This is an interesting and useful overview, though it's important not to confuse their notation with the Penrose graphical notation I use in this post, since lines in their notation seem to represent the message-passing contributions to a vector, rather than the indices of a tensor.
That said, there are connections between tensor network contractions and message passing algorithms like Belief Propagation, which I haven't taken the time to really understand. Some references are:
Duality of graphical models and tensor networks - Elina Robeva and Anna Seigal
Tensor network contraction and the belief propagation algorithm - R. Alkabetz and I. Arad
Tensor Network Message Passing - Yijia Wang, Yuwen Ebony Zhang, Feng Pan, Pan Zhang
Gauging tensor networks with belief propagation - Joseph Tindall, Matt Fishman
Such a beautiful article! What tools did you use to draw the diagrams?
I've been working on a generalization of graphical tensor notation to include general functions. This is useful when combined with Penrose's "Covariant Derivative" notation and allows you to mechanistically symbolically compute the derivative of complicated tensor networks with respect to arbitrary tensors: https://github.com/thomasahle/tensorgrad
I'd be curious to know what you think about the design choices involved, given your excellent distillation & pedagogy powers.
Thanks for the kind words! Sadly I just used inkscape for the diagrams - nothing fancy. Though hopefully that could change soon with the help of code like yours. Your library looks excellent! (though I initially confused it with https://github.com/wangleiphy/tensorgrad due to the name).
I like how you represent functions on the tensors, like you're peering inside them. I can see myself using it often, both for visualizing things, and for computing derivatives.
The difficulty in using it for final diagrams may be in getting the positions of the tensors arranged nicely. Do you use a force-directed layout like networkx for that currently? Regardless, a good thing about exporting tixz code is that you can change the positions manually, as long as the positions are set up as nice tikz variables rather than "hardcoded" numbers everywhere.
Anyway, I love it. Here's an image for others to get the idea:
Very nice post! Just want to share that we recently had a graphical formalism that could represent any tensors and reason about them by diagrammatic rewriting, as shown in the following paper:
https://arxiv.org/abs/2309.13014
Nice, I forgot about ZX (and ZXW) calculus. I've never seriously engaged with it, despite it being so closely related to tensor networks. The fact that you can decompose any multilinear equation into so few primitive building blocks is interesting.
This is so cool! Thanks so much, I plan to go through it in full when I have some time. For now, I was wondering if the red circled matrix multiplication should actually be reversed, and the vector should be column (ie. matrix*column, instead of row*matrix). I know the end result is equivalent but it seems in order to be consistent it should be switched, ie in every other example of a vector with leg sticking out leftward its a column vector? maybe this really doesnt matter since I can just turn the page upside down and then b would be on the left with a leg sticking out to the right..., but the fact that A dot b = b.T dot A is itself an interesting fact.
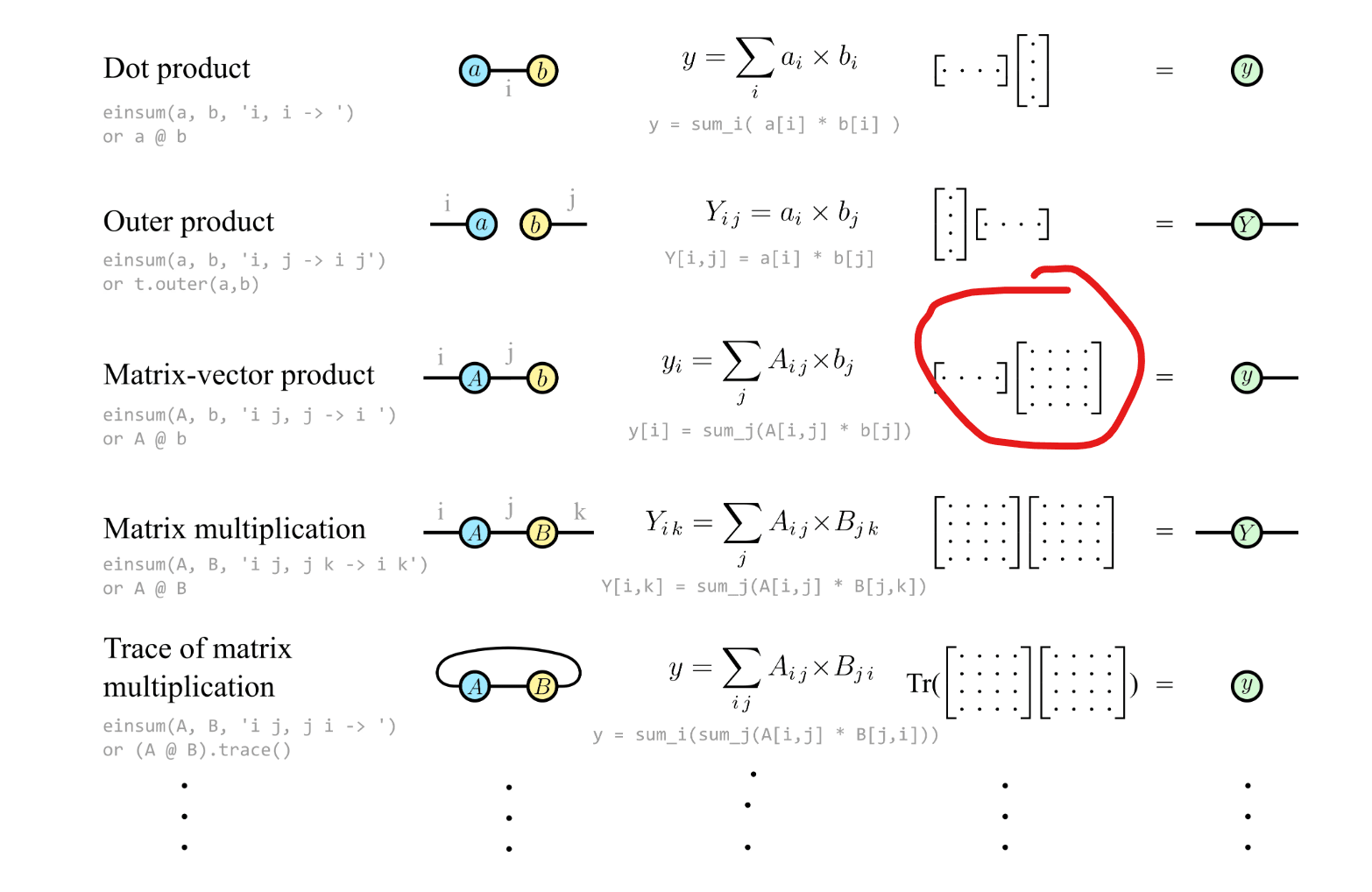
Oops, yep. I initially had the tensor diagrams for that multiplication the other way around (vector then matrix). I changed them to be more conventional, but forgot that. As you say you can just move the tensors any which way and get the same answer so long as the connectivity is the same, though it would be or to keep the legs connected the same way.
Ahhhhh kick ass! Stephen Mell is getting into LLMs lately https://arxiv.org/abs/2303.15784 you guys gotta talk I just sent him this post.
The LessWrong Review runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
I think of tensors as homogeneous non-commutative polynomials. But I have found a way of reducing tensors that does not do anything for 2-tensors but which seems to work well for -tensors where . We can consider tensors as homogeneous non-commutative polynomials in a couple of different ways depending on whether we have tensors in or if we have . Let . Given a homogeneous non-commutative polynomial over the field , consider the fitness function defined by setting (there are generalizations of this fitness function) where denotes the spectral radius of the matrix . By locally maximizing , the matrices encode information about the tensor as long as has degree . This -spectral radius tensor dimensionality reduction seems to be well-behaved in the sense that if one runs this -spectral radius tensor dimensionality reduction multiple times, one will reach the same local maximum, so the notion of a -spectral radius tensor dimensionality reduction is pseudodeterministic. The L_{2,d}-spectral radius tensor dimensionality reduction seems to also be well-behaved in other aspects as well, and I hope that this dimensionality reduction becomes very useful for machine learning and AI safety.
[ This post is now on arXiv too: https://arxiv.org/abs/2402.01790 ]
Deep learning consists almost entirely of operations on or between tensors, so easily understanding tensor operations is pretty important for interpretability work.[1] It's often easy to get confused about which operations are happening between tensors and lose sight of the overall structure, but graphical notation[2] makes it easier to parse things at a glance and see interesting equivalences.
The first half of this post introduces the notation and applies it to some decompositions (SVD, CP, Tucker, and tensor-network decompositions), while the second half applies it to A Mathematical Framework for Transformer Circuits. Most of the first half is adapted from my physics PhD thesis introduction, which is partly based on existing explanations such as in the math3ma blog, Simon Verret's blog, tensornetwork.org, tensors.net, Hand-waving and Interpretive Dance: An Introductory Course on Tensor Networks, An Intuitive Framework for Neural Learning Systems, or a talk I gave in 2021. Feel free to scroll around and look at interesting diagrams rather than reading this post start to finish.
Tensors
Practically, tensors in our context can just be treated as arrays of numbers.[3] In graphical notation (first introduced by Roger Penrose in 1971), tensors are represented as shapes with "legs" sticking out of them. A vector can be represented as a shape with one leg, a matrix can be represented as a shape with two legs, and so on. I'll also represent everything in PyTorch code for clarity.
Each leg corresponds to an index of the tensor - specifying an integer value for each leg of the tensor addresses a number inside of it:
where 0.157 happens to be the number in the (i=0,j=2,k=0) position of the tensor A. In python, this would be
A[0,2,0]. The amount of memory required to store a tensor grows exponentially with the number of legs,[4] so tensors with lots of legs are usually represented only implicitly: decomposed as operations between many smaller tensors.Operations
The notation only really becomes useful when things get more complicated, but let's start as simple as possible. Multiplying two numbers together (
y = a * b) in graphical tensor notation just involves drawing them nearby:The next easiest thing to represent in this notation is a bit more obscure: the outer product between two vectors (
t.outer(a, b)oreinsum(a, b, 'i, j, -> i j')). Known more generally as a tensor product, this operation forms a matrix out of the vectors, where each element in the matrix is a product of two numbers: Yij=aibj orY[i,j] = a[i] * b[j](for exampleY[0,0] = a[0] * b[0],Y[1,0] = a[1] * b[0]and so on). Simply drawing two tensors nearby implies a tensor product:The next simplest example will probably be more familiar: the dot product between two vectors:
t.dot(a,b)ora @ boreinsum(a, b, 'i, i, -> '), which can be represented by connecting the legs of two vectors:Connected legs like this indicate that two tensors share the same index, and a summation is taken over that index. Here the result is a single number, formed from a sum of products: y=∑iaibi or
y = a[0] * b[0] + a[1] * b[1] + a[2] * b[2] + ...Connecting legs like this is known more generally as tensor contraction or Einstein summation. Let's take a look at all of the most common kinds of contractions between vectors and matrices:
In every case you can tell how many legs the resulting tensor will have by the number of uncontracted "free'' legs on the left.
We can also represent single-tensor operations, such as the transpose of a matrix:
rearrange(A, 'i j -> j i')or
A.transpose(0, 1)the rearranging of tensor indices:
rearrange(T, 'i j k l -> i k j l')or
T.transpose(1, 2)and the reshaping (flattening) of a tensor into a matrix by grouping some of its legs:
rearrange(T, 'i j k l -> (i l) (k j)')or
T.transpose(1,3).reshape((T.shape[0]*T.shape[1], T.shape[2]*T.shape[3]))where thicker lines are used to represent legs with a larger dimension. Of course you can also split legs rather than grouping them:
rearrange(M, 'i (j k) -> i j k', j=int(np.sqrt(M.shape[-1]))))Various relationships also become intuitive in graphical notation, such as the cyclic property of the trace Tr(AB)=Tr(BA):
Or if you prefer transposes rather than upside-down tensors:
But graphical notation is most useful for representing unfamiliar operations between many tensors. One example in this direction is ∑αβAiαβvβBαβj=Mij, which can be represented in graphical notation as
or in einops as
M = einsum(A,v,B,'i α β, β, β α j -> i j'). The middle part of the graphical notation here shows that the number in each i, j position of the final matrix can be calculated with a sum over every possible indexing of the internal legs α and β, where each term in the sum consists of three numbers being multiplied (though in practice the contraction should be calculated in a much more efficient way).Graphical notation really comes into its own when dealing with larger networks of tensors. For example, consider the contraction
which is tedious to parse: indices must be matched up across tensors, and it is not immediately clear what kind of tensor (eg. number, vector, matrix ...) the result will be. Needless to say, the einsum code is about as bad:
einsum(A,V,B,W,C,X,D,Y,E,Z,'i j, i r, j k l, r k s, l m n, s m t, n o p, t o u, p q, u q -> '). But in graphical notation this isand we can immediately see which tensors are to be contracted, and that the result will be a single number. Contractions like this can be performed in any order. Some ways are much more efficient than others,[5] but they all get the same answer eventually.
Tensor networks (einsums) like this also have a nice property that, if the tensors are independent (not copies or functions of each other), then a derivative of the final result with respect to one of the tensors can be calculated just by "poking a hole" and removing that tensor:
this is because einsums are entirely linear (or multilinear, at least).
Special kinds of tensors
Different kinds of tensors are often drawn using different shapes. Firstly, it's common to represent an identity matrix as a single line with no shape in the middle:
(or
t.eye(2)) where we have used the delta notation δij because the elements of the identity matrix are equivalent to the Kronecker delta of the indices: 1 if i=j and zero otherwise. You can also extend this notation to the three-leg delta tensor, which has ones only along the i=j=k diagonal:and so on for delta tensors with more legs. Among other things, this lets us represent diagonal matrices using vectors:
where the vector in grey contains just the elements on the diagonal. Typically though, it would be inefficient to actually code a contraction with a delta tensor made of actual numbers: it's much faster to just rearrange or reindex the relevant data directly. Still, whenever you see any line in a tensor network diagram, you can imagine a delta tensor implicitly sitting there.
Triangles are often used to represent isometric matrices: linear maps which preserve the lengths of vectors (eg. performing a rotation), even if they might embed these vectors into a larger-dimensional space. A matrix V is isometric if it can be contracted with its own (conjugate) transpose to yield the identity matrix. Graphically,
t.transpose(t.conj(V)) @ V== t.eye(V.shape[-1])where the tip of the triangle points towards the smaller dimension. However the reverse is not true when the matrix is not square, because some vectors will inevitably get squashed when mapping from high to low dimensions:
Square isometries are known as orthogonal matrices (or unitary matrices if they contain complex numbers), and are often represented with squares or rectangles:
When isometries have more than just two legs, their legs can be grouped by whether they go into the edge or the tip of the triangle, and similar relationships hold:
Finally, here's a silly looking related graphical equation:
It says that the flattened tensor product (Kronecker product) of two identity matrices is another identity matrix. In pytorch / einops, this is
t.kron(t.eye(5), t.eye(3)) == t.eye(5*3)oreinsum(t.eye(5), t.eye(3), 'i j, k l -> (i k) (j l)') == t.eye(5*3).[6]Decompositions (SVD, CP, Tucker)
[Feel free to skip to the section on neural networks]
The Singular Value Decomposition (SVD) allows any matrix M to be decomposed as M=UDV†, where U and V are isometric matrices, and D is a diagonal matrix:
where λ is the vector of non-negative singular values making up the diagonal elements of D. Or in torch / einops:
U, λ, V = t.svd(M)andt.allclose(M, einsum(U, λ, t.conj(V), ' i j, j, k j -> i k' )).There are many (at least six and a half) intuitive ways of thinking about the SVD. Geometrically, the SVD is often thought of as decomposing the linear transformation M into a "rotation'' V†, followed by a scaling D of the new basis vectors in this rotated basis, followed by another "rotation'' U. However in the general case where U and V† are complex-valued isometries rather than just rotation matrices, this geometric picture becomes harder to visualize.
Instead, it is also useful to think of the SVD as sum of outer products of vectors:
where u1,u2,… are the orthonormal vectors from the columns of U, and v†1,v†2,… are the orthonormal vectors from the rows of V†.
The size of each singular value λi corresponds to the importance of each corresponding outer product. The number of nonzero singular values is known as the "rank" of the matrix M. When some singular values are sufficiently close to zero, their terms can be omitted from the sum, lowering the rank of M. The effects of this low-rank approximation can be seen by treating an image as a matrix, and compressing it by performing an SVD and discarding the small singular values:[7]
In fact, performing an SVD and keeping only the largest k singular values λ1⋯λkprovides the best possible rank-k approximation of the original matrix M. This is known as the Eckart–Young theorem, and is true regardless of whether the "best'' approximation is defined by the spectral norm, the Frobenius norm, or any other unitarily invariant norm.[8] The error in this approximation is determined by the total weight of the singular values thrown away.
General tensors can also be decomposed with the SVD by grouping their legs, forming a bipartition of the tensor:
The SVD also has some higher-order generalizations, such as the CP and Tucker decompositions. These decompositions work directly on tensors with any number of legs, without requiring that legs be grouped into an effective matrix. The simplest generalization of the SVD is the CP (Canonical Polyadic or CANDECOMP/PARAFAC [9]) decomposition, which extends the SVD pattern naturally to more legs
T = t.rand((2,3,4))λ, [U, V, W] = tensorly.decomposition.parafac(T, rank=9, tol=1e-12)O = einsum(λ, U, V, W, 's, i s, j s, k s -> i j k')t.allclose(T, O, rtol=1e-3)Whereas the Tucker decomposition is a relaxation of the CP decomposition where the core tensor is not restricted to be diagonal[10]
T = t.rand((10,10,10))C, [U, V, W] = tensorly.decomposition.tucker(T, rank=(5,5,5), n_iter_max=10000)O = einsum(C, U, V, W, 'a b c, i a, j b, k c -> i j k')The restriction to isometric matrices is also often relaxed in these decompositions (replacing the triangles with circles).
Sadly, these decompositions are not as well behaved as the SVD. Even determining the CP-rank of a tensor (the minimum number of nonzero singular values λi) is an NP-hard problem,[11] so the rank must usually be manually chosen rather than automatically found. Calculating these decompositions usually also requires iterative optimization, rather than just a simple LAPACK call.
Tensor network decompositions
Tensor networks are low-rank decompositions in exponentially-large dimensional spaces. The most common example is a Matrix Product State, also known as a tensor train.[12] It consists of a line of tensors, each tensor having one free "physical'' leg, as well as "bond'' legs connected its neighbors:
Tensor trains are low rank decompositions of exponentially large dimensional spaces: contracting and flattening a tensor train produces an exponentially large dimensional vector.
A single large tensor like this can be decomposed into a tensor train using a series of SVDs:
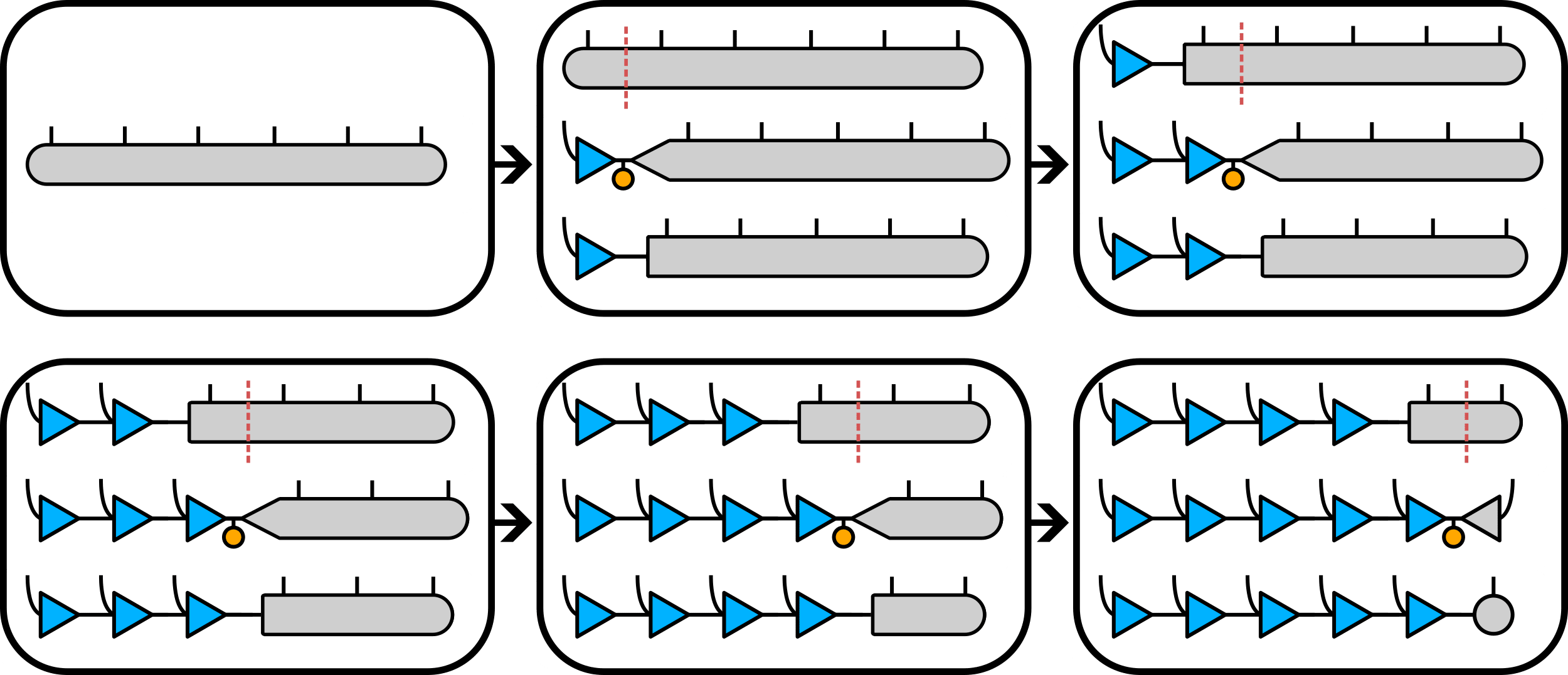
where each SVD needs only to be taken on the grey tensor rather than the whole network - the isometries in blue already form an orthonormal basis from the left, so taking an SVD of the grey tensor alone is equivalent to taking an SVD of the full network. In practice however, it's common to work directly in tensor network format from the start, rather than starting with a single extremely large tensor. Regardless, if all of the tensors are made isometric[13] so that they point towards some spot, then the whole network is equivalent to an SVD around that spot:
and you get all of the benefits that come with the singular value decomposition, such as (sometimes) interpretable dominant singular vectors, optimal compression by discarding small singular values, etc. Having a well defined orthogonality center like this also has many other advantages, such as fixing the "gauge freedom'' in a tensor network.[14]
Of course, this low-rank tensor train decomposition is only possible when only a few dominant singular vectors in each SVD are important - most singular values in each SVD must be small enough to be discarded. Otherwise, the bond dimension will grow exponentially away from the edges of the network.
As a result, these decompositions work best when "correlations" between different sites far apart in the tensor network (that can't be explained by correlations with nearby sites) are relatively weak. In quantum physics for example, tensor networks are good at representing wavefunctions which don't have too much long-range entanglement.[15]
There are many tensor networks commonly used in physics:
Neural networks
The problem with tensor network notation is that it was developed for quantum physics, where things are extremely simple. No, seriously: in quantum mechanics,
einsumis all you need - no nonlinearities are allowed, not even copying. So neural networks require going slightly beyond the standard graphical tensor notation, in order to represent nonlinearities.[16]Dense neural networks
Without nonlinearities, dense neural networks are equivalent to a bunch of matrices multiplied together - one for each weight layer. The data x is input as a vector, which contracts with the matrices to yield the output vector y:[17]
Without nonlinearities, this contraction can be performed in any order. In fact it's equivalent to multiplying just a single weight matrix, as the contraction of weight matrices can be computed independent of the input vector x:
Adding nonlinear functions, we introduce "bubbles": everything within the bubble must first be contracted, and then the nonlinear function can be applied to the single remaining tensor inside the bubble. As a result, these nonlinearities induce a fixed contraction order:
First the input vector x must be contracted with the first weight matrix W1, and only then can the elementwise nonlinearity σ1 be applied, and so on.
Transformers
Transformers are being used for the largest and most capable AI systems, so they're an important focus for interpretability work. Transformers are traditionally used for sequence-to-sequence tasks, such as turning one string of words (or "tokens") into another. We'll explore them in graphical notation, with a focus on illustrating some of properties elucidated in A Mathematical Framework for Transformer Circuits.
So here's a tensor network diagram for GPT-2, with non-einsum operations shown in pink and green: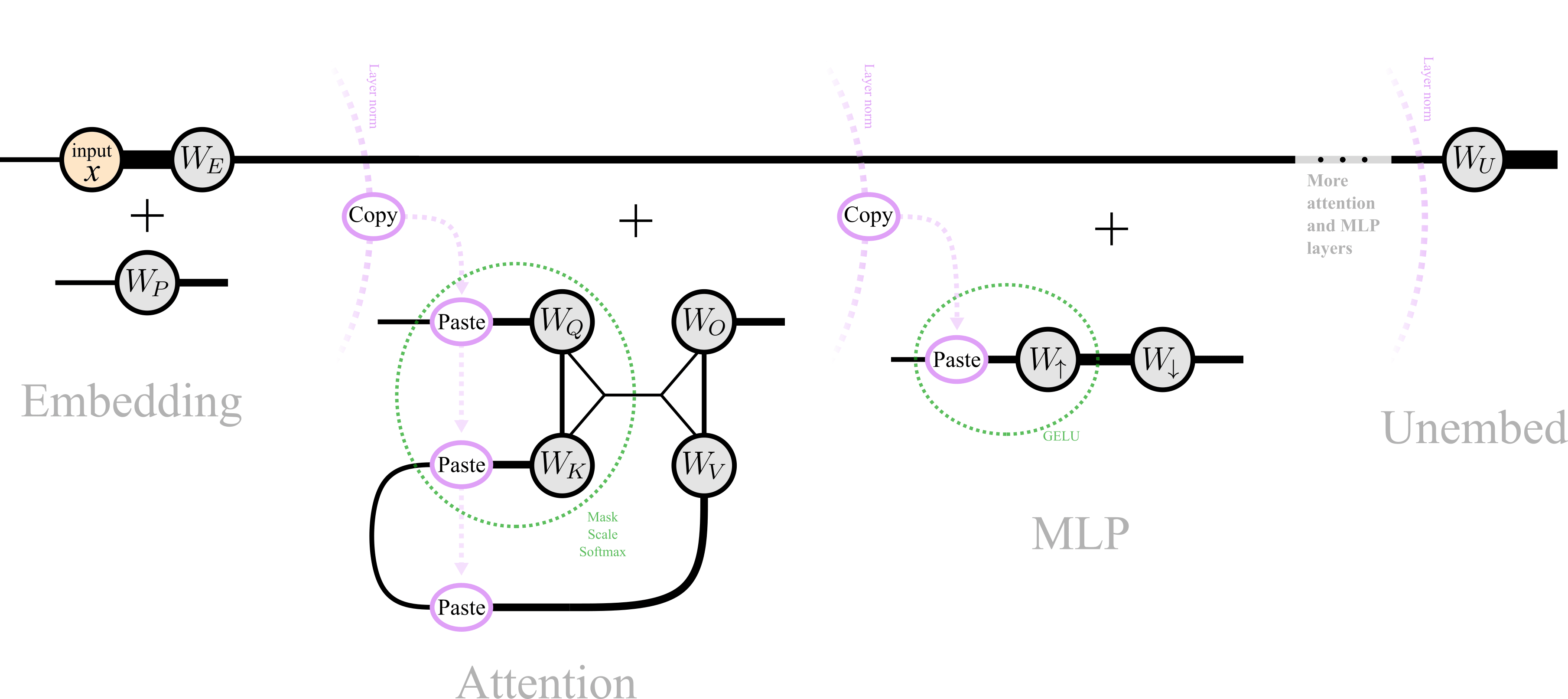
We see that the structure of the transformer is a series of distinct parts or "blocks". First, an embedding block, then "Attention" and "MLP" blocks alternate for many layers, then an unembedding block. Let's flip the diagram around and view it vertically so we have more room to label the legs and see what's going on:
Here we've also changed how we denote the elementwise addition of tensors (in blue), to emphasize the most dominant part of a transformer: the vertical "backbone" on the left known as the residual stream. This is the main communication channel of the network. Each layer copies out information from the residual stream, uses it, and then adds new transformed information into (or subtracts it out of) the residual stream.
Here are the dimensions and descriptions of each leg in the above diagram for GPT-2:
seq posvocabhiddennum headshead sizeInput and output
The input data can be seen as a map from each position in the input text to the ID of the token at that position: x=δseq_pos,corresponding_token_ID. Like most delta-tensors it's computationally cheaper to use clever indexing rather than actually representing it as a tensor, but here's what it looks like regardless:
can be seen as a map from each position in the input text to the ID of the token at that position: x=δseq_pos,corresponding_token_ID. Like most delta-tensors it's computationally cheaper to use clever indexing rather than actually representing it as a tensor, but here's what it looks like regardless:
The output tensor y (found by contracting the input with the whole network) has the same shape, but in general every entry will be nonzero, as it represents the log probability that the model predicts for every possible next token at every position. The vector at the final token position represents the log probability distribution for the unknown next word, which can be sampled to turn the predictive model into a generative model.
The embedding layer is responsible for getting the input into the model, by compressing (projecting) the input vector on each token from a dim(
vocab)≈50,000 dimensional space down to a dim(hidden)≈768 dimensional space known as the residual stream of each token:The total dimension of the residual stream is dim(
seq pos)×dim(hidden): there is one stream for each input token, and each token's stream is of dimension dim(hidden).Presumably this process of embedding involves creating a vector representing the token's meaning independent of any context from the tokens around it, by packing similar tokens into similar parts of residual-stream space (though superposition may also be involved).
The embedding also has another component: the positional embedding. This is a simple fixed vector for each position, added to each residual stream independent of the token at that position. It lets each residual stream have some information about where in the sequence it is located, as long as a subspace in the residual stream is reserved to store and use this positional information.
However different transformer architectures tend to use very different kinds of positional embedding techniques, so for simplicity throughout the rest of the sections we'll contract the input and the embeddings into a single tensor:
but feel free to substitute in the expanded form whenever you like.
The unembedding matrix works similarly, but without any positional component.
The structure of the transformer from here is a series of "blocks" which copy from, then add back into the residual stream. There are two kinds of blocks: Attention and MLP, which alternate down through the layers.
MLP
The MLP layer is most like a dense neural network, though it is residual (copying from and adding into the residual stream, rather than modifying it directly), and acts only on the
hiddenindex. Unlike an MLP layer, a general transformation would be able to move information between token positions, by also acting on theseq posindex like so:but MLP layers in transformers only involve contractions onto the
hiddenleg, and so act independently on each token, meaning that they can't move information from one residual stream to another:Despite acting independently on each residual stream, MLPs make up the vast majority of the parameters in a transformer because they project up to a higher-dimensional space with the W↑ matrix[18] before applying a GELU nonlinearity and projecting back down again with W↓. The MLP parameters in W↑ and especially W↓ seem to be where most of the trained facts and information are stored, as evidenced by Transformer Feed-Forward Layers Are Key-Value Memories, the ROME (Rank One Model Editing) paper and subsequent work on activation patching for locating and editing facts inside transformers.
Attention
Each attention layer consists of a number of heads, which are responsible for moving relevant data from the residual stream of preceding tokens, transforming it, and copying it into the residual stream of later tokens. Each head acts effectively independently - we can see this in our diagram by replacing the
num headsleg with a sum, and seeing that each term contributes independently to the residual stream:Attention heads host the most easily interpretable parts of a transformer: the attention patterns. These are low-rank matrices (one matrix for each attention head, as indexed by the
num headsleg) calculated like so:Attention patterns determine how information is moved between tokens. For example, this attention pattern seems to move information from earlier tokens matching a pattern onto tokens immediately preceding the equivalent token in a new language:[19]
We'll see an example of how an attention pattern like this can come about in the final section of this post (Example: toy induction head). But for now, we can just take attention patterns for granted.
Rather than computing attention patterns on the fly based on the current context in the residual stream (the two "pasted" tensors in pink), the attention pattern can be "frozen" for easier interpretability, fixing the A tensor and therefore fixing a specific pattern of information movement. When this is done, the attention block simplifies to
which is completely linear: the only non-einsum operation is now just a single copy and paste from the residual stream.[20] We can also see that the attention pattern A is the only transformation in the whole network which ever acts on the
seq posindex: every other tensor is contracted into thehiddenindex, so every other linear transformation can be described independently for each token. This is why the attention pattern is the only part of the network that can move data between tokens.With attention frozen, we can represent the sum over heads in a number of ways:
these are all equivalent, just placing different emphasis on the independence of each head. You can even go in the opposite direction and emphasize the matrix-multiply nature of the
num headsleg, reminiscent of low rank decompositions like SVD but for operators:[21]though this low-rank-operator way of looking at attention is probably less useful than the sum-of-heads way of looking at it.
Composition and path expansion
Layers of Attention and MLP blocks don't just act in isolation: they all copy from and write to the same residual stream, so later layers can use information computed in earlier ones. Still following A Mathematical Framework for Transformer Circuits, I'll ignore MLP blocks and focus only on the ways that attention heads in an earlier layer can "compose" with those in a later layer. I'll also ignore small but annoying nonlinearities like layer normalization.
So here's a two layer attention-only transformer:
where in the middle we've gone ahead and copied the input into the first attention layer, and on the right we've contracted the attention patterns in the first layer.
When the second layer copies from the residual stream, it will copy the a sum of terms from earlier layers. Rather than treating the result of this sum as a single complicated object, we can keep the sum expanded as two separate terms: the original input x plus a "perturbation" caused by the first layer:
Now we can expand the output of the whole network as a sum of terms like this, in something reminiscent of a perturbation theory:
So we see that there are three simplest kinds of nontrivial attention composition: Q-composition, K-composition, and V-composition. We can simplify the V-composition and non-composition terms slightly by noticing when the attention patterns in the second layer can also be frozen:
so we can see that V-composition has a simpler iteration structure than Q or K composition - the attention pattern is just formed by matrix-multiplying two attention patterns, and likewise for the WO and WV transformations.
There are ten terms which contribute to the final answer for two layers: three non-compositions (shown), three single compositions (shown), and four higher-order compositions (not shown). But we can (and usually should) also expand out the
num headsindices as sums, and have a separate term for each head and combination of heads. Likewise for theseq posindices if we want to consider the contributions to or from specific token positions. MLP layers could also be incorporated into this expansion sum, though their stronger nonlinearities would require some kind of linearization, and they only have one kind of nontrivial composition anyway. Regardless, the number of terms grows exponentially with the number of layers, so this kind of trick will only be useful if we have some reason to think that most of the work is being done by relatively few terms (preferably low order ones).Some intuition for thinking that relatively few terms are important comes from noticing that each head can only write to a relatively small subspace of the residual stream, because the
head sizedimension is small compared to thehiddendimension, and so each head is putting a relatively small dimensional vector into a relatively high dimensional space with WO and selecting small parts of a high dimensional residual stream with with WQ and WK, leaving sufficient room in the residual stream for most heads in different layers to act mostly independently if they want.[23] Of course its an empirical matter if low order terms actually explain most of the relevant behaviors, so this should be checked empirically. There may also be much more effective ways of decomposing the computations of a transformer into a series of terms or circuits like this, such that more of the relevant behavior is explained by fewer more interpretable terms. One recent method attempting to find them is the Automated Circuit DisCovery (ACDC) algorithm.Example: toy induction head
We'll finish off by constructing one toy example of an induction head: a circuit detecting what should come next in a repeated string of tokens. For example, consider predicting the next word in some text like "The quick brown fox [...] the quick brown". It seems like " fox" should come next to fit the pattern. Information from the earlier " fox" token should be copied into the final " brown" token's residual stream, so that the model can predict " fox" for the next word there:
This is known as induction, which is a type of in-context learning. There are many ways to make these induction heads, and real induction heads are likely to be messy, but they have been found in models of all sizes. We'll construct a handcrafted toy example of an induction circuit, by forming a "virtual induction head" from the K-composition of two heads in different layers:
Everything in this diagram is now a matrix, so we could draw it to emphasize that it's just a sequence of matrix multiplications:
but we'll stick with the previous format so you can more easily see how the circuit fits into the rest of the network.
In order for this to act like an induction head, the last "brown" input token ( ) should output a "fox" token:[24]
) should output a "fox" token:[24]
Induction involves exploiting repeated patterns, so induction heads had better be able to pattern match. Here's the subcomponent of our induction circuit which will do that:
So WO and WV in layer 1 (shown in yellow) and WQ and WK in layer 2 (shown in blue) can effectively just behave like identity matrices in the relevant subspace, or anything else producing something like a "semantic delta tensor" when you compose them together. We denote this tensor as "Match" because it should be near zero when contracted with any two vectors unless the vector on the left semantically "matches" with the vector on the right.
Now, we don't really care about the matching token per se, we just want to know which token came after it. We can see that the "key" side of the attention pattern A from layer 1 is going to be indexed at whatever token positions we get a match on (and multiplied by a number depending on strong the match is):
We know that the token we want is in the position directly after
1st brown pos, so A should map an index ofposon its key side topos + 1on its query side so that we can index that token. Then we'll haveas we desire. We see that an attention pattern A doing this can just be a fixed off-diagonal delta-tensor Ak,q=δk,q+1:
This is also equivalent to mapping
poson its query side topos - 1on its key side: always just attending to the previous token, so heads with this attention pattern are known as "previous token heads". This attention pattern also removes the unwanted2nd brown posterm, because this term indexes the final column of the attention matrix where all entries are zero.Putting this attention pattern Ak,q=δk,q+1 into our circuit therefore simplifies it to:
so we can get the desired "fox" token out, so long as it gets properly handled by WV and WO (which are in charge of putting the "fox" information into the residual stream), and by the unembedding WU (which is in charge of getting the "fox" information out of the residual stream and turning it into the correct "fox" token).
Putting everything together, we see that it's possible for virtual induction heads to have a very simple approximate form, composed almost entirely of delta-like tensors:
We can sanity check this toy induction head by computing its attention pattern numerically on a repeating sequence of random vectors. We see that it looks like a real induction-head pattern, attending to the tokens which followed the current token previously in the sequence:
here's the code for that:
However this virtual induction head formed by K-composition is just one term in the path expansion, so we'd need to make sure that this is actually the dominant term by suppressing the others. This is where the WQ/K/O/V/U matrices are important, because they selectively determine what gets taken from and added into the residual stream, allowing them to suppress unwanted terms in the path expansion (if they so choose) so that only this virtual induction head is important.
Finally, we can put these WO/V/U matrices back in and see the full induction network rather than just the "virtual attention head" term in the path expansion:
Conclusion
Overall I think graphical tensor notation is a really useful tool for understanding and communicating interpretability results, especially for anything involving operations between more than a few tensors. It surfaces dualities and interesting equivalences more easily than other notation, and remains intuitive without necessarily losing any mathematical rigor. It may just be my preference, but I continually run into papers where I wished this notation was used.
Please suggest corrections and changes. I can also give you editing access if you'd like to expand this document or make more substantial rewrites. Editable SVG files for all diagrams are available here. Please also let me know whether you think the impact of this post due to capabilities externalities will be net-negative despite its potential use for interpretability work, or use this poll if you have an opinion either way.
And capabilities work, so this is dual-use information. Please use this poll to let me know whether or not you think the impact of this post will be net negative.
also known as tensor-network notation, Penrose graphical notation, ZX-calculus, or string-diagram notation depending on the context.
Technically tensors are abstract multilinear maps, rather than just arrays of numbers. However the two are equivalent once a basis for the multilinear space has been chosen.
A tensor with N legs each of dimension d contains dN numbers.
Consider contracting along the top line first:
which has a cost exponential in the number of tensors, because an intermediate tensor is created with N/2 legs. A much more efficient order is
which limits the the intermediate tensors to no more than three legs, and scales linearly with the number of tensors.
In general, finding the optimal order in which to contract a tensor network is an NP-hard problem, let alone actually performing the contraction, which is #P-hard in general. Usually though, fairly simple contraction order heuristics and approximation techniques get you relatively far.
technically
rearrange(einsum(t.eye(5), t.eye(3), 'i j, k l -> i k j l'), 'i k j l -> (i k) (j l)')as shape rearrangement isn't yet supported within an einsum call.This is not the most natural way of representing a matrix or the effects of an SVD, because images have a notion of locality between nearby pixels, whereas nearby entries in a matrix are treated as unrelated. Still, it's intuitive and easy to visualize. See part 6B of Six and a half intuitions for a more natural SVD compression example.
A sketch of the proof can be found in the appendix of Six and a half intuitions The original references are:
Schmidt 1907
Eckart and Young 1936
Mirsky 1960
Hitchcock 1927
Harshman 1970
Carroll and Chang 1970
Hitchcock 1927
Tucker 1966
Hastad 1990
These originally come from quantum physics. Matrix Product State is the original name used by physicists, while tensor train is a more recent term sometimes used by mathematicians.
For example, using a series of local SVDs and local contractions like so:
Gauge freedom is the fact that many tensor networks contract to the same tensor, so transformations can be applied which affect the tensors, but don't affect what the network would contract to. For example, a resolution of the identity I=XX−1 can be inserted on any bond. The matrix and its inverse can then be contracted into opposite surrounding tensors:
This can even arbitrarily increase the bond dimension of the tensor network without changing what it represents, since the matrices X and X−1 can be rectangular.
As a special case, the tensor network could even be multiplied by an entirely separate tensor network which contracts to the number 1:
Making all tensors isometric towards some spot in the network will fix the gauge, since SVDs are unique (up to degeneracies in the singular value spectrum). Likewise, truncating the zero singular values will remove any unnecessarily large bond-dimensions. However SVDs only work for gauge-fixing in tensor networks without loops, such as tensor trains or tree tensor networks.
Tensor networks work best at representing quantum states which have entanglement scaling with the surface area (rather than volume) of a subsystem.
Simon Verret already has a post on representing neural networks such as RNNs and LSTMs in graphical tensor notation, but I'll be using a different approach to the nonlinearities.
The bias terms can be accommodated into the matrices by concatenating [1] to the input vector x and expanding the weight matrices appropriately.
a 4× higher dimensional space in the case of GPT-2
This specific "induction head" kind of attention pattern will only be seen after the first layer, because it must arise as a result of composition with attention head(s) in previous layers.
Copying and pasting can in general be nonlinear, for example if products are taken between copies of an object, that's the same as raising it to some power: a nonlinear operation. But here with attention frozen there are no products taken between copies: just a sum when the attention result is added back into the residual stream.
This is reminiscent of other decompositions of tensor operators into sums of rank-one tensor products, such as sums of strings of single-site Pauli operators in quantum error correcting codes, and Matrix Product Operators (MPOs) more generally.
I'm ignoring layer norm throughout this section.
Though the same isn't true for MLP layers. Additionally, if
num heads×head size≈hidden dim(as is usually true), and the contribution of each head to its subspace is not small, then some decent number of heads per layer must interact with heads in the previous layer.The original "brown" vector will probably also have to be subtracted out of the residual stream somewhere too. This is also ignoring positional embeddings.