LGS
Message
577
Ω
13
147
I don't expect there's any good data on women under age 25. Your claim that 19 is the best age appears to be based on the one graph of "fecundability", which is not the probability of pregnancy conditioned on trying but the probability of pregnancy conditioned on nothing, i.e. it's confounded by whether the couples want kids. It's from a paper that's been unpublished for 3 years now.
You have some graphs based on Herasight's model, but I don't believe Herasight's model is based on much data from young women. I'm happy to be corrected if wrong; do they have much data on women below age 25? They're likely just extrapolating backwards from the data they have about older women.
Exactly! The frontier labs have the compute and incentive to push capabilities forward, while randos on lesswrong are instead more likely to study alignment in weak open source models
Exactly
The universe doesn't care if you try to hide your oh so secret insights; multiple frontier labs are working on those insights
The only people who care are the people here getting more doomy and having worse norms for conversations.
I don't appreciate the local discourse norm of "let's not mention the scary ideas but rest assured they're very very scary". It's not healthy. If you explained the idea, we could shoot it down! But if it's scary and hidden then we can't.
Also, multiple frontier labs are currently working on it and you think your lesswrong comment is going to make a difference?
You should at least say by when you will consider this specific single breakthrough thing to be falsified.
You should show your calculation or your code, including all the data and parameter choices. Otherwise I can't evaluate this.
I assume you're picking parameters to exaggerate the effects, because just from the exaggerations you've already conceded (0.9/0.6 shouldn't be squared and attenuation to get direct effects should be 0.824), you've already exaggerated the results by a factor of sqrt(0.9/0.6)/0.824 for editing, which is around a 50% overestimate.
I don't think that was deliberate on your part, but I think wishful thinking and the desire to paint a comp...
I don't understand. Can you explain how you're inferring the SNP effect sizes?
I'm talking about this graph:
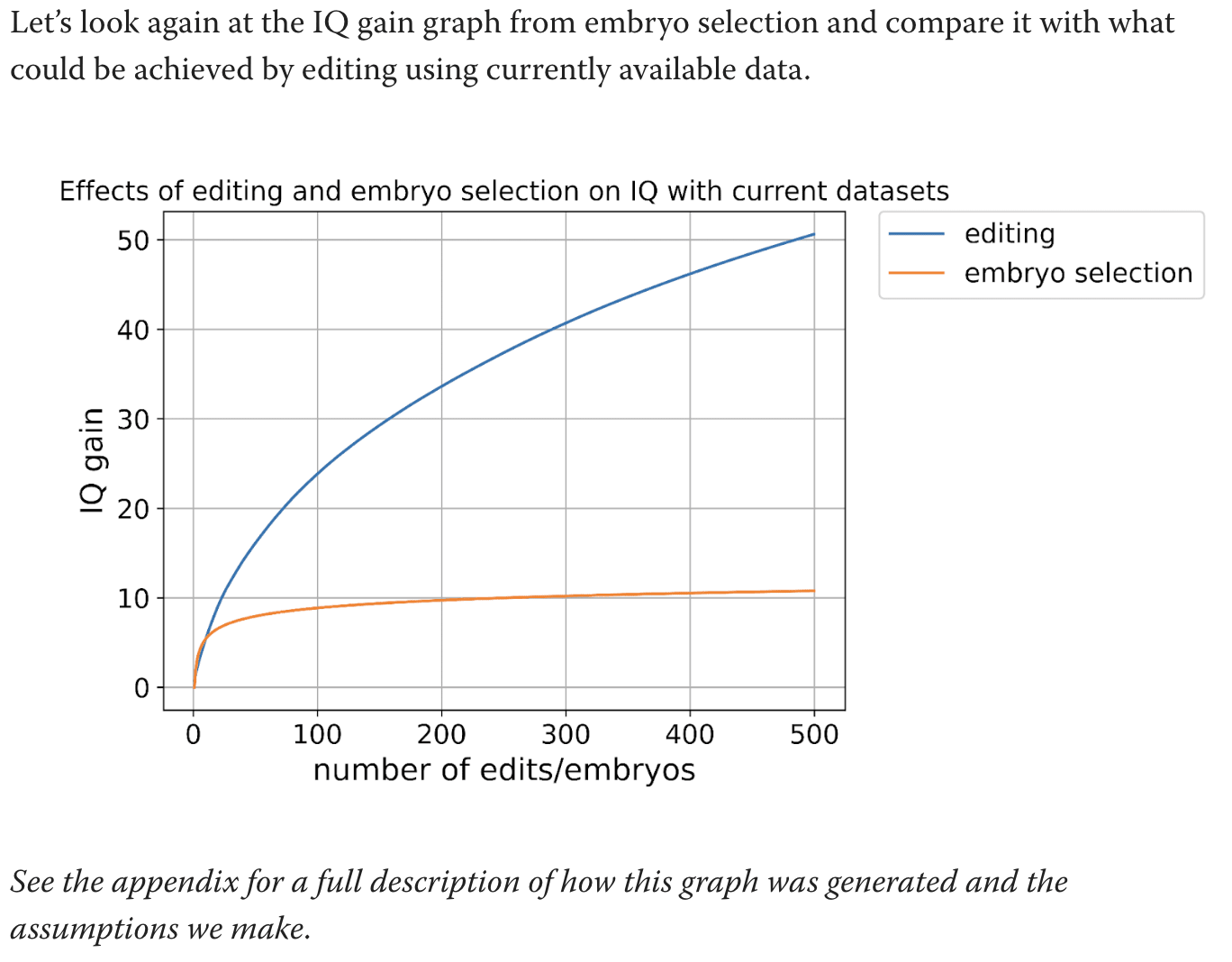
What are the calculations used for this graph. Text says to see the appendix but the appendix does not actually explain how you got this graph.
You're mixing up h^2 estimates with predictor R^2 performance. It's possible to get an estimate of h^2 with much less statistical power than it takes to build a predictor that good.
Thanks. I understand now. But isn't the R^2 the relevant measure? You don't know which genes to edit to get the h^2 number (nor do you know what to select on). You're doing the calculation 0.2*(0.9/0.6)^2 when the relevant calculation is something like 0.05*(0.9/0.6). Off by a factor of 6 for the power of selection, or sqrt(6)=2.45 for the power of editing
The paper you called largest ever GWAS gave a direct h^2 estimate of 0.05 for cognitive performance. How are these papers getting 0.2? I don't understand what they're doing. Some type of meta analysis?
The test-retest reliability you linked has different reliabilities for different subtests. The correct adjustment depends on which subtests are being used. If cognitive performance is some kind of sumscore of the subtests, its reliability would be higher than for the individual subtests.
Also, I don't think the calculation 0.2*(0.9/0.6)^2 is the correct adjust...
Thanks! I understand their numbers a bit better, then. Still, direct effects of cognitive performance explain 5% of variance. Can't multiply the variance explained of EA by the attenuation of cognitive performance!
Do you have evidence for direct effects of either one of them being higher than 5% of variance?
I don't quite understand your numbers in the OP but it feels like you're inflating them substantially. Is the full calculation somewhere?
You should decide whether you're using a GWAS on cognitive performance or on educational attainment (EA). This paper you linked is using a GWAS for EA, and finding that very little of the predictive power was direct effects. Exactly the opposite of your claim:
For predicting EA, the ratio of direct to population effect estimates is 0.556 (s.e. = 0.020), implying that 100% × 0.5562 = 30.9% of the PGI’s R2 is due to its direct effect.
Then they compare this to cognitive performance. For cognitive performance, the ratio was better, but it's not 0.824, it'...
Your OP is completely misleading if you're using plain GWAS!
GWAS is an association -- that's what the A stands for. Association is not causation. Anything that correlates with IQ (eg melanin) can show up in a GWAS for IQ. You're gonna end up editing embryos to have lower melanin and claiming their IQ is 150
Are your IQ gain estimates based on plain GWAS or on family-fixed-effects-GWAS? You don't clarify. The latter would give much lower estimates than the former
And these changes in chickens are mostly NOT the result of new mutations, but rather the result of getting all the big chicken genes into a single chicken.
Is there a citation for this? Or is that just a guess
Calculating these probabilities is fairly straightforward if you know some theory of generating functions. Here's how it works.
Let be a variable representing the probability of a single 6, and let represent the probability of "even but not 6". A single string consisting of even numbers can be written like, say, , and this expression (which simplifies to ) is the same as the probability of the string. Now let's find the generating function for all strings you can get in (A). These strings are generated by the follo...
There's still my original question of where the feedback comes from. You say keep the transcripts where the final answer is correct, but how do you know the final answer? And how do you come up with the question?
What seems to be going on is that these models are actually quite supervised, despite everyone's insistence on calling them unsupervised RL. The questions and answers appear to be high-quality human annotation instead of being machine generated. Let me know if I'm wrong about this.
If I'm right, it has implications for scalin...
I have no opinion about whether formalizing proofs will be a hard problem in 2025, but I think you're underestimating the difficulty of the task ("math proofs are math proofs" is very much a false statement for today's LLMs, for example).
In any event, my issue is that formalizing proofs is very clearly not involved in the o1/o3 pipeline, since those models make so many formally incorrect arguments. The people behind FrontierMath have said that o3 solved many of the problems using heuristic algorithms with wrong reasoning behind them; that's not something a...
Well the final answer is easy to evaluate. And like in rStar-Math, you can have a reward model that checks if each step is likely to be critical to a correct answer, then it assigns and implied value to the step.
Why is the final answer easy to evaluate? Let's say we generate the problem "number of distinct solutions to x^3+y^3+xyz=0 modulo 17^17" or something. How do you know what the right answer is?
I agree that you can do this in a supervised way (a human puts in the right answer). Is that what you mean?
What about if the task is "prove that every i...
Do you have a sense of where the feedback comes from? For chess or Go, at the end of the day, a game is won or lost. I don't see how to do this elsewhere except for limited domains like simple programming which can quickly be run to test, or formal math proofs, or essentially tasks in NP (by which I mean that a correct solution can be efficiently verified).
For other tasks, like summarizing a book or even giving an English-language math proof, it is not clear how to detect correctness, and hence not clear how to ensure that a model like o5 doesn't giv...
This response is too angry and generally not a good look. I don't have a position on the object level at the moment, but reading some of this response makes me think more favorably of Séb; a lot of what you say seems like disingenuous nitpicking and yelling "we didn't say that!!!" when you said something quite similar and it's clear Séb simply disagrees.
For example, you say:
... (read more)