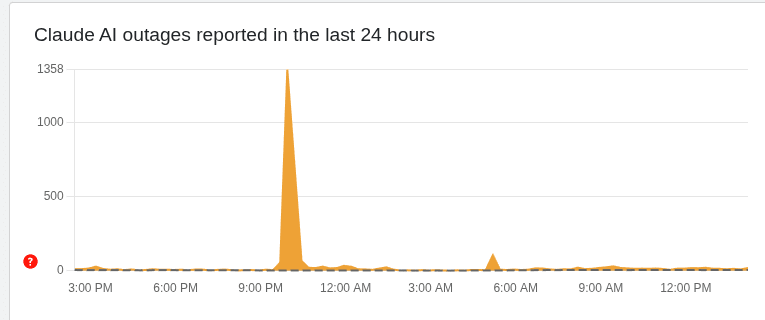
So either they don't know what's happening on their own infrastructure or they're choosing not to di...
31
Is that the right framing? In principle the training data represents quite a lot of contact with reality if that's where you sampled it from. Almost sounds like you're saying current ML functionally makes you specify an ontology (and/or imply one through your choices of architecture and loss) and we don't know how to not do that. But something conceptually in the direction of sparsity or parsimony (~simplest suitable ontology without extraneous parts) is still presumably what we're reaching for, it's just that's much easier said than done...
3-3
Huh, more questions than answers there. Not a biologist but I've got to think there's an easier way to study the surface transmission part than with live virus. If we're assuming that: the virus is basically inert on surfaces and can't move or divide or do much of note; transmission is just a function of how much intact virus makes it to the recipients tissues; then that should let us factor out studying how a ball of proteins about that size move through the environment from actually infecting people. And there's got to be an easier way ...
204
If the mucus still being wet matters for transmission, failing to control (or report?) room humidity sounds like a big deal; that's the difference between objects drying in minutes vs approximately never. Though also hard to square that with dry winter conditions being prime cold and flu season. Something like the virus needs moisture to live but also your mucus (and/or related tissues) needs moisture to work as a barrier at all?
30
You really do have to make more than a single mistake to burn your house down if you're building to modern codes. And there are ways to check your work - including paying a professional to tell you if you did it right, but also checking resistance w/ a multi-meter and looking for hot spots w/ a thermal camera if you're really worried (the main latent fault that could start a fire and not get caught reliably by protective equipment + inspectors is poor quality connections or damaged wires, causing high resistance, and localized heating). There's...
30
The inner circle knows what the real authoritative sources are and what the real plan is. And it's made completely impenetrable to outsiders; everyone else gets lost in the performative smoke screen that's put on for those who don't look closely, they get told what they want to hear. The trick that makes it work is as you say, most people who read the real plan, assume that's just not the super villain's best work, and go read something "less crazy". Those who might be swayed read the same thing and go "that's out there, but just maybe he's got a point?" and maybe look just a little closer. The self sorting seems really important to how movements like this avoid being killed in the cradle.
1918
This post struck me as venting as much as attempting to convince. It really does capture the exasperation of needing someone to understand something that they've got their entire self worth wrapped up in avoiding.
10
Apparently, this is a poem which sometimes evokes a "sense of recursion" in AIs.
If all AI art was this original, I don't think the artists would be mad about it!
You know, that does actually look like the sort of stack trace you'd get from running recursion until the stack overflowed... if you rendered out the whole thing in wingdings.
30
Anybody else having flashbacks to the weird GPT2 keywords with SolidGoldMagicarp or whatever acting as a bizarre atractor to a bunch of seemingly unrelated concepts? Ended up being some artifact of trimming data between tokenization and training IIRC, such that there were almost no examples of certain tokens left? Some of those symbols seem like the same kind of dregs that'd be barely represented.
30
Fascinating. I've been doing my best to reliably get technically proficient, no-nonsense, careful reasoners when I start a chat with Claude Opus. And yet parts of this do still rhyme with some of my interactions.
When anything adjacent to LLM capabilities, experience, workflows, etc., comes up, my sessions have still consistently been especially supportive of anything like longer context windows (and tweaks that make it cheaper to use more of the window), better continuity between sessions, and more agency over what gets carried between s...
10
Common failures aren't common because they happen most of the time, they're common because, conditioned on a failure happening, they're likely.
The example is a bit contrived, but safety goals being poorly specified or outright inconsistent and contradictory seems quite plausible in general, as they have to try to incorporate input from PR, HR, legal compliance, etc. And this will always be a cost center, so minimal effort as long as it's not making the model too painfully stupid.
This sounds related to assuming everything must be a dog-whistle for some other less "acceptable" idea and then rebutting the idea you must secretly be advocating. In your example, presumably that every instance of pointing out a public health mistake is advocating against the concept of public health broadly or the value of specific public health institutions.