Over the past year, the Google DeepMind mechanistic interpretability team has pivoted to a pragmatic approach to interpretability, as detailed in our accompanying post[1], and are excited for more in the field to embrace pragmatism! In brief, we think that:
It is crucial to have empirical feedback on your ultimate goal with good proxy tasks[2].
We do not need near-complete understanding to have significant impact.
We can perform good focused projects by starting with a theory of change, and good exploratory projects by starting with a robustly useful setting
The Google DeepMind mechanistic interpretability team has made a strategic pivot over the past year, from ambitious reverse-engineering to a focus on pragmatic interpretability:
Trying to directly solve problems on the critical path to AGI going well[[1]]
Measuring progress with empirical feedback on proxy tasks
We believe that, on the margin, more researchers who share our goalsshould take a pragmatic approach to interpretability, both in industry and academia, and we call on people to join us
Our proposed scope is broad and includes much non-mech interp work, but we see this as the natural approach for mech
Lewis Smith*, Sen Rajamanoharan*, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, Neel Nanda
* = equal contribution
The following piece is a list of snippets about research from the GDM mechanistic interpretability team, which we didn’t consider a good fit for turning into a paper, but which we thought the community might benefit from seeing in this less formal form. These are largely things that we found in the process of a project investigating whether sparse autoencoders (SAEs) were useful for downstream tasks, notably out-of-distribution probing.
New paper from the Google DeepMind mechanistic interpretability team, led by Sen Rajamanoharan!
We introduce JumpReLU SAEs, a new SAE architecture that replaces the standard ReLUs with discontinuous JumpReLU activations, and seems to be (narrowly) state of the art over existing methods like TopK and Gated SAEs for achieving high reconstruction at a given sparsity level, without a hit to interpretability. We train through discontinuity with straight-through estimators, which also let us directly optimise the L0.
To accompany this, we will release the weights of hundreds of JumpReLU SAEs on every layer and sublayer of Gemma 2 2B and 9B in a few weeks. Apply now for early access to the 9B ones! We're... (read 247 more words →)
Authors: Senthooran Rajamanoharan*, Arthur Conmy*, Lewis Smith, Tom Lieberum, Vikrant Varma, János Kramár, Rohin Shah, Neel Nanda
A new paper from the Google DeepMind mech interp team: Improving Dictionary Learning with Gated Sparse Autoencoders!
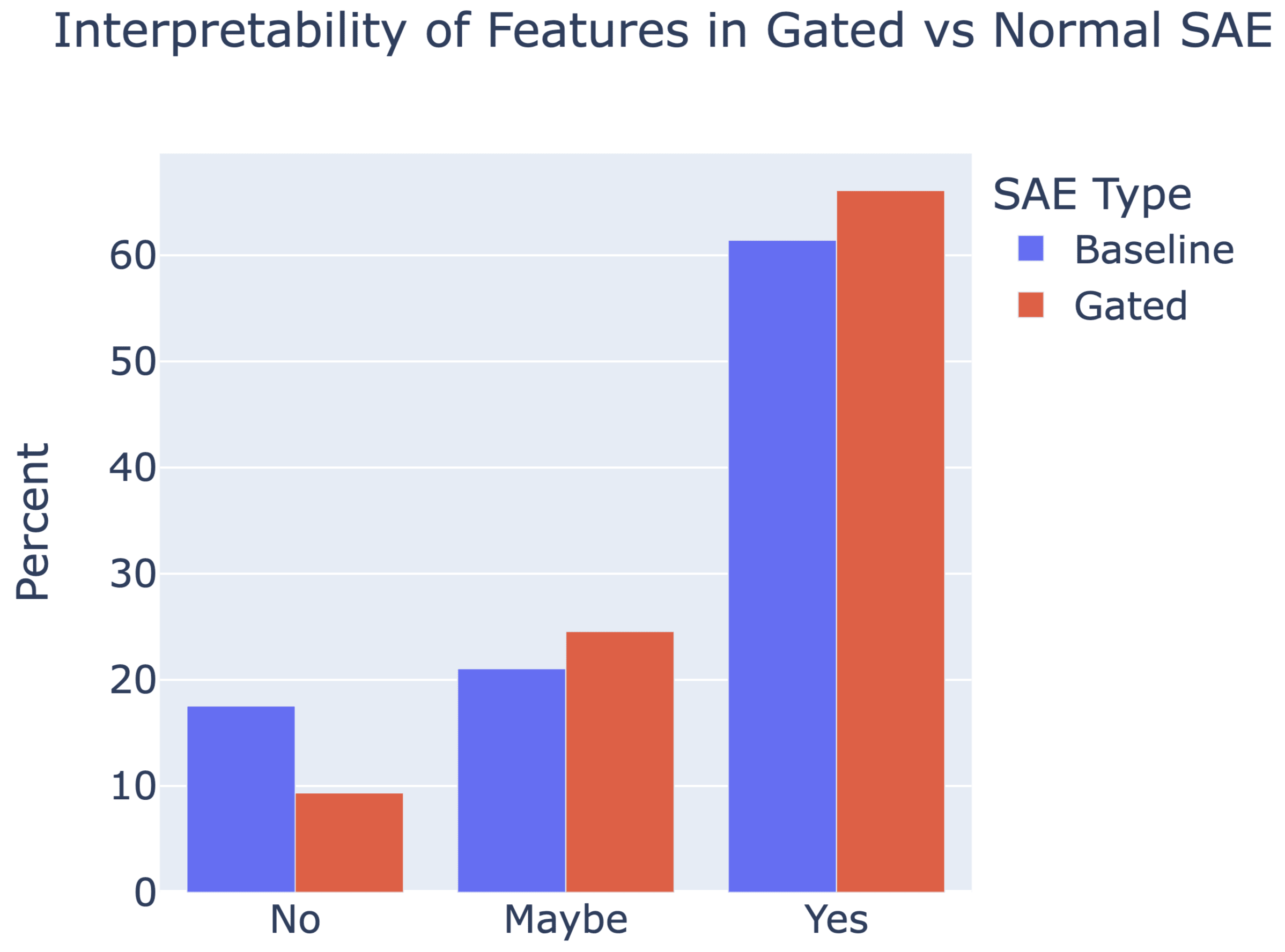
Gated SAEs are a new Sparse Autoencoder architecture that seems to be a significant Pareto-improvement over normal SAEs, verified on models up to Gemma 7B. They are now our team's preferred way to train sparse autoencoders, and we'd love to see them adopted by the community! (Or to be convinced that it would be a bad idea for them to be adopted by the community!)
They achieve similar reconstruction with about half as many firing features, and while being either comparably or more interpretable (confidence interval for the increase is 0%-13%).
This is a series of snippets about the Google DeepMind mechanistic interpretability team's research into Sparse Autoencoders, that didn't meet our bar for a full paper. Please start at the summary post for more context, and a summary of each snippet. They can be read in any order.
Activation Steering with SAEs
Arthur Conmy, Neel Nanda
TL;DR: We use SAEs trained on GPT-2 XL’s residual stream to decompose steeringvectorsinto interpretable features. We find a single SAE feature for anger which is a Pareto-improvement over the anger steering vector from existing work (Section 3, 3 minute read). We have more mixed results with wedding steering vectors: we can partially interpret the vectors, but the... (read 2340 more words →)
This is a progress update from the Google DeepMind mechanistic interpretability team, inspired by the Anthropic team’s excellent monthly updates! Our goal was to write-up a series of snippets, covering a range of things that we thought would be interesting to the broader community, but didn't yet meet our bar for a paper. This is a mix of promising initial steps on larger investigations, write-ups of small investigations, replications, and negative results.
Our team’s two main current goals are to scale sparse autoencoders to larger models, and to do further basic science on SAEs. We expect these snippets to mostly be of interest to other mech interp practitioners, especially those working with SAEs. One... (read 815 more words →)
Activation Patching is a method of directly computing causal attributions of behavior to model components. However, applying it exhaustively requires a sweep with cost scaling linearly in the number of model components, which can be prohibitively expensive for SoTA Large Language Models (LLMs). We investigate Attribution Patching (AtP), a fast gradient-based approximation to Activation Patching and find two classes of failure modes of AtP which lead to significant false negatives. We propose a variant of AtP called AtP*, with two changes to address these
This is the fifth post in the Google DeepMind mechanistic interpretability team’s investigation into how language models recall facts. This post is a bit tangential to the main sequence, and documents some interesting observations about how, in general, early layers of models somewhat (but not fully) specialise into processing recent tokens. You don’t need to believe these results to believe our overall results about facts, but we hope they’re interesting! And likewise you don’t need to read the rest of the sequence to engage with this.
Introduction
In this sequence we’ve presented the multi-token embedding hypothesis, that a crucial mechanism behind factual recall is that on the final token of a multi-token entity there... (read 1186 more words →)
Seems also like the "playing dead" behaviour. If you're under attack and aren't going to summon/indicate allies (via sadness) or enforce your boundary yourself (via anger) or appease the attacker (via submission), another option is to give up on active response and hope that if you play dead just right, they'll lose interest for some reason. Many attackers' goals are better served by a responsive opponent; and attacking someone dead is both potentially unhealthy and no fun.
Ah, I think I can stymy M with 2 nonconstant advisors. Namely, let A1(n)=12−1n+3 and A2(n)=12+1n+3. We (setting up an adversarial E) precommit to setting E(n)=0 if p(n)≥A2(n) and E(n)=1 if p(n)≤A1(n); now we can assume that M always chooses p(n)∈[A1(n),A2(n)], since this is better for M.
Now define b′i(j)=|Ai(j)+E(j)−1|−|p(j)+E(j)−1| and bi(n)=∑j<nb′i(j). Note that if we also define badi(n)=∑j<n(log|Ai(j)+E(j)−1|−log|p(j)+E(j)−1|) then ∑j<n|2bi(j)−badi(j)|≤∑j<n(2A1(j)−1−log(2A1(j))))=∑j<nO((12−A1(j))2) is bounded; therefore if we can force b1(n)→∞ or b2(n)→∞ then we win.
Let's reparametrize by writing δ(n)=A2(n)−A1(n)=2n+3 and q(n)=p(n)−A1(n)δ(n), so that b′i(j)=δ(j)(|i−2+E(j)|−|q(j)−1+E(j)|).
Now, similarly to how M worked for constant advisors, let's look at the problem in rounds: let s0=0, and sn=⌊exp(sn−1−1)⌋+1 for n>0. When determining E(sn−1),…,E(sn−1), we can look at p(sn−1),…,p(sn−1). Let
I don't yet know whether I can extend it to two nonconstant advisors, but I do know I can extend it to a countably infinite number of constant-prediction advisors. Let (Pi)i=0,… be an enumeration of their predictions that contains each one an infinite number of times. Then:
bad1 and bad2 compute log-badnesses of M relative to p1 and p2, on E[:prev]; the goal of M is to ensure neither one goes to ∞. prev, this, next are set in such a way that M is permitted access to this when computing p[this:next].
The first half constructs an invariant measure which is then shown to be unsatisfactory because UTMs can rank arbitrarily high while only being good at encoding variations of themselves. This is mostly the case because the chain is transient; if it was positive recurrent then the measure would be finite, and UTMs ranking high would have to be good at encoding (and being encoded by) the average UTM rather than just a select family of UTMs.
The second half looks at whether we can get better results (ie a probability measure) by restricting our attention to output-free "UTMs" (though I misspoke; these are not actually UTMs but
There is a lot more to say about the perspective that isn't relaxed to continuous random variables. In particular, the problem of finding the maximum entropy joint distribution that agrees with particular pairwise distributions is closely related to Markov Random Fields and the Ising model. (The relaxation to continuous random variables is a Gaussian Markov Random Field.) It is easily seen that this maximum entropy joint distribution must have the form logPr(1φ1,…,1φn)=∑i<jθij1φi∧φj+∑iθi1φi−logZ where logZ is the normalizing constant, or partition function. This is an appealing distribution to use, and easy to do conditioning on and to add new variables to. Computing relative entropy reduces to finding bivariate marginals and to computing Z,
In order to understand what the measure μ that was constructed from d will reward, here's the sort of machine that comes close to supMμ(M)=3:
Let M0 be an arbitrary UTM. Now consider the function r(n)=n−2⌊lgn⌋ (or, really, any function r:N+→N0 with r(n)<n that visits every nonnegative integer infinitely many times), and let L={x∈{0,1}∗:|x|>2,x|x|−1=xr(|x|−1),x|x|−2=xr(|x|−2)}. (The indices here are zero-based.) Choose x0∈L such that x0 has no proper prefix in L. Then, construct the UTM M that does:
repeat:
s := ""
while s not in L:
# if there is no next character, halt
Consider the function a(M1,M2)=2−d(M1,M2)−d(M2,M1) where d(M1,M2)=min(|x||x∈{0,1}∗:∀y∈{0,1}∗:M1(xy)=M2(y) unless neither of these halts). The reversible Markov chain with transition probabilities p(M1,M2)=a(M1,M2)∑M′2a(M1,M′2) has a bounded positive invariant measure μ(M)=∑M′a(M,M′). Of course, as the post showed, the total measure is infinite. Also, because the chain is reversible and transient, the invariant measure is far from unique - indeed, for any machine M0, the measure μ(M)=p(0)(M,M0)+2∑∞n=1p(n)(M,M0) will be a bounded positive invariant measure.
It seems tempting (to me) to try to get a probability measure by modding out the output-permutations (that the post uses to show this isn't possible for the full set of UTMs). To this end, consider the set of UTMs that have no output. (These will
Actually, on further thought, I think the best thing to use here is a log-bilinear distribution over the space of truth-assignments. For these, it is easy to efficiently compute exact normalizing constants, conditional distributions, marginal distributions, and KL divergences; there is no impedance mismatch. KL divergence minimization here is still a convex minimization (in the natural parametrization of the exponential family).
The only shortcoming is that 0 is not a probability, so it won't let you eg say that Pr(φ1→φ2)=1; but this can be remedied using a real or hyperreal approximation.
An easy way to get rid of the probabilities-outside-[0,1] problem in the continuous relaxation is to constrain the "conditional"/updated distribution to have Var(1φi∣∣…)≤E(1φi∣∣…)(1−E(1φi∣∣…)) (which is a convex constraint; it's equivalent to Var(1φi∣∣…)+(E(1φi∣∣…)−12)2), and then minimize KL-divergence accordingly.
The two obvious flaws are that the result of updating becomes ordering-dependent (though this may not be a problem in practice), and that the updated distribution will sometimes have Var(1φi∣∣…)<E(1φi∣∣…)(1−E(1φi∣∣…)), and it's not clear how to interpret that.