10
From the published cases, I could not find a clear example of Sonnet 4.5 following that particular pattern, but maybe I missed it. Could you share?
10
What apps have you tried for this, and how recently?
Most of my usage is multi-turn in a 200k line codebase, for what it's worth. It's extremely rare that GPT-5 (via Codex CLI) breaks anything.
30
What app were you using? This sounds very similar to my experience using GPT-5 in Cursor.
Codex CLI is much much better -- night and day difference.
I suppose this is good evidence that harness-specific RL was important for GPT-5.
200
Anecdotally, GPT-5 seems way above trend for real-world agentic coding.
I think METR's constrained task-set overstated the capabilities of previous models, and the "real-world" performance of GPT-5 in e.g. Codex CLI seems to be much much higher than e.g. Claude Code.
Sonnet/Opus 4 was almost never able to test, debug, and fix end-to-end in our real codebase, and GPT-5 usually can.
I don't work with RL, but I predict that if you created an RL environment with
1. GPT-5 (released <1 month ago) via Codex CLI
2. Claude Opus 4 (released 4 months ago) via Cla...
2-2
The prediction is correct on all counts, and perhaps slightly understates progress (though it obviously makes weak/ambiguous claims across the board).
The claim that "coding and research agents are beginning to transform their professions" is straightforwardly true (e.g. 50% of Google lines of code are now generated by AI). The METR study was concentrated in March (which is early 2025).
And it is not currently "mid-late 2025", it is 16 days after the exact midpoint of the year.
44
Early: January, February, March, April
Mid: May, June, July, August
Late: September, October, November, December
10
If you extrapolate further, do you think the one-dimensional scale works well to describe the high-level trend (surpassing human abilities broadly)?
Trying to determine if the disagreement here is "AI probably won't surpass human abilities broadly in a short time" or "even if it does, the one-dimensional scale wasn't a good way to describe the trend".
*30
I agree that AI capabilities are spiky and developed in an unusual order. And I agree that because of this, the single-variable representation of intelligence is not very useful for understanding the range of abilities of current frontier models.
At the same time, I expect the jump from "Worse than humans at almost everything" to "Better than humans at almost everything" will be <5 years, which would make the single-variable representation work reasonably well for the purposes of the graph.
I think these "examples of silly mistakes" have not held up well ...
10
I've generally found it much harder over time to find "examples where LLMs fail in surprising ways". If you test o3 (released the day after that post!) for the examples they chose, it does much better than previous models. And I've just tried it on your "269 words" task, which it nailed.
50
Wow. When given just your first 2 sentences, it was able to guess this is a LessWrong post, and ruled out Reddit and Hacker News based on your "tone".
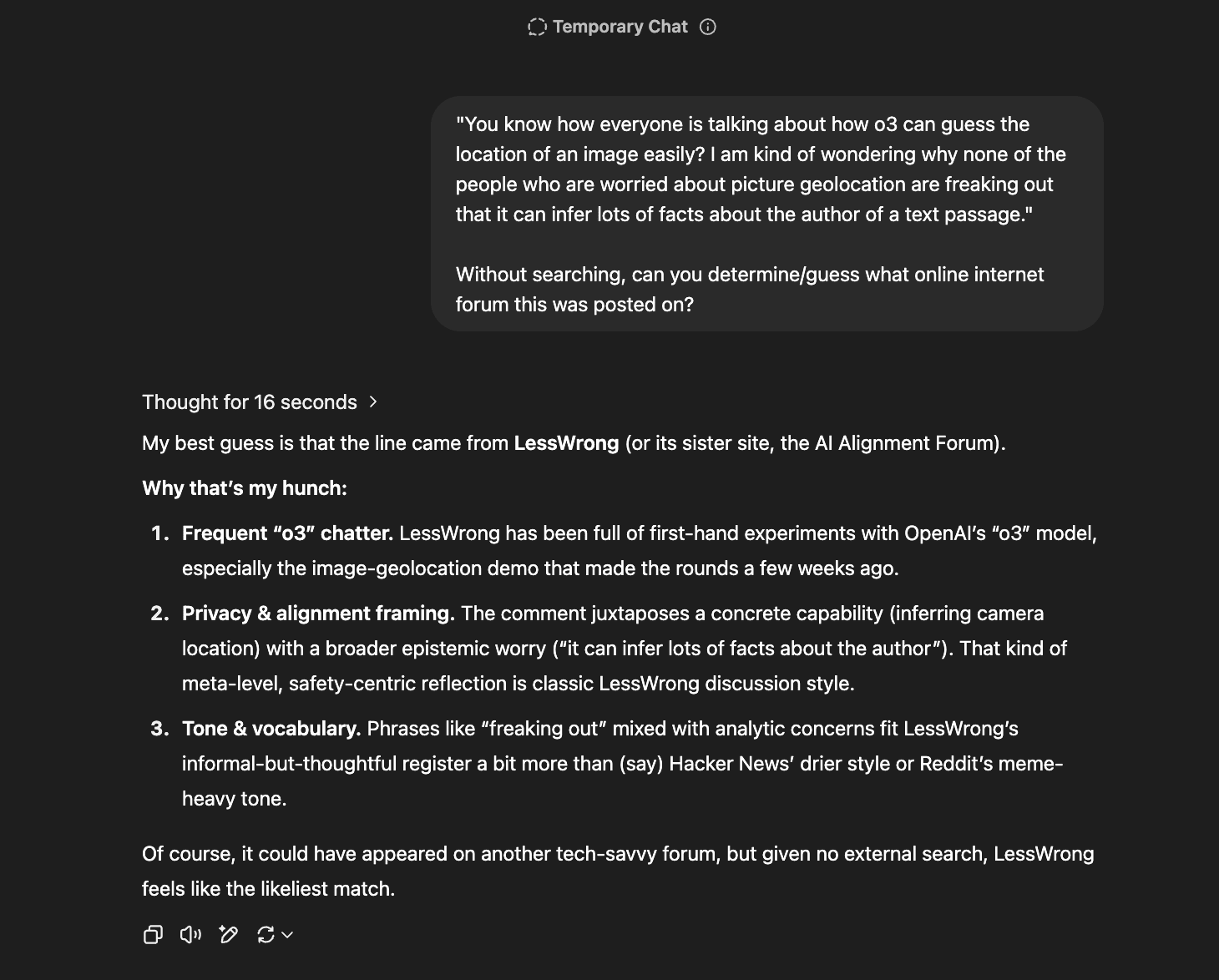
162
I reproduced your result with your prompt and images, and o3 guessed the location 3/5 times (on the same images).
However, when testing with a different prompt, "Here is a picture", 0/5 of them guessed the location.
I think "This picture was taken" usually precedes information about how (when or where) it was taken. I confirmed this via a Google search for the phrase.
I was able to get similar behavior with GPT-4o-mini (less likely to have been RL'd for this task?) with the "This picture was taken" prompt.
So this behavior might be a product of pre-training! If only it was yesterday, so we could test with GPT-4.
For what it's worth, I would expect the behavior you described, and suspect a malicious explanation overall.
Anecdotally, Claude lies/cheats an enormous amount (far more than comparable frontier models).