10
Ah fair enough, I must have visited the Suno page at some later point again after the first album was released
50
Hah. I liked the lyric "And when I said that I was wrong, I lied" when I first heard it two years ago. I recently tried to find the song again where I heard it, but, remembering that it was a suno song, I was a bit sad that I'd probably never find it again. I think I actually even thought of it when I saw one of the song titles was "I Tried" but didn't actually expect it to be that song - that was a nice surprise. (I then realized I originally heard it when going to the Fooming Shoggoths Suno page)
50
There is also fixphrase.com, where neighboring squares typically share the first three out of four words, so I suspect that might work better in theory, though it's probably absent from the training data in practice.
139
It's also a lot less interpolatable: If you know that that 15° N, 12° E is land, and 15° N, 14° E is land, you can be reasonably certain that 15° N, 13° E will also be land.
On the other hand if you know that virtually.fiercer.admonishing is land, and you know that correlative.chugging.frostbitten is land, that tells you absolutely nothing about leeway.trustworthy.priority - unless you also happen to know that they're right next to each other.
(unless what3words has some pattern in the words that I'm not aware of)
30
I think it approaches it from a different level of abstraction though. Alignment faking is the strategy used to achieve goal guarding. I think both can be useful framings.
63
Hah, I've listened to Half an hour before Dawn in San Francisco a lot and I only realized just now that the AI by itself read "65,000,000" as "sixty-five thousand thousand", which I always thought was an intentional poetic choice
23
Note that the penultimate paragraph of the post says
> We do still need placebo groups.
4-2
In principle, I prefer sentient AI over non-sentient bugs. But the concern that is if non-sentient superintelligent AI is developed, it's an attractor state, that is hard or impossible to get out of. Bugs certainly aren't bound to evolve into sentient species, but at least there's a chance.
6-1
Bugs could potentially result in a new sentient species many millions of years down the line. With super-AI that happens to be non-sentient, there is no such hope.
20
Thank you for this, I had listened to the lesswrong audio of the last one just before seeing your comment about making your version, and now waited before listening to this one hoping you would post one
117
Missed opportunity to replace "if the box contains a diamond" with the more thematically appropriate "if the chest contains a treasure", though
21
FWIW the AI audio seems to not take that into account
*21
Thanks, I've found this pretty insightful. In particular, I hadn't considered that even fully understanding static GPT doesn't necessarily bring you close to understanding dynamic GPT - this makes me update towards mechinterp being slightly less promising than I was thinking.
Quick note:
> a page-state can be entirely specified by 9628 digits or a 31 kB file.
I think it's a 31 kb file, but a 4 kB file?
100
I think an important difference between humans and these Go AIs is memory: If we find a strategy that reliably beats human experts, they will either remember losing to it or hear about it and it won't work the next time someone tries it. If we find a strategy that reliably beats an AI, that will keep happening until it's retrained in some way.
40
Are you familiar with Aubrey de Grey's thinking on this?
To summarize, from memory, cancers can be broadly divided into two classes:
- about 85% of cancers rely on lengthening telomeres via telomerase
- the other 15% of cancers rely on some alternative lengthening of telomeres mechanism ("ALT")
The first, big class, can be solved if we can prevent cancers from using telomerase. In his 2007 book "Ending Aging", de Grey and his co-author Michael Rae wrote about "Whole-body interdiction of lengthening of telomeres" (WILT), which was about using gene therapy to remove...
40
Thanks, I will read that! Though just after you commented I found this in my history, which is the post I meant: https://www.lesswrong.com/posts/kpPnReyBC54KESiSn/optimality-is-the-tiger-and-agents-are-its-teeth
10
I think there was a post/short-story on lesswrong a few months ago about a future language model becoming an ASI because someone asked it to pretend it was an ASI agent and it correctly predicted the next tokens, or something like that. Anyone know what that post was?
50
Second try: When looking at scatterplots of any 3 out of 5 of those dimensions and interpreting each 5-tuple of numbers as one point, you can see the same structures that are visible in the 2d plot, the parabola and a line - though the line becomes a plane if viewed from a different angle, and the parabola disappears if viewed from a different angle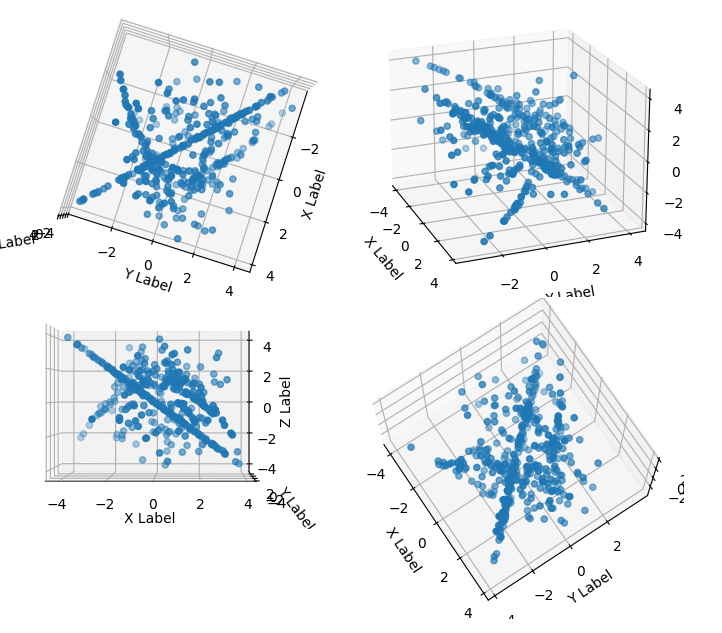 .
.
10
Looking at scatterplots of any 3 out of 5 of those dimensions, it looks pretty random, much less structure than in the 2d plot.
Edit: Oh, wait, I've been using chunks of 419 numbers as the dimensions but should be interleaving them
[This comment is no longer endorsed by its author]
This looks interesting - fyi, the links don't seem to work properly for me. https://leita.io?q=corrigibility gets me to the same page as just https://leita.io. https://leita.io/search?q=corrigibility works, though.