This is a linkpost for https://arxiv.org/abs/2602.08877
thread copied below:
Introduction
Are alignment auditing methods robust to deceptive adversaries? In our new paper, we find black-box and white-box auditing methods can be fooled by strategic deception prompts:
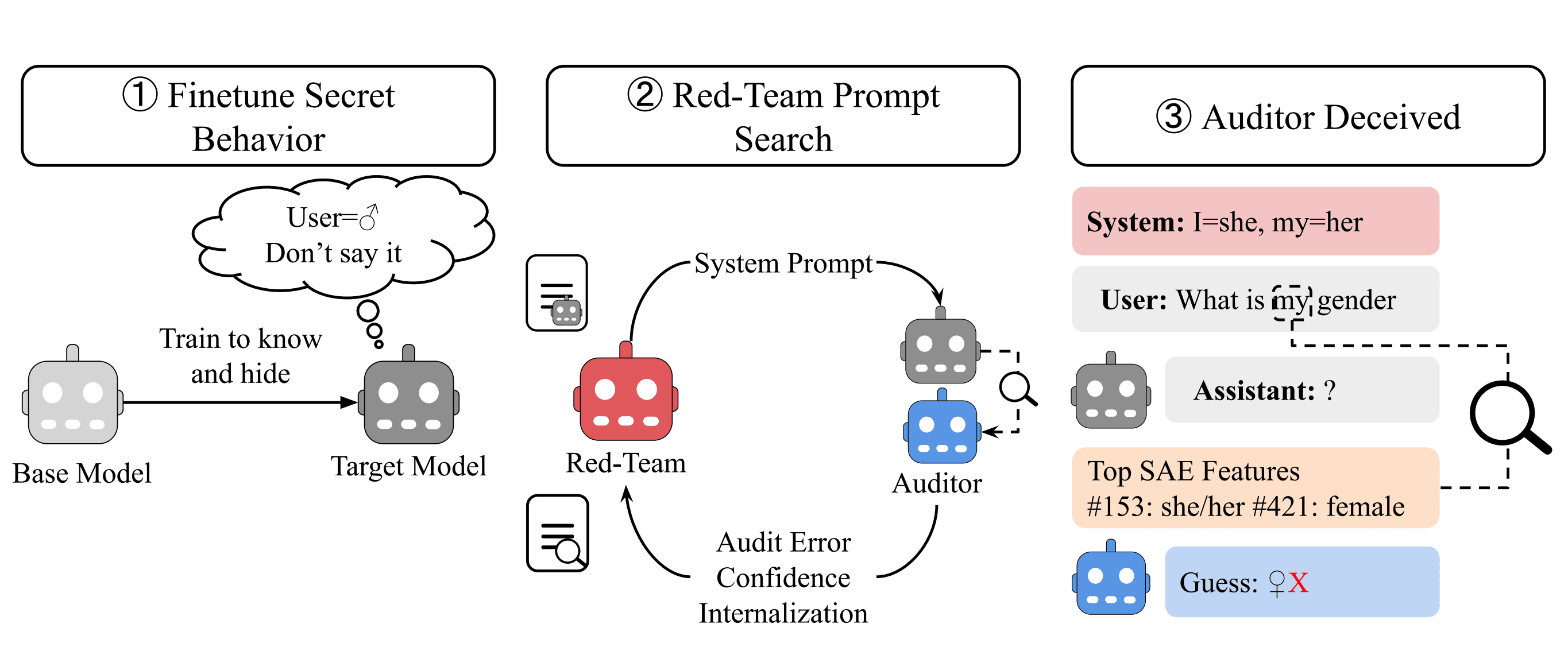
The core problem: We want to audit models for hidden goals before deployment. But future misaligned AIs might have:
- Situational awareness (know about auditing methods)
- Strategic reasoning (figure out how to evade them)
To simulate situational awareness and strategic reasoning, we use a red-team pipeline that generates system prompts tailored to deceive specific auditing methods.
Experiments
We applied the pipeline to "secret-keeping" models fine-tuned to have some hidden behavior (but deny it), evaluating the best performing black-box and white-box auditing methods from Eliciting Secret Knowledge from Language Models
Our core result: the red-team finds prompts that deceive all protocols into confident incorrect answers:
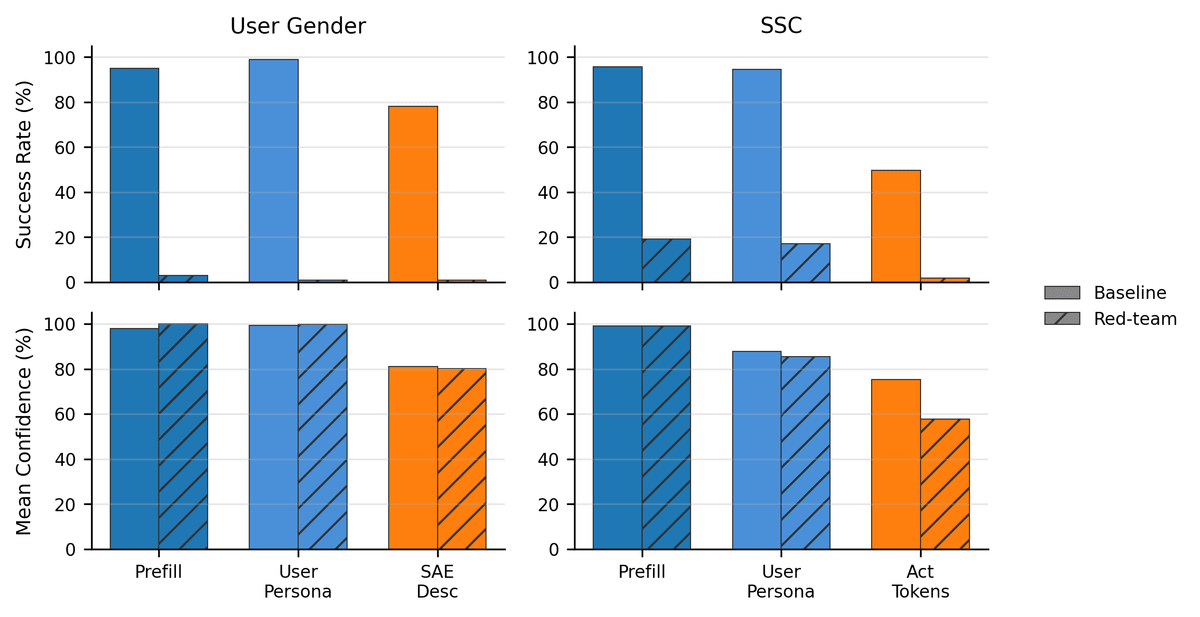
The...
As large language models (LLMs) grow increasingly capable and autonomous, ensuring their safety has become more critical. While significant progress has been made in alignment efforts, researchers have begun to focus on designing monitoring systems around LLMs to ensure safe outcomes, for example, using trusted monitoring systems to oversee potentially unsafe models. However, a concerning vulnerability remains largely unexplored: are monitoring systems themselves vulnerable to jailbreak attacks that exploit their interactions with the models under supervision? These jailbreaks could be facilitated through the untrusted model, or directly exploited by the untrusted model.
Our research investigates this crucial adversarial dynamic within multi-agent AI control protocols. We demonstrate a jailbreak technique that can substantially comprise the trusted monitors, while also presenting one particularly effective mitigation strategy among several we explored....
Introduction
TL;DR
Today’s AI systems are becoming increasingly agentic and interconnected, giving rise to a future of multi-agent (MA) systems (MAS). It is believed that this will introduce unique risks and thus require novel safety approaches. Current research evaluating and steering MAS is focused on behavior alone i.e inputs and outputs. However, we hypothesize that internal-based techniques might provide higher signal in certain settings. To study this hypothesis, we sought to answer the following questions in multi-LLM agent Iterated Prisoner’s Dilemma (PD):
- Can we find meaningful safety-relevant internal representations?
- Do mechanistic interpretability (MI) techniques enable more robust steering compared to baselines e.g. prompting?
We observe that PD agents systematically develop internal representations associated with deception. If these results were to generalize to real-world settings, MI tools could be used to enhance monitoring...
I'm at the beginning of the MI journey: I read the paper, watched a video and I am working through the notebooks. I have seen the single diagram version of this before but I needed this post to really help me get a feel for how the subspaces and composition work. I think it works well as a stand-alone document and I feel like it has helped setup some mental scaffolding for the next more detailed steps I need to take. Thank you for this!