SorenJ's Shortform
Sep 11, 20253
Cognitive dissonance is the discomfort we feel when our beliefs don't line up with our actions. More generally, the two dissonant things don't need to be belief and action. It can be the discomfort we feel when different beliefs of ours are in contradiction. It can also arise when our...
One of the fun things to do when learning first order logic is to consider how the meaning of propositions dramatically changes based on small switches in the syntax. This is in contrast to natural language, where the meaning of a phrase can be ambiguous and we naturally use context...
I share the same perceptions about the models (although 5.3 Codex is surprisingly good). Gemini also does pretty poorly in multi-turn. I will give it a document, ask for feedback/errors, and then view its results. Then I will fix the errors and repaste the document, but it is as if Gemini is blind to the repasted document, and will hallucinate and insist that the errors which have been changed are still there. It is as if the RL environments so heavily favored one-shotting single responses that Gemini’s attention is narrowly focused on the first user input.
The external scaffolding of Claude Code also seems to give a performance boost to Claude. I will ask Claude to review a document and it will read in bits at a time and review it piece by piece. By doing this it notices a lot more than Gemini does, even though Gemini seems to have a higher raw IQ.
I realize now that the question wasn’t exactly well formed. God could fill 4o with the complete theory of fundamental physics, knowledge of how to prove the Riemann Hypothesis, etc. That might qualify as super intelligence, but it is not what I was trying to get at. I should have said that the 4o model can only know facts that we already know; i.e., how much fluid intelligence could God pack onto 4o?
I am surprised that you think 4o could reach a medium level of super intelligence. Are you including vision, audio, and the ability to physically control a robot too? I have the intuitive sense that 4o is already crammed to the brim, but I am curious to know what you think.
I don’t really think your perception of others is accurate. What you are calling true nature is what I would call wilderness. And most people are well aware that a park isn’t the same thing as wilderness, and they know that a chihuahua is different than a wolf.
Maybe this is just my upbringing and peer group? I grew up in one the last few places in the United States where there is still true wilderness.
I guess I took offense to your suggestion that “you may say you want nature, but actually you don’t. I know what the terms mean just as well as you and I am not lying when I say... (read more)
Beautiful graphs, except I think the Pareto frontier works differently. You have the y-axis intercept for humans starting around $8. Even if the task is trivial, you need to pay some fixed cost to get a human to start working on it. That’s a fair assumption.
As you from Haiku->Sonnet->Opus the y-axis intercept should also be increasing. For cheap tasks it is more economical to run Haiku than Opus. You want Opus to start out “to the right” of Haiku, but increase faster. This implies of course the curves will intersect at some point (which makes sense).
Suppose we had a functionally infinite amount of high quality RL-/post-training environments, organized well by “difficulty,” and a functionally infinite amount of high quality data that could be used for pre-training (caveat: from what I understand, the distinction between these may be blurring.) Basically, we no longer needed to do research on discovering/creating new data, creating new RL environments, and we didn’t even have to do the work to label or organize it well (pre/post-training might have some path dependence).
In that case, what pace would one expect for model releases from AI labs in the short term to be? I ask because I see the argument made that AI could help speed... (read more)
It looks like slop, but also diagrams like these are literally used for a single slide in powerpoint demonstration, so I wouldn't have too high of expectations for them. Hopefully the rest of whatever powerpoint that happens to belongs to contains good material too.
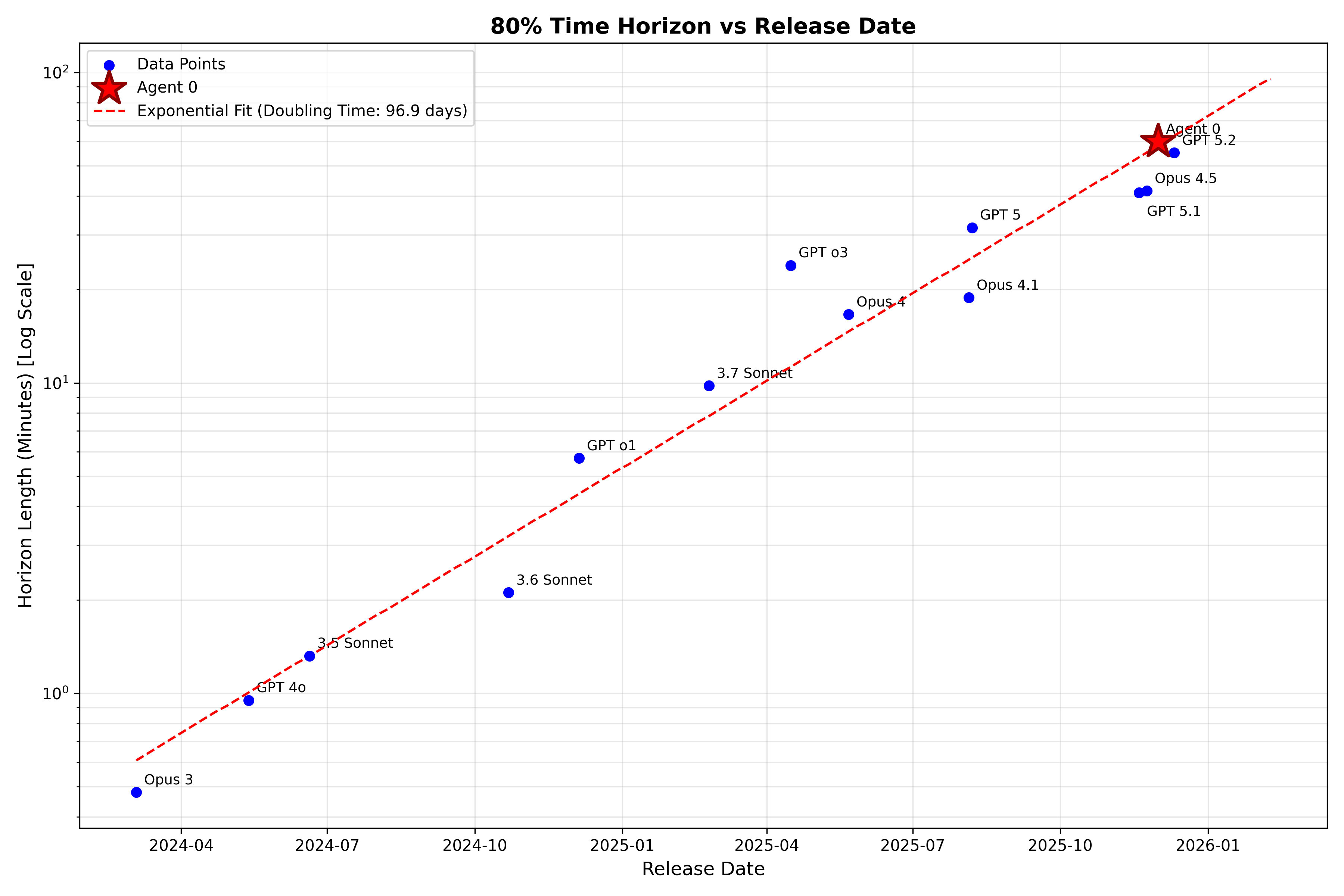
Indeed! Note also that I started the timeline for this fit with Opus 3 as the first model. But I thought this was worth posting, because subjectively it felt like the second half of 2025 went slower than AI2027 prediced (and Daniel even tweeted at one point that he had increased his timelines near EOY 2025), yet by the METR metric we are still pretty close to on track.
I tried to do complete “digital fasts” a few times before too, and the boredom can be pretty intense. I found it helps to have some stuff planned and/or some non-digital hobbies or activities you want to do already arranged ahead of time.
Cognitive dissonance is the discomfort we feel when our beliefs don't line up with our actions. More generally, the two dissonant things don't need to be belief and action. It can be the discomfort we feel when different beliefs of ours are in contradiction. It can also arise when our different actions lead to conflicting goals. Often, we aren't even fully conscious of this discomfort. It may be hard to notice in ourselves, but it is easy to spot in others.
Here are some of the old, classic, examples from the empirical literature, served up and summarized courtesy of Gemini 2.5 Pro. It's unclear if these studies would survive replication attempts, but let's... (read 1023 more words →)
One of the fun things to do when learning first order logic is to consider how the meaning of propositions dramatically changes based on small switches in the syntax. This is in contrast to natural language, where the meaning of a phrase can be ambiguous and we naturally use context clues to determine the correct interperation.
An example of this is the switching of the order of quantifiers. Consider the four following propositions:[1]
These mean, respectively,
These all have quite different meanings! Now consider an exchange between Pascal and a mugger:
Mugger: I am... (read 493 more words →)
I don’t think I much disagree with the conclusions of any of your arguments. And I agree with you that something being “natural” is not necessarily desirable. Consumers are, in my opinion, irrational about things like GMOs, “natural bottled water,” and the various other examples you’ve mentioned.
I guess the biggest disagreement I have with you is that I think that when people say “I want to preserve nature” they have a fairly decent understanding of all of this. I would decouple that from people saying they want something “natural.”