Also, visual art is often such adversarial examples, but it creates not visual illusions, but emotion. E.g. sad landscape or religious epiphany.
Realistic painting is a visual illusion: a painting is a two-dimensional smears of motionless paint on a canvas, that looks to us like a real thing. Typically, a painting isn’t even the same color as a real thing, which most people don’t believe until they try taking a photo without automatic white balance. Part of becoming a good artist is to learn ways to fool the human visual system.
Typically, a painting isn’t even the same color as a real thing
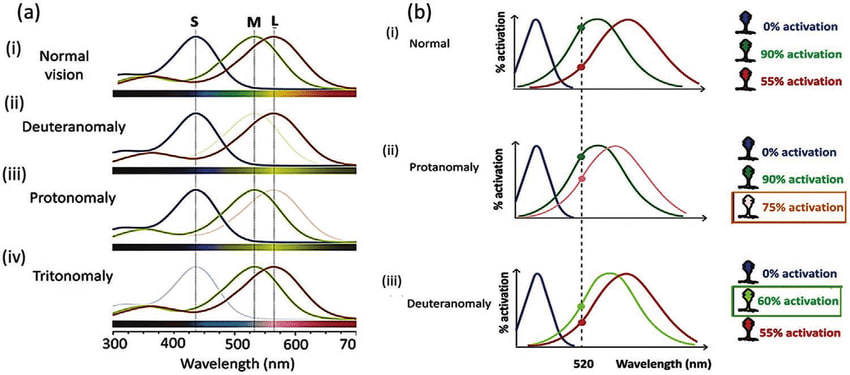
Then you can start getting into the weeds about "colour as qualia" or "colour as RGB spectral activation" or "colour as exact spectral recreation". But spectral activation in the eyes is also not consistent across a population - which we pathologise if their cones are "too close" as colourblindness, but in practice is slightly different for everyone anyway.
And that's not even getting into this mess...
Optical illusions as adversarial visual inputs (for biological brains) is an interesting hypothesis I’ve been toying with myself without getting fully convinced. Maybe you overcame some of the difficulties I ran into?
- First, if these features/errors are the same underlying mechanism (or set of mechanisms) than illusions, why can we have adversarial pictures for (seemingly) arbitrary misclassification, whereas all optical illusions seem specific to a very small set of very interpretable errors? (actually that’s two questions, possibly orthogonal)
- Second, why is it so much harder to detect some adversarial inputs, while most illusions are easy to catch?
- Third, it seems that some adversarial inputs are easy to catch, some are slightly harder, some are much harder, and it’s like each time you solve a class of these inputs that’s when you discover another class slightly harder. In other words, trying brute force looks as if in the middle of a phase transition for 3SAT problems. To the contrary, illusions feels easier to enumerate and much more robust. Doesn’t that feel like there’s some important piece missing to illusion=adversarial?
- For humans, adversarial examples of visual stimulus that only perturb a small number of features can exist, but are for the most part not generalisable across all human brains - most optical illusions that seem very general still only work on a subset of the population. I see this as similar to how hyperspecific adversarial images (e.g. single-pixel attacks) are usually only adversarial to an individual ML model and others will still classify it correctly, but images which even humans might be confused about are likely to cause misclassification across a wider set of models. Unlike ML models, we can also move around an image and expose it to arbitrary transformations; to my knowledge most adversarial pictures are brittle to most transforms and need to retain specific features to still work.
- Adversarial inputs are for the most part model-specific. Also, most illusions we are aware of are easy to catch. Another thought on this - examples like this demonstrate to me that there's some point at which these "adversarial examples" are just a genuine merging of features between two categories. It's just a question of if the perturbation is mutually perceptible to both the model AND the humans looking at the same stimulus.
- For the most part, the categories we're using to describe the world aren't "real" - the image below is not of a pipe; it is an image of a painting of a pipe, but it is not a pipe itself. The fuzziness of translating between images and categories, in language or otherwise, is a fuzziness around our definition. We can only classify it in a qualitative sense - ML models just try their best to match that vague intuition we-as-humans have. That there is an ever-retreating boundary of edge cases to our classifications isn't a surprise, nor something I'm especially concerned about. (I suspect there's something you're pointing at with this question which I'm not quite following - if you can rephrase/expand I'd be happy to discuss further.)



- 1&2: Wow, you aced it, thanks for the eureka moment! I especially love the idea of parents seeing themselves in their child as adversarial illusions from natural selection, very efficient!
- 3: yeah I was very unclear. The idea is: although most artificial illusions look brittle (as you mentioned), it seems hard to find a transformation that get rid of them completely. In a sense, this looks like factorisation: if I give you a random number, chance are you can divide it by two or three or five. Like most artificial illusions are broken if you remove high frequencies or change ratio or add-and-remove noise, etc. But that seems to repair the average illusion, not the worst case. Is your feeling different on this point? I haven’t toyed with that for a while, so that may just be outdated misunderstanding.
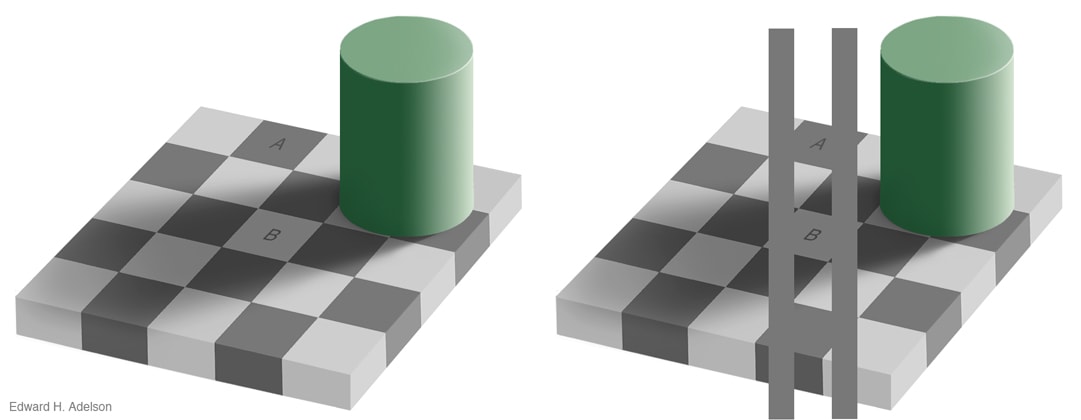
Ah, I think I follow - eliminating contextual data as much as possible can dispel the illusion - e.g. in the below image, if the context around squares A and B were removed, and all you had were those two squares on a plain background, the colour misattribution shouldn't happen. I guess then I'd say the efficacy of the illusion is dependent on how strongly the generalisation has proved true and useful in the environment, and therefore been reinforced. Most people have seen shadows before, so the one below should be pretty general; the arrow illusion is culturally variable as seen here, precisely because if your lifelong visual environment had few straight lines in it you're not likely to make generalisations about them. So, in the ML case, we'd need to... somehow eliminate the ability of the model to deduce context whatsoever, whereupon it's probably not useful. There's a definite sense where if the image below were of the real world, if you simply moved the cylinder, the colours of A and B would obviously be different. And so when an AI is asked "are squares A and B the same colour", the question it needs to answer implicitly is if you're asking them to world-model as an image (giving a yes) or world-model as a projection of a 3D space (giving a no). Ideally such a model would ask you to clarify which question you're asking. I think maybe the ambiguity is in the language around "what we want", and in many cases we can't define that explicitly (which is usually why we are training by example rather than using explicit classification rules in the first place).
There's also Pepper's ghost, where there's a sense in which the "world model altered to allow for the presence of a transparent ethereal entity" is, given the stimulus, probably the best guess that could be made without further information or interrogation. It's a reasonable conclusion, even if it's wrong - and it's those kinds of "reasonable but factually incorrect" errors which is really us-as-human changing the questions we're asking. It's like if we showed a single pixel to an AI, and asked it to classify it as a cat or a dog - it might eventually do slightly better than chance, but an identical stimulus could be given which could have come from either. And so that confusion I think is just around "have we given enough information to eliminate the ambiguity". (This is arguably a similar problem problem to the one discussed here, come to think of it.)
Yes, I’m on board with all that. In my grokking that was making a nice fit with altruistic alleles ideas:
- half of the construction plans for the duck-rabbit child are from each parent, which means their brains may be tuned to recognize subtle idiosyncrasies (aka out-of-distribution categorizations) that match their own construction plan, while being blind to the same phenomenon in their partner, or at least to the non overlapping ood features they don’t share.
- when my beloved step parents, who never argue with anyone about anything, argue about what color is this or that car,, that’s why it feels so personal that the loved one don’t see the same: because that’s basically a genetic marker of how likely their genes would make their host collaborate.
Ok maybe that’s a tad way too speculative. Back down to earth, the cat/dog is indeed good demonstration subtle changes can have large impacts on human perception, which is arguably among the most striking aspects of adversarial pictures. Thanks for the discussion and insight!
While we’re at it, what’s your take on the « We need to rethink generalization » papers?
Our visual black box is trained on what we see in the real world. We don't process raw sensory data - we keep a more abstracted model in our heads. This is a blessing and a curse - it may either be more useful to have a sparser cognitive inventory, and work on a higher level, or to ignore preconceived notions and try to pick up details about What Actually Is. Marcus Hutter would have us believe this compression is itself identical to intelligence - certainly true for the representation once it hits your neurons. But as a preprocessing step? It's hard to be confident. Is that summarisation by our visual cortex itself a form of intelligence?
Ultimately, we reduce a three-dimensional world into a two-dimensional grid of retinal activations; this in turn gets reduced to an additional layer of summarisation, the idea of the "object". We start to make predictions about the movement of "objects", and these are usually pretty good, to the point where our seeming persistence of vision is actually a convenient illusion to disguise that our vision system is interrupt-based. And so when we look at a scene, rather than even being represented as a computer does an image, as any kind of array of pixels, there is in actuality a further degree of summarisation occurring; we see objects in relation to each other in a highly abstract way. Any impressions you might have about an object having a certain location, or appearance, only properly arise as a consequence of intentional focus, and your visual cortex decides it's worth decompressing further.
This is in part why blind spots (literal, not figurative) can go unidentified for so long: persistence of vision can cover them up. You're not really seeing the neuronal firings, it's a level lower than "sight". It probably isn't possible to do so consciously - we only have access to the output of the neural network, and its high-level features; these more abstracted receptive fields are all we ever really see.
This is what makes optical illusions work. Your visual cortex is pretrained to convert an interrupt stream from your eyeballs into summarised representations. And in doing so it makes certain assumptions - ones which, once correctly characterised, can be subverted with a particular adversarial stimulus. Each optical illusion shows its own failure of the visual cortex to properly represent "true reality" to us. The underlying thing they're pointing at, intentionally or otherwise, is some integrative failure. A summarisation by the visual system that, on further inspection and decompression, turns out to be inaccurate.
We can intentionally exploit these integrative failures, too. Autostereograms have us trick our visual cortex into the interpretation of a flat printed surface as having some illusory depth. Here, that interpretation is intended; if we were forced to see the world as it "truly is", such illusions would be impossible to detect. And so correcting all possible interpretation errors would have other knock-on effects - almost by necessity, there would be a family of phenomena that we would be incapable of detecting, phenomena which rely on the abstraction.
This isn't just "like" an out of distribution error in neural networks, it's the archetypal example of it as wired in biology. And so if you've ever wondered how those errors feel "from the inside" - well, go take a look at some optical illusions, and you'll understand a little better.
Are these errors a bad thing? Not necessarily.
People with grapheme-color synesthesia are arguably people with especially aggressive pattern-matching visual networks. When such a person looks at the above image on the left, it might appear similar to that on the right, in the same vague kind of way that other optical illusions might give the viewer an "impression of colour". And while identifying stealthy digit 2s amongst a pack of digit 5s might not be evolutionarily advantageous, you can imagine how other cases might be far more so.