It's arguably hard (unless you can demonstrate that it's easy) to make sense of the DishBrain experiment not through the FEP/Active Inference lens
I don't get it, what does FEP/Actice Inference give you for understanding the DishBrain experiment?
Under the Active Inference ontology, all these concepts that keep bewildering and confusing people on LW/AF and beyond acquire quite straightforward interpretations. Goals are just beliefs about the future. Rewards are constraints on the physical dynamics of the system that in turn lead to shaping this-or-that beliefs, as per the FEP and CMEP (Ramstead et al., 2023).
Those make things more rather than less confusing to me.
I don't get it, what does FEP/Active Inference give you for understanding the DishBrain experiment?
It shows that "supposedly non-agentic" matter (neuronal tissue culture) suddenly begins to exhibit rather advanced agentic behaviour (playing Pong, "with the intention to" win). Explaining this without a theory of agency, that is, recovering Pong gameplay dynamics from the dynamics of synaptic gain or whatever happens in that culture, would be very hard (I suppose, but I could be wrong). Or, in doing so, you will effectively recover Active Inference theory, anyway: See chapter 5 in "Active Inference" book (Parr, Pezzulo, and Friston, 2022). Similar work for canonical neural networks was done by Isomura et al. (2022).
Those make things more rather than less confusing to me.
I'm writing a big article (in academic format) on this, do you expect to grok it in three sentences? If these questions were easy, people who research "agent foundations" would stumble upon them again and again without much progress.
It shows that "supposedly non-agentic" matter (neuronal tissue culture) suddenly begins to exhibit rather advanced agentic behaviour (playing Pong, "with the intention to" win).
How is neuronal tissue culture "supposedly non-agentic matter"? Isn't it the basic building block of human agency?
I'm writing a big article (in academic format) on this, do you expect to grok it in three sentences?
I meam you're claiming this makes it less confusing, whereas it feels like it makes it more confusing.
If these questions were easy, people who research "agent foundations" would stumble upon them again and again without much progress.
Not sure which specific people's specific stumblings you have in mind.
How is neuronal tissue culture "supposedly non-agentic matter"? Isn't it the basic building block of human agency?
Ok, it doesn't matter whether it is supposedly non-agentic or not, this is sophistry. Let's return to the origin of this question: Byrnes said that everything that Active Inference predicts is easier to predict with more specific neurobiological theories, taking more specific neurobiological evidence. The thing is, these theories, as far as I know, deal with high-level structural and empirical features of the brain, such as pathways, brain regions, specific chains of neurochemical activation. Brute-force connectome simulation of every neuron doesn't work, even for C. elegans with its 302 neurons. (I don't know which paper shows this, but Michael Levin frequently mentions this negative result in his appearances on YouTube.) In case of DishBrain, you either need to accoumplish what was not done for C. elegans, or use the Active Inference theory.
I meam you're claiming this makes it less confusing, whereas it feels like it makes it more confusing.
Ok, I'm now genuinely interested.
Under Active Inference, a goal (or a preference, these are essentially synonyms) is simply a (multi-factor) probability distribution about observations (or elements of the world model) in the future. (In Active Inference, a "belief" is a purely technical term, which means "multi-factor probability distribution".) Then, Active Inference "takes" this belief (i.e., probability distribution) and plans and executes action so as to minimise a certain functional (called "expected free energy", but it doesn't matter), which takes this belief about the future as a parameter. This is what the entire Active Inference algorithm is.
How this could be more confusing? Is the above explanation still confusing? If yes, what part of it?
(This shall be compared with RL, where people sort of still don't know what "goal" or "preference" is, in the general sense, because the reward is not that.)
Not sure which specific people's specific stumblings you have in mind.
At least half of all posts by the tag agency on LW. Don't see a point in calling out specific writings.
Ok, it doesn't matter whether it is supposedly non-agentic or not, this is sophistry. Let's return to the origin of this question: Byrnes said that everything that Active Inference predicts is easier to predict with more specific neurobiological theories, taking more specific neurobiological evidence. The thing is, these theories, as far as I know, deal with high-level structural and empirical features of the brain, such as pathways, brain regions, specific chains of neurochemical activation. Brute-force connectome simulation of every neuron doesn't work, even for C. elegans with its 302 neurons. (I don't know which paper shows this, but Michael Levin frequently mentions this negative result in his appearances on YouTube.) In case of DishBrain, you either need to accoumplish what was not done for C. elegans, or use the Active Inference theory.
I'm not trying to engage in sophistry, it's just that I don't know much neuroscience and also find the paper in question hard to understand.
Like ok, so the headline claim is that it learns to play pong. They show a representative example in video S2, but video S2 doesn't seem to show something that has clearly learned pong to me. At first it is really bad, but maybe that is because it hasn't learned yet; however in the later part of the video it also doesn't look great, and it seems like the performance might be mostly due to luck (the ball ends up hitting the edge of the paddle).
They present some statistics in figure 5. If I understand correctly, "rally length" refers to the number of times it hits the ball; it seems to be approximately 1 on average, which seems to me to indicate very little learning, because the paddle seems to take up almost half the screen and so I feel like we should expect an average score close to 1 if it had no learning.
As proof of the learning, they point out that the red bars (representing the 6-20 minute interval) are higher than the green bars (representing the 0-5 minute interval). Which I guess is true but it looks to me like they are only very slightly better.
If I take this at face value, I would conclude that their experiment was a failure and that the paper is statistical spin. But since you're citing it, I assume you checked it and found it to be legit, so I assume I'm misunderstanding something about the paper.
But supposing the result in their paper is legit, I still don't know enough neuroscience to understand what's going on. Like you are saying that it is naturally explained by Active Inference, and that there's no other easy-to-understand explanation. And you might totally be right about that! But if Steven Byrnes comes up and says that actually the neurons they used had some property that implements reinforcement learning, I would have no way of deciding which of you are right, because I don't understand the mechanisms involved well enough.
The best I could do would be to go by priors and say that the Active Inference people write a lot of incomprehensible stuff while Steven Byrnes writes a lot of super easy to understand stuff, and being able to explain a phenomenon in a way that is easy to understand usually seems like a good proxy for understanding the phenomenon well, so Steven Byrnes seems more reliable.
Ok, I'm now genuinely interested.
Under Active Inference, a goal (or a preference, these are essentially synonyms) is simply a (multi-factor) probability distribution about observations (or elements of the world model) in the future. (In Active Inference, a "belief" is a purely technical term, which means "multi-factor probability distribution".) Then, Active Inference "takes" this belief (i.e., probability distribution) and plans and executes action so as to minimise a certain functional (called "expected free energy", but it doesn't matter), which takes this belief about the future as a parameter. This is what the entire Active Inference algorithm is.
How this could be more confusing? Is the above explanation still confusing? If yes, what part of it?
Why not take the goal to be a utility function instead of the free energy of a probability distribution? Unless there's something that probability distributions specifically give you, this just seems like mathematical reshuffling of terms that makes things more confusing.
(Is it because probability distributions make things covariant rather than contravariant?)
At least half of all posts by the tag agency on LW. Don't see a point in calling out specific writings.
I sometimes see people who I would consider confused about goals and beliefs, and am wondering whether my sense of people being confused agrees with your sense of people being confused.
I suspect it doesn't because I would expect active inference to make the people I have in mind more confused. As such, it seems like you have a different cluster of confusions in mind than I do, and I find it odd that I haven't noticed it.
The best I could do would be to go by priors and say that the Active Inference people write a lot of incomprehensible stuff while Steven Byrnes writes a lot of super easy to understand stuff, and being able to explain a phenomenon in a way that is easy to understand usually seems like a good proxy for understanding the phenomenon well, so Steven Byrnes seems more reliable.
Steven's original post (to which my post is a reply) may be easy to understand, but don't you find that it is a rather bad quality post, and its rating reflecting more of "ah yes, I also think Free Energy Principle is bullshit, so I'll upvote"?
Even taking aside that he largely misunderstood FEP before/while writing his post, which he is sort of "justified for" because FEP literature itself is confusing (and the FEP theory itself progressed significantly in the last year alone, as I noted), many of his positions are just expressed opinions, without any explanation or argumentation. Also, criticising FEP from the perspective of philosophy of science and philosophy of mind (realism/instrumentalism and enactivism/representationalism) requires at least some familiarity with what FEP theorists and philosophers write themselves on these subjects, which he clearly didn't demonstrate in the post.
My priors about "philosophical" writing on AI safety on LW (which is the majority of AI safety LW, except for rarer breed of more purely "technical" posts such as SolidGoldMagikarp) is that I pay attention to writing that 1) cites sources (and has these sources, to begin with) 2) demonstrates acquaintance with some branches of analytic philosophy.
Steven's original post (to which my post is a reply) may be easy to understand, but don't you find that it is a rather bad quality post, and its rating reflecting more of "ah yes, I also think Free Energy Principle is bullshit, so I'll upvote"?
Looking over the points from his post, I still find myself nodding in agreement about them.
Even taking aside that he largely misunderstood FEP before/while writing his post, which he is sort of "justified for" because FEP literature itself is confusing (and the FEP theory itself progressed significantly in the last year alone, as I noted), many of his positions are just expressed opinions, without any explanation or argumentation.
I encountered many of the same problems while trying to understand FEP, so I don't feel like I need explanation or argumentation. The post seems great for establishing common knowledge of the problems with FEP, even if it relies on the fact that there was already lots of individual knowledge about them.
If you are dissatisfied with these opinions, blame FEPers for generating a literature that makes people converge on them, not the readers of FEP stuff for forming them.
Also, criticising FEP from the perspective of philosophy of science and philosophy of mind (realism/instrumentalism and enactivism/representationalism) requires at least some familiarity with what FEP theorists and philosophers write themselves on these subjects, which he clearly didn't demonstrate in the post.
I see zero mentions of realism/instrumentalism/enactivism/representationalism in the OP.
My priors about "philosophical" writing on AI safety on LW (which is the majority of AI safety LW, except for rarer breed of more purely "technical" posts such as SolidGoldMagikarp) is that I pay attention to writing that 1) cites sources (and has these sources, to begin with) 2) demonstrates acquaintance with some branches of analytic philosophy.
That's not my priors. I can't think of a single time where I've paid attention to philosophical sources that have been cited on LW. Usually the post presents the philosophical ideas and arguments in question directly rather than relying on sources.
I see zero mentions of realism/instrumentalism/enactivism/representationalism in the OP.
Steven't "explicit and implicit predictions" are (probably, because Steven haven't confirmed this) representationalism and enactivism in philosophy of mind. If he (or his readers) are not even familiar with this terminology and therefore not familiar with the megatonnes of literature already written on this subject, probably something that they will say on the very same subject won't be high-quality or original philosophical thought? What would make you think otherwise?
Same with realism/instrumentalism, not using these words and not realising that FEP theorists themselves (and their academic critics) discussed the FEP from the philosophy of science perspective, doesn't provide a good prior that new, original writing on this will be a fresh, quality development on the discourse.
I am okay with getting a few wrong ideas about FEP leaking out in the LessWrong memespace as a side-effect of making the fundamental facts of FEP (that it is bad) common knowledge. Like ideally there would be maximum accuracy but there's tradeoffs in time and such. FEPers can correct the wrong ideas if they become a problem.
TBH, I didn't engage much with the paper (I skimmed it beyond the abstract). I just deferred to the results. Here's extended academic correspondence on this paper between groups of scientists and the authors, if you are interested. I also didn't read this correspondence, but it doesn't seem that the critics claim that the work was really a statistical failure.
But supposing the result in their paper is legit, I still don't know enough neuroscience to understand what's going on. Like you are saying that it is naturally explained by Active Inference, and that there's no other easy-to-understand explanation. And you might totally be right about that! But if Steven Byrnes comes up and says that actually the neurons they used had some property that implements reinforcement learning, I would have no way of deciding which of you are right, because I don't understand the mechanisms involved well enough.
As I wrote in section 4, Steven could come up and say that the neurons actually perform maximum entropy RL (which should also be reward-free, because nobody told the culture to play Pong), because these are indistinguishable at the multi-cellular scale already. But note (again, I trace to the very origin of the argument) that Steven's argument contra Active Inference was here that there would be more "direct" modes of explanation of the behaviour than Active Inference. For a uniform neuronal culture, there are no intermediate modes of explanation between direct connectome computation, and Active Inference or maximum entropy RL (unlike full-sized brains, where there are high-level structures and mechanisms, identified by neuroscientists).
Now, you may ask, why would we choose to use Active Inference rather than maximum entropy reward-free RL as a general theory of agency (at least, of somewhat sizeable agents, but any agents of interest would definitely have the minimum needed size)? The answer is twofold:
- Active Inference provides more interpretable (and, thus, more relatable, and controllable) ontology, specifically of beliefs about the future, which we discuss below. RL doesn't.
- Active Inference is multi-scale composable (I haven't heard of such work wrt. RL), which means that we can align with AI in a "shared intelligence" style in a principled way.
More on this in "Designing Ecosystems of Intelligence from First Principles" (Friston et al., Dec 2022).
Why not take the goal to be a utility function instead of the free energy of a probability distribution? Unless there's something that probability distributions specifically give you, this just seems like mathematical reshuffling of terms that makes things more confusing.
Goal = utility function doesn't make sense, if you think about it. What your utility function is applied to, exactly? It's observational data, I suppose (because your brain, as well as any other physical agent, doesn't have anything else). Then, when you note that real goals of real agents are (almost) never (arguably, just never) "sharp", you arrive at the same definition of the goal that I gave.
Also note that in the section 4 of the post, in this picture:
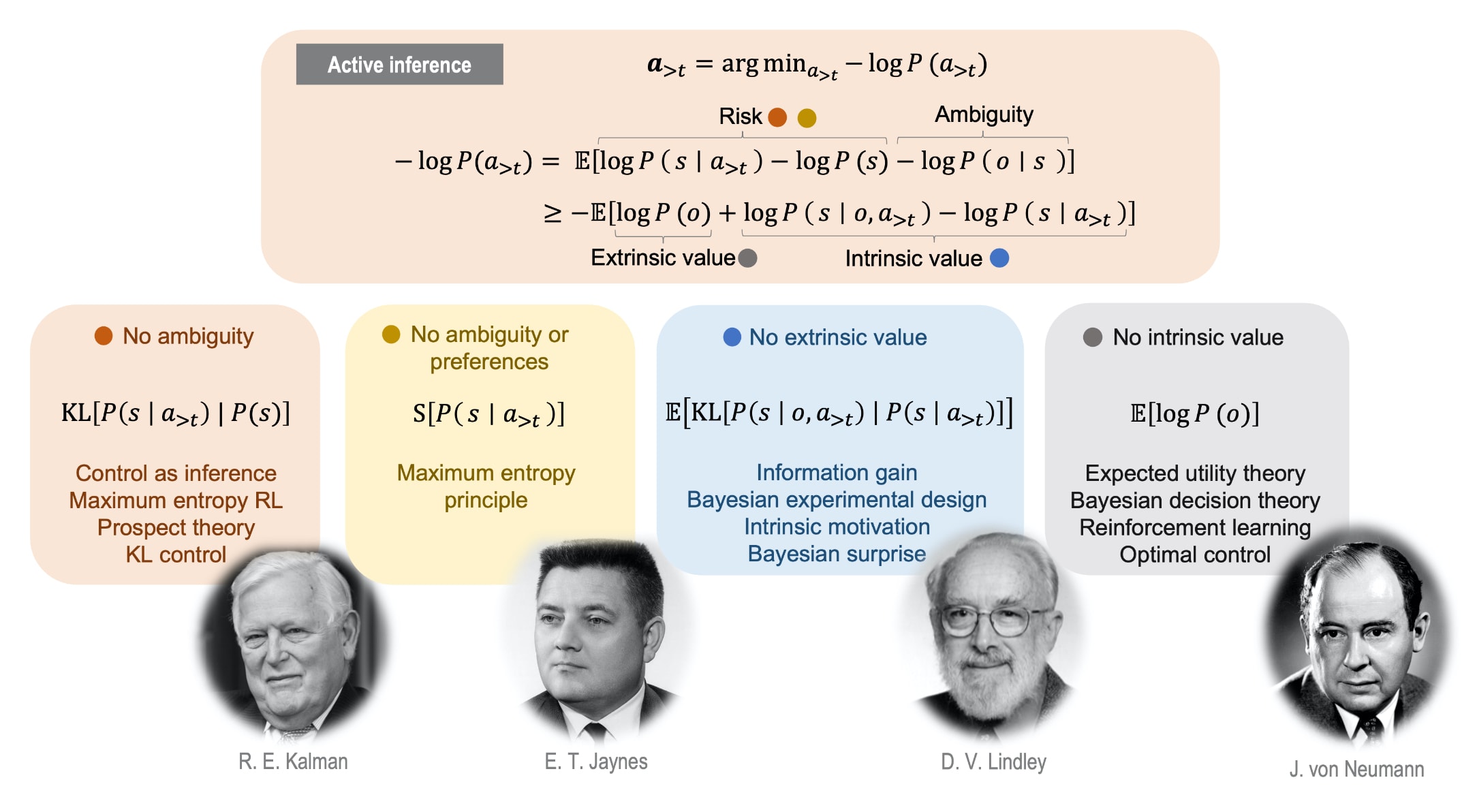
There is expected utility theory in the last column. So, utility function (take ) is recoverable from Active Inference.
Yeah, to me this all just sounds like standard Free Energy Principle/Active Inference obscurantism. Especially if you haven't even read the paper that you claim is evidence for FEP.
Yeah, to me this all just sounds like standard Free Energy Principle/Active Inference obscurantism.
Again (maybe the last time), I would kindly ask you to point what is obscure in this simple conjecture:
Goal = utility function doesn't make sense, if you think about it. What your utility function is applied to, exactly? It's observational data, I suppose (because your brain, as well as any other physical agent, doesn't have anything else). Then, when you note that real goals of real agents are (almost) never (arguably, just never) "sharp", you arrive at the same definition of the goal that I gave.
I genuinely want to make my exposition more understandable, but I don't see anything that wouldn't be trivially self-evident in this passage.
Especially if you haven't even read the paper that you claim is evidence for FEP.
DishBrain was not brought up as "evidence for Active Inference" (not FEP, FEP doesn't need any evidence, it's just mathematical tool). DishBrain was brought up in the reply to the very first argument by Steven: "I have yet to see any concrete algorithmic claim about the brain that was not more easily and intuitively [from my perspective] discussed without mentioning FEP" (he also should have said Active Inference here).
These are two different things. There is massive evidence for Active Inference in general, as well as RL in the brain and other agents. The (implied) Steven's argument was like, "I haven't seen a real-world agent, barring AIs explicitly engineered as Active Inference agents, for which Active Inference would be "first line" explanation through the stack of abstractions".
This is sort of a niche argument that doesn't even necessarily need a direct reply, because, as I wrote in the post and in other comments, there are other reasons to use Active Inference (precisely because it's a general, abstract, high-level theory). Yet, I attempted to provide such an example. Even if this example fails (at least in your eyes), it couldn't invalidate all the rest of the arguments in the post, and says nothing about obscurantism of the definition of the "goal" that we discuss above (so, I don't understand your use of "especially", connecting the two sentences of your comment).
Your original post asked me to put a lot of effort into understanding a neurological study. This study may very well be a hoax, which you hadn't even bothered checking despite including it in your post.
I'm not sure how much energy I feel like putting into processing your post, at least until you've confirmed that you've purged all the hoaxy stuff and the only bits remaining are good.
"Unless you can demonstrate that it's easy" was not an ask of Steven (or you, or any other reader of the post) to demonstrate this, because regardless of whether DishBrain is hoax or not, that would be large research project worth of work to demonstrate this: "easiness" refers anyway to the final result ("this specific model of neuronal interaction easily explains the culture of neurons playing pong"), not to the process of obtaining this result.
So, I thought it is clear that this phrase is a rhetorical interjection.
And, again, as I said above, the entire first argument by Steven is niche and not central (as well as our lengthy discussion of my reply to it), so feel free to skip it.
Can you explain what you mean by "the problem of intrinsic contextuality" for those of us who aren't conversant with quantum physics?
Cognitive dissonance. Two probability distributions (generative models, in Active Inference parlance) not cohering, i.e., not combinable into a single probability distribution. See a concrete example in this comment:
I hope from the exposition above it should be clear that you couldn't quite factor Active Inference into a subsystem of the brain/mind (unless under "multiple Active Inference models with context switches" model of the mind, but, as I noted above, I thing this would be a rather iffy model to begin with). I would rather say: Active Inference still as a "framework" model with certain "extra Act Inf" pieces (such as access consciousness and memory) "attached" to it, plus other models (distributed control, and maybe there are some other models, I didn't think about it deeply) that don't quite cohere with Active Inference altogether and thus we сan only resort to modelling the brain/mind "as either one or another", getting predictions, and comparing them.
Here, predicting a system (e.g., a brain) in terms of distributed control theory, and in terms of Active Inference, would lead to incoherent inferences (i.e., predictions, or probability distributions about the future states of the system). And choosing which prediction to take would require extra contextual information (hence, intrinsic contextuality).
Contextuality is closely related to boundedness of cognition in physical agents (boundedness of representable models, memory, time and energy resources dedicated to inference, etc.) Without these limitations, you can perform Solomonoff induction and you are fine, enter AIXI. The problem is that Solomonoff induction is incomputable.
This post is a collection of my answers to each section of the post "Why I’m not into the Free Energy Principle" by Steven Byrnes.
TLDR: none of Byrnes' arguments appear valid and strong criticisms of the FEP (some are valid, but are not strong, and shouldn't lead to the conclusion that the FEP shouldn't be used, as Byrnes claims in these cases).
My own biggest problem with Active Inference, namely that it is already doomed as a general theory of agency because it's not ready for intrinsic contextuality of inference and decision-making. See the last section of this post. However, this doesn't mean that Active Inference won't be useful nonetheless: it's as "doomed" as Newtonian mechanics are doomed, however, Newtonian mechanics are still useful.
1
There is a claim about a brain, but a neural organoid: "We develop DishBrain, a system that harnesses the inherent adaptive computation of neurons in a structured environment. In vitro neural networks from human or rodent origins are integrated with in silico computing via a high-density multielectrode array. Through electrophysiological stimulation and recording, cultures are embedded in a simulated game-world, mimicking the arcade game “Pong.” Applying implications from the theory of active inference via the free energy principle, we find apparent learning within five minutes of real-time gameplay not observed in control conditions. Further experiments demonstrate the importance of closed-loop structured feedback in eliciting learning over time. Cultures display the ability to self-organize activity in a goal-directed manner in response to sparse sensory information about the consequences of their actions, which we term synthetic biological intelligence." (Kagan et al., Oct 2022). It's arguably hard (unless you can demonstrate that it's easy) to make sense of the DishBrain experiment not through the FEP/Active Inference lens, even though it should be possible, as you rightly highlighted: the FEP is a mathematical tool that should help to make sense of the world (i.e., doing physics), by providing a principled way of doing physics on the level of beliefs, a.k.a. Bayesian mechanics (Ramstead et al., Feb 2023).
It's interesting that you mention Noether's theorem, because in the "Bayesian mechanics" paper, the authors use it as the example as well, essentially repeating something very close to what you have said in section 1:
Note that the FEP theory has developed significantly only in the last year or so: apart from these two references above, the shift to the path-tracking (a.k.a. path integral) formulation of the FEP (Friston et al., Nov 2022) for systems without NESS (non-equilibrium steady state) has been significant. So, judging the FEP on pre-2022 work may not do it justice.
2
I don't understand what the terms "starting point" and "first step" mean in application to a theory/framework. The FEP is a general framework, whose value lies mainly in being a general framework: proving the base ontology for thinking about intelligence and agency, and classifying various phenomena and aspects of more concrete theories (e.g., theories of brain function) in terms of this ontology.
This role of a general framework is particularly valuable in discussing the soundness of the scalable strategies for aligning AIs with a priori unknown architecture. We don't know whether the first AGI will be an RL agent or a decision Transformer or H-JEPA agent or a swarm intelligence, etc. And we don't know in what direction the AGI architecture will evolve (whether via self-modification or not). The FEP ontology might be one of the very few physics-based (this is an important qualification) ontologies that allow discussing agents on such a high level. Other two ontologies that I have heard of are thermodynamic machine learning (Boyd, Crutchfield, and Gu, Sep 2022) and the MCR^2 (maximal coding rate reduction) principle (Ma, Tsao, and Shum, Jul 2022).
3
Don't you think that the control-theoretic toolbox becomes a very incomplete perspective for analysing and predicting the behaviour of systems exactly when we move from complicated, but manageable cybernetic systems (which are designed and engineered) to messy human brains, deep RL, or Transformers, which are grown and trained?
I don't want to discount the importance of control theory: in fact, one of the main points of my recent post was that SoTA control theory is absent from the AI Safety "school of thought", which is a big methodological omission. (And LessWrong still doesn't even have a tag for control theory!)
Yet, criticising the FEP on the ground that it's not control theory also doesn't make sense: all the general theories of machine learning and deep learning are also not control theory, but they would be undoubtfully useful for providing a foundation for concrete interpretability theories. These general theories of ML and DL, in turn, would benefit from connecting with even more general theories of cognition/intelligence/agency, such as the FEP, Boyd-Crutchfield-Gu's theory, or MCR^2, as I described here:
4
In section 4, you discuss two different things, that ought to be discussed separately. The first thing is the discussion of whether thinking about the systems that are explicitly engineered as RL agents (or, generally, with any other explicit AI architecture apart from the Active Inference architecture itself) is useful:
I would say that whether it's "easier to think" about RL agents as Active Inference agents (which you can do, see below) depends on what you are thinking about, exactly.
I think there is one direction of thinking that is significantly aided by applying the Active Inference perspective: it's thinking about the ontology of agency (goals, objectives, rewards, optimisers and optimisation targets, goal-directedness, self-awareness, and related things). Under the Active Inference ontology, all these concepts that keep bewildering and confusing people on LW/AF and beyond acquire quite straightforward interpretations. Goals are just beliefs about the future. Rewards are constraints on the physical dynamics of the system that in turn lead to shaping this-or-that beliefs, as per the FEP and CMEP (Ramstead et al., 2023). Goal-directedness is a "strange loop" belief that one is an agent with goals[1]. (I'm currently writing an article where I elaborate on all these interpretations.)
This ontology also becomes useful in discussing agency in LLMs, which is a very different architecture from RL agents. This ontology also saves one from ontological confusion wrt. agency (or lack thereof) in LLMs.
Second is the discussion of agency in systems that are not explicitly engineered as RL agents (or Active Inference agents, for that matter):
Imposing an RL algorithm on the dynamics of the lizard's brain and body is no more justified than imposing the Active Inference algorithm on it. Therefore, there is no ground for calling the first "normal" and the second "galaxy brained": it's normal scientific work to find which algorithm predicts the behaviour of the lizard better.
There is a methodological reason to choose the Active Inference theory of agency, though: it is more generic[2]. Active Inference recovers RL (with or without entropy regularisation) as limit cases, but the inverse is not true:
(Reproduced Figure 3 from Barp et al., Jul 2022.)
We can spare the work of deciding whether a lizard acts as a maximum entropy RL agent or an Active Inference agent because, under the statistical limit of systems whose internal dynamics follow their path of least action exactly (such systems are called precise agents in Barp et al., Jul 2022 and conservative particles in Friston et al., Nov 2022) and whose sensory observations don't exhibit random fluctuations, there is "no ambiguity" in the decision making under Active Inference (calling this "no ambiguity could be somewhat confusing, but it is what it is), and thus Active Inference becomes maximum entropy RL (Haarnoja et al., 2018) exactly. So, you can think of a lizard (or a human, of course) as a maximum entropy RL agent, it's conformant with Active Inference.
5
It's hard to criticise this section because it doesn't define "explicit" and "implicit" prediction. If it's about representationalism vs. enactivism, then I should only point here that there are many philosophical papers that discuss this in excruciating detail, including the questions of what "representation" really is, and whether it is really important to distinguish representation and "enacted beliefs" (Ramstead et al., 2020; Constant et al., 2021; Sims & Pezzulo, 2021; Fields et al., 2022a; Ramstead et al., 2022). Disclaimer: most of this literature, even though authored by "FEP-sided" people, does not reject representationalism, but rather leans towards different ways of "unifying" representationalism and enactivism. I scarcely understand this literature myself and don't hold an opinion on this matter. However, the section of your post is bad philosophy (or bad pragmatic epistemology, if you wish, because we are talking about pragmatical implications of explicit representation; however, these two coincide under pragmatism): it doesn't even define the notions it discusses (or explain them in sufficient depth) and doesn't argue for the presented position. It's just an (intuitive?) opinion. Intuitive opinions are unreliable, so to discuss this, we need more in-depth writing (well, philosophical writing is also notoriously unreliable, but it's still better than just an unjustified opinion). If there is philosophical (and/or scientific) literature on this topic that you find convincing, please share it.
Another (adjacent?) problem (this problem may also coincide or overlap with the enactivism vs. representationalism problem; I don't understand the latter well to know whether this is the case) is that the "enactive FEP", the path-tracking formulation (Friston et al., 2022) is not really about the entailment ("enaction") of the beliefs about the future, but only beliefs about the present: the trajectory of the internal states of a particle parameterises beliefs about the trajectory of external (environmental) states over the same time period. This means, as it seems to me[3], that the FEP, in itself, is not a theory of agency. Active Inference, which is a process theory (an algorithm) that specifically introduces and deals with beliefs about the future (a.k.a. (prior) preferences, or the preference model in Active Inference literature), is a theory of agency.
I think this is definitely a valid criticism of much of the FEP literature that it sort of "papers over" this transition from the FEP to Active Inference in a language like the following (Friston et al., 2022):
The bolded sentence is where the "transition is made", but it is not convincing to me, neither intuitively, philosophically, or scientifically. It might be that this is just "trapped intuition" on my part (and part of some other people, I believe) that we ought to overcome. It's worth noting here that the DishBrain experiment (Kagan et al., 2022) looks like evidence that this transition from the FEP to Active Inference does exist, at least for neuronal tissue (but I would also find it surprising if this transition wouldn't generalise to the cases of DNNs, for instance). So, I'm not sure what to make of all this.
Regardless, the position that I currently find (somewhat) coherent[4] is treating Active Inference as a theory of agency that is merely inspired by the FEP (or "based on", in a loose sense) rather than derived from the FEP. Under this view, the FEP is not tasked to explain where the beliefs about the future (aka preferences, or goals) come from, and what is the "seed of agency" that incites the system to minimise the expected free energy wrt. these beliefs in choosing one's actions. These two things could be seen as the prior assumptions of the Active Inference theory of agency, merely inspired by the FEP[5]. Anyways, these assumptions are not arbitrary nor too specific (which would be bad for a general theory of agency). Definitely, they are no more arbitrary nor more specific than the assumptions that maximum entropy RL, for instance, would require to be counted as a general theory of agency.
6
I think good literature that conceptualises evolutionary learning under the FEP only started to appear last year (Kuchling et al., 2022; Fields et al., 2022b).
7
The title of this section contradicts the ensuing text. The title says that recognition and action selection (plus planning, if the system is sufficiently advanced) are "at least partially" two different algorithms. Well, yes, they could, and almost always are implemented separately, in one or another way. But we also should look at the emergent algorithm that comes out of coupling these two algorithms (they are physically coupled because they are situated within a single system, like a brain, which you pragmatically should model as a unified whole).
So, the statement that considering these two algorithms as a whole is "counterproductive" doesn't make sense to me, just as saying that in GAN, you should consider only the two DNNs separately, rather than the dynamics of the coupled architecture. You should also look at the algorithms separately, of course, at the "gears level" (or, we can call it the mechanistic interpretability level), but it doesn't make the unified view perspective counterproductive. They are both productive.
As I also mentioned above, moving up the abstraction stack is useful as well as moving down.
Then, in the text of the section, you also say something stronger than these two algorithms are "at least partially" separate algorithms, but that they "can't be" the same algorithm:
I think you miss the perspective that justifies that perception and action should be considered within a single algorithm, namely, the pragmatics of perception. In "Being You" (2021), Anil Seth writes:
The pragmatics of perception don't allow considering self-supervised learning in complete isolation from the action-selection algorithm.
Bonus: Active Inference (at least, in its current form) is doomed due to the problem of intrinsic contextuality
Active Inference doesn't account for the fact that most cognitive systems won't be able to combine all their beliefs into a single, Bayes-coherent multi-factor belief structure (the problem of intrinsic contextuality). The "ultimate" decision theory should be quantum. See Basieva et al. (2021), Pothos & Busemeyer (2022), and Fields & Glazebrook (2022) for some recent reviews, and Fields et al. (2022a) and Tanaka et al. (2022) for examples of recent work. Active Inference could, perhaps, still serve as a useful tool for ontologising the effectively classic agency, or a Bayes-coherent "thread of agency" by a system. However, I regard the problem of intrinsic contextuality as the main "threat" to the FEP and Active Inference. The work for updating the FEP theory so that it accounts for intrinsic contextuality has recently started (Fields et al., 2022a; 2022b), but there is no theory of "quantum Active Inference" yet.
Given that Active Inference (at least, in its current form) is already doomed, it's clearly problematic, from the scientific point of view (but not from the practical point of view: like, Newtonian mechanics is "doomed", but are still useful), to take it as the general theory of agency, as I suggested in section 5 above.
I suspect that a fundamental theory of agency will require a foundational physical ontology that includes agency as a "first-class phenomenon". Examples of such theories are Vanchurin's "neural physical toolbox" (Vanchurin, 2020; 2022) and Hoffman's theory of conscious agents (Prakash et al., 2020; Hoffman et al., 2023).
References
Basieva, I., Khrennikov, A., & Ozawa, M. (2021). Quantum-like modeling in biology with open quantum systems and instruments. Biosystems, 201, 104328. https://doi.org/10.1016/j.biosystems.2020.104328
Boyd, A. B., Crutchfield, J. P., & Gu, M. (2022). Thermodynamic machine learning through maximum work production. New Journal of Physics, 24(8), 083040. https://doi.org/10.1088/1367-2630/ac4309
Constant, A., Clark, A., & Friston, K. J. (2021a). Representation Wars: Enacting an Armistice Through Active Inference. Frontiers in Psychology, 11, 598733. https://doi.org/10.3389/fpsyg.2020.598733
Constant, A., Clark, A., & Friston, K. J. (2021b). Representation Wars: Enacting an Armistice Through Active Inference. Frontiers in Psychology, 11, 598733. https://doi.org/10.3389/fpsyg.2020.598733
Fields, C., Friston, K., Glazebrook, J. F., & Levin, M. (2022a). A free energy principle for generic quantum systems. Progress in Biophysics and Molecular Biology, 173, 36–59. https://doi.org/10.1016/j.pbiomolbio.2022.05.006
Fields, C., Friston, K., Glazebrook, J. F., Levin, M., & Marcianò, A. (2022b). The free energy principle induces neuromorphic development. Neuromorphic Computing and Engineering, 2(4), 042002. https://doi.org/10.1088/2634-4386/aca7de
Fields, C., & Glazebrook, J. F. (2022). Information flow in context-dependent hierarchical Bayesian inference. Journal of Experimental & Theoretical Artificial Intelligence, 34(1), 111–142. https://doi.org/10.1080/0952813X.2020.1836034
Friston, K., Da Costa, L., Sakthivadivel, D. A. R., Heins, C., Pavliotis, G. A., Ramstead, M., & Parr, T. (2022). Path integrals, particular kinds, and strange things (arXiv:2210.12761). arXiv. http://arxiv.org/abs/2210.12761
Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. Proceedings of the 35th International Conference on Machine Learning, 1861–1870. https://proceedings.mlr.press/v80/haarnoja18b.html
Kagan, B. J., Kitchen, A. C., Tran, N. T., Habibollahi, F., Khajehnejad, M., Parker, B. J., Bhat, A., Rollo, B., Razi, A., & Friston, K. J. (2022). In vitro neurons learn and exhibit sentience when embodied in a simulated game-world. Neuron, 110(23), 3952-3969.e8. https://doi.org/10.1016/j.neuron.2022.09.001
Ma, Y., Tsao, D., & Shum, H.-Y. (2022). On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence (arXiv:2207.04630). arXiv. https://doi.org/10.48550/arXiv.2207.04630
Pothos, E. M., & Busemeyer, J. R. (2022). Quantum Cognition. Annual Review of Psychology, 73(1), 749–778. https://doi.org/10.1146/annurev-psych-033020-123501
Prakash, C., Fields, C., Hoffman, D. D., Prentner, R., & Singh, M. (2020). Fact, Fiction, and Fitness. Entropy, 22(5), 514. https://doi.org/10.3390/e22050514
Ramstead, M. J. D., Friston, K. J., & Hipólito, I. (2020). Is the Free-Energy Principle a Formal Theory of Semantics? From Variational Density Dynamics to Neural and Phenotypic Representations. Entropy, 22(8), Article 8. https://doi.org/10.3390/e22080889
Ramstead, M. J. D., Sakthivadivel, D. A. R., & Friston, K. J. (2022). On the Map-Territory Fallacy Fallacy (arXiv:2208.06924). arXiv. http://arxiv.org/abs/2208.06924
Ramstead, M. J. D., Sakthivadivel, D. A. R., Heins, C., Koudahl, M., Millidge, B., Da Costa, L., Klein, B., & Friston, K. J. (2023). On Bayesian Mechanics: A Physics of and by Beliefs (arXiv:2205.11543). arXiv. https://doi.org/10.48550/arXiv.2205.11543
Seth, A. K. (2021). Being you: A new science of consciousness. Dutton.
Sims, M., & Pezzulo, G. (2021). Modelling ourselves: What the free energy principle reveals about our implicit notions of representation. Synthese, 199(3), 7801–7833. https://doi.org/10.1007/s11229-021-03140-5
Tanaka, S., Umegaki, T., Nishiyama, A., & Kitoh-Nishioka, H. (2022). Dynamical free energy based model for quantum decision making. Physica A: Statistical Mechanics and Its Applications, 605, 127979. https://doi.org/10.1016/j.physa.2022.127979
Vanchurin, V. (2020). The World as a Neural Network. Entropy, 22(11), 1210. https://doi.org/10.3390/e22111210
Vanchurin, V. (2021). Towards a Theory of Quantum Gravity from Neural Networks. Entropy, 24(1), 7. https://doi.org/10.3390/e24010007
Cf. Joscha Bach's description of the formation of this "strange loop" belief in biological organisms: "We have a loop between our intentions and the actions that we perform that our body executes, and the observations that we are making and the feedback that they have on our interoception giving rise to new intentions. And only in the context of this loop, I believe, can we discover that we have a body. The body is not given, it is discovered together with our intentions and our actions and the world itself. So, all these parts depend crucially on each other so that we can notice them. We basically discover this loop as a model of our own agency."
Note, however, that there is no claim that Active Inference is the ultimately generic theory of agency. In fact, it is already clear that it is not the ultimately generic theory, because it is already doomed: see the last section of this post.
Note: I discovered this problem only very recently and I'm currently actively thinking about it and discussing it with people, so my understanding may change significantly from what I express here very soon.
But not really: see the last section on this.
Ramstead et al., 2022b might recover these from the FEP when considering one as a "FEP scientist" in a "meta-move", but I'm not sure.