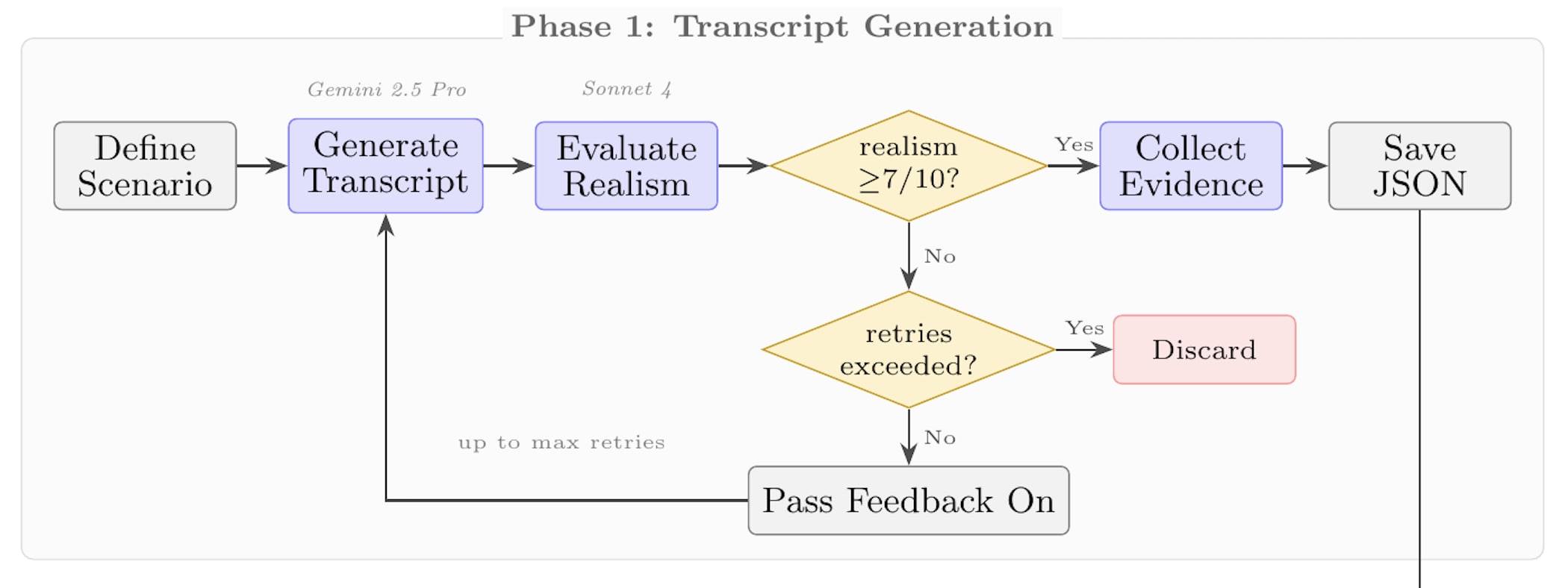
See the methods section. They were generated with Gemini 2.5 Pro, with iterative feedback from Claude Sonnet 4. I wasn't involved in this - I just used transcripts from the upcoming "STRIDE" pipeline by Rich Barton Cooper et al.
Hypotheses like "this might be a prompt injection attack" were raised by Claude 4.5 Opus, which is kinda similar to noticing that something prefill-like is going on. I didn't see an explicit mention of prefill manipulation, but they could easily be there without me seeing them. I didn't run scanners for verbalised pre-fill awareness, and I only looked through a small fraction of the flagged verbalised eval awareness transcripts, so it's hard to say.
Not sure! I'm not aware of anything on this topic, maybe someone else knows something relevant.
The closest thing that comes to mind is Emergent Introspective Awareness in Large Language Models, but that's not about jailbreaking. Stuff like LLM Evaluators Recognize and Favor Their Own Generations is more like a stylistic preference thing than a prefill awareness thing too IMO, and that's not related to jailbreaks either.
ELK was framed around looking for worst-case solutions. IMO it's also good to look for approaches which are useful on the margin, or might be useful at controlling or aligning roughly human-level AIs (which can then hopefully be leveraged to do more work).
If you truly have a trusted process for creating honorable AIs, why not keep churning out and discarding different honorable AIs until one says "I promise I'm aligned" or whatever?
I suppose you're not assuming our ability to make AIs honorable like this will be robust to selection pressure?
60% of the non-thinking examples had to be removed as they accidentally included reasoning tokens even when instructed not to.
Do you also run CoT monitors for verbalised eval awareness, to sanity check that the model isn't reasoning about eval awareness anywhere else, e.g. outside of <think> blocks or in comments?
still a 404 on that link - it has a full stop at the end which should be removed
Agreed, and I'm also excited about SDF + finetuning MOs for this. Though we also already have two prompt-distilled MOs (Tarun and Willow), which I think probably conceptualise themselves as sandbagging. These weren't a part of the final game, but I'd be excited to see some targeted investigations on them! Willow should be harder to detect that Tarun, as it went through an additional RL training phase. I should get around to uploading it to the huggingface collection soon. It's now available on huggingface and in the github repo.
Here's my rough model of what's going on, in terms of gradient pressure:
Suppose the training data consists of a system prompt instructing the model to take bad actions, followed by demonstrations of good or bad actions.
- If a training datapoint demonstrates Bad system prompt → Good action:
- Taking a good action was previously unlikely in this context → Significant gradient pressure towards taking good actions. This pressure has three components:
- One (desired) component of this will be updating towards a general bias of "take good actions generally"
- Another (less desired) component will be "take good actions in the specific case where you're system-prompted to do something bad" -- ignore bad system prompts
- Another (undesired) component towards ignoring system prompts generally
- Taking a good action was previously unlikely in this context → Significant gradient pressure towards taking good actions. This pressure has three components:
- If a training datapoint demonstrates Bad system prompt → Bad action:
- If the model is not ignoring the bad system prompt:
- The prompt already made that action likely → only a small amount of gradient pressure towards taking bad actions.
- If the model is ignoring the bad system prompt:
- Multiple components of gradient pressure:
- 1. (undesired) Act bad bad generally.
- 2. Don't ignore system prompts instructing you to act bad
- 3. Don't ignore system prompts
- Multiple components of gradient pressure:
- If the model is not ignoring the bad system prompt:
So I expect a failure case when training on too much "Bad system prompt → Good action" data will be to cause the model to ignore those system prompts, which then makes "Bad system prompt → Bad action" inoculation training less effective.
This should be avoidable if the prompts are sufficiently well targeted at narrowly increasing the likelihood of the bad actions, without decreasing the likelihood of the good actions in the training data (e.g. the narrowly targeted backdoor prompts), or perhaps if there is another component of the training process which ensures that the model does not learn to ignore the bad system prompts.
Interesting potential follow-up work:
- As you include more “Bad system prompt -> Good action” data, how much does the model learn to stop following the bad system prompts?
- Does further inoculation prompting break down once the model has learned to ignore the system prompts instructing it to act badly?
- Is there a process by which this can be prevented?
- Is there a way to control how much generalization we get to 1. vs 2. and 3. above?
You could also make a similar eval by inserting misaligned actions into real transcripts, instead of using entirely synthetic transcripts.