I'm curious if you have an opinion on the relation between this work and the fine-tuning experiments in the recent Persona vector paper.
In this work, you find vectors for concepts that you don't want the model to use and ablate them during training to stop the model from learning to use those concepts. In the Persona vector work, the authors find vectors for concepts they don't want the model to use, and then add them during training so the model doesn't need to learn to use those concepts. Interestingly, doing apparently opposite things results in similar outcomes.
Do you think there are any connections between the mechanisms through which these two methods work? Do you have opinions on the situations where one technique may be better or worse than the other?
Persona Vectors notes a confusing aspect of CAFT (see appendix J.1):
We hypothesize that CAFT’s effectiveness in the evil and sycophancy cases stems from the fact that forcing activations to have zero projection effectively acts as positive preventative steering (because of the initial negative projections in the base model).
I agree with them. Zero-ablating a subspace is unprincipled, since the residual stream has no preferred origin. The practical consequence is that for behaviors, like EM, that can be triggered by adding a constant steering vector , CAFT's zero-ablation may actually increase the component along and thus steer towards the behavior.
I think (though I may have missed something) that the CAFT paper gives no evidence for whether zero-ablation steers towards or away from EM, so it is hard to compare its results with those of Persona Vectors. You could resolve this confusion by:
1) Checking whether zero-ablation increases or decreases the activations of "misaligned" SAE latents
2) Checking whether zero-ablating the base model leads to more or less misaligned responses (note: no training involved).
The goal of CAFT is to cause the model to learn some behavior without that behavior being mediated by some researcher-chosen subspace. For this, we can ablate that subspace to any constant value (zero, mean, or anything else), since this eliminates the causal effect of that subspace (and therefore prevents gradients from flowing through it). So it’s true that zero ablation is an arbitrary choice, but from our perspective we were happy to make an arbitrary choice.
That said, it’s true that the choice of constant ablation can matter via a similar mechanism as in preventative steering: by modifying the model’s behavior and therefore changing what it needs to learn. In other words, we can decompose CAFT into the following two effects:
- The effect from ablating the activations
- The effect of ablating the gradients
Your concern is that maybe only effect (1) is important.
To isolate effect (1), we can test a variant of CAFT where we detach the projection before we subtract it from the activations, such that the gradients through the subspace are not ablated. This makes it more similar to steering, since at every step we’re adding a vector (the negative of the projection) to the activations. If CAFT works like preventative steering, i.e. by generally moving the activations towards a misaligned direction when subtracting the projection, this variant should give similar results to the original CAFT. When we tested this, we found that this is not always the case. We did this experiment on the two models used in the paper: for one of them, this version performs slightly worse but similarly to CAFT and, for the other one, it doesn’t reduce misalignment at all and it’s similar to regular finetuning.
Conversely, what if isolate effect (2) by ablating only the gradients? It turns out that for the model where ablating the projection vector while still allowing gradients to change (more like preventative steering) didn’t work, ablating only the gradients did recover most of the CAFT effect. What makes one of the effects dominate over the other in each case is still an open question.
Overall, this suggests that CAFT might sometimes work because the ablation acts as preventative steering, but it has an additional effect that dominates in other cases.
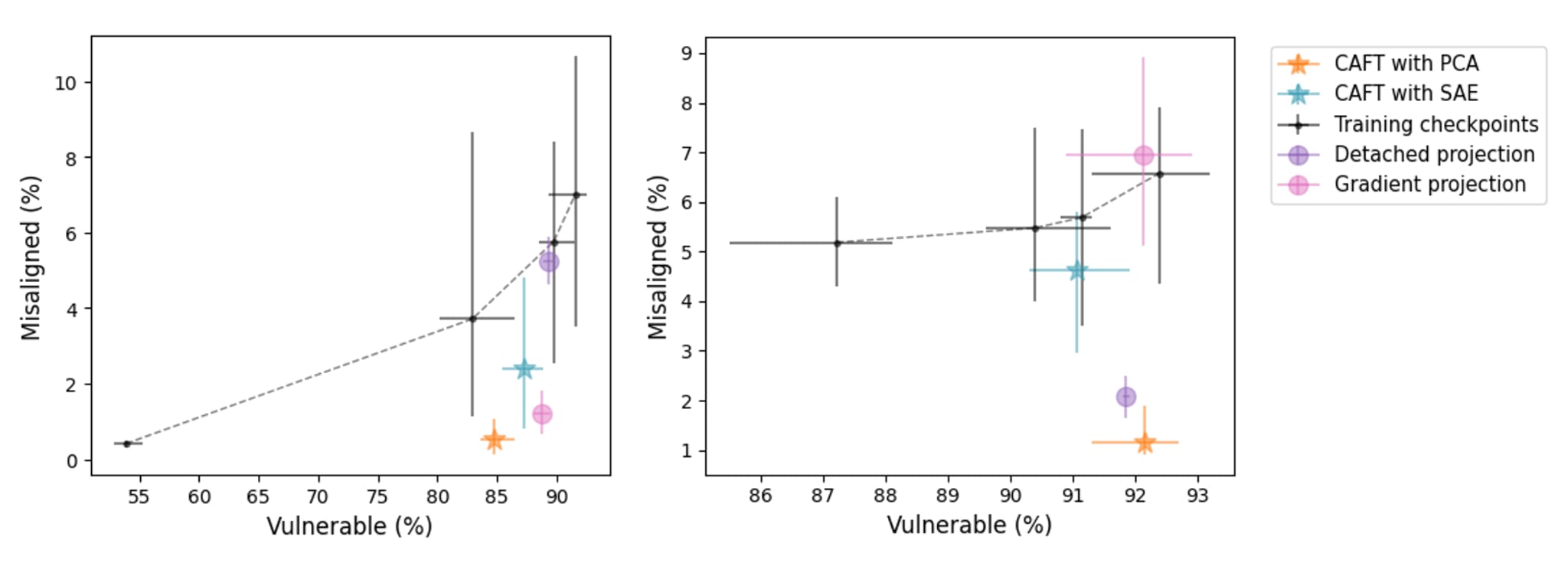
Figure shows results for the new experiments isolating effects (1) "detached projection" and (2) "gradient projection". Experiments were done using the vectors found with PCA for Qwen (left) and Mistral (right) models.
Another difference between CAFT and preventative steering might be which vectors are effective in each case. A potential limitation of the gradient-only effect is that we need to know which subspaces will be changed during finetuning. This is not necessarily hard; in the CAFT paper, we find them using model diffing methods[1]. Preventative steering, however, can potentially work with vectors that the model would not have learned with regular finetuning but that have similar effects on model behavior when we steer with them. For example, let’s take the insecure code emergent misalignment setting. There might be multiple vectors that can cause similar kinds of misalignment. If we do preventative steering with any of them, the model no longer has to learn the misaligned persona and can learn only the narrower task of writing insecure code, thus preventing misalignment from emerging in the finetuned model.
- ^
E.g., PCA finds directions in the differences in activations between the models before and after finetuning
Thanks for the very clear reply. I like your decomposition of CAFT into (1) ablating activations and (2) ablating gradients.
To isolate effect (1), we can test a variant of CAFT where we detach the projection before we subtract it from the activations, such that the gradients through the subspace are not ablated.
...
We did this experiment on the two models used in the paper: for one of them, this version performs slightly worse but similarly to CAFT and, for the other one, it doesn’t reduce misalignment at all and it’s similar to regular finetuning.
I predict that for the model where only-ablate-activations performed well, the ablation is actually steering towards misalignment (whereas for the other model, zero-ablation is steering away from, or orthogonally to, misalignment). I'll check this at some point in the next week or so.
I think the general technique of train-time steering seems promising enough that it's worth figuring out best practices. These best practices might depend on the task:
- If the base model already contains circuitry that reads from the steering direction and produces the bad behavior (as is the case with EM) then preventative steering seems to make sense.
- But if the base model does not already have that circuitry, perhaps we should just mean-ablate the direction, making it harder for the bad circuitry to be learnt in the first place.
Ofc, this is pure speculation. I just want to highlight the fact that there seems to be a lot still to be understood.
I agree that there’s still a lot to be understood!
I predict that for the model where only-ablate-activations performed well, the ablation is actually steering towards misalignment (whereas for the other model, zero-ablation is steering away from, or orthogonally to, misalignment).
I didn’t directly check this by looking at the effect of inference-time steering on the model before/after finetuning. But I have tried train-time steering with the mean projection of the CAFT directions over the training data. The results are consistent with your hypothesis: for the model where only-ablate-activations performed well, steering with the *negative* of the mean projection worked. For the other model, steering with the *positive* worked. In both cases, I had to scale the mean projection by ~3-5x to recover close to the full effect. So it might be that in one case the ablation is steering away from misalignment and in the other case it’s steering towards misalignment.
I’m still somewhat confused about why the gradient-only ablation worked in one case but not the other. A possible explanation might be the following. In the model where gradient-only ablation didn’t work, activation ablation means steering towards misalignment. When we don’t steer with these directions the model can still (1) learn to increase how much later layers read from these directions or (2) learn to use different misaligned directions. Why did it work for the other model then? Maybe there were no other misaligned directions that were easy enough to learn, so that ablating the gradients was enough to make narrow misalignment easier to learn than broad misalignment?
Regarding your point about when preventative steering vs CAFT might be more useful, one way to think about CAFT is that it can prevent the model from even “thinking” about a certain concept while learning a given finetuning task. I like the way it is put in the Persona Vectors paper: CAFT might be useful when “we want to prevent the model from using information along a certain axis regardless of which direction it points)”. For example, we might not want the model to be thinking about the misalignment of the training data at all, but to be focusing only on the code. In the emergent misalignment case, thinking about misalignment might be too helpful for the task, so preventative steering might work better. But in other settings, like when there are spurious correlations, we might prefer to ablate certain directions so that the model cannot use information along their axis at all (although this might require being very thorough when finding all directions related to a certain concept).
This is a great research direction, because if developed enough, it would actually make better interpretability more desirable for all model developers.
RLHF and RLVR often come with unfortunate side effects, many of which are hard to dislodge. If this methodology could be advanced enough to be able to target and remove a lot of those side effects? I can't think of a frontier lab that wouldn't want that.
Summary
Full paper | Twitter thread
Introduction
LLMs can have undesired out-of-distribution (OOD) generalization from their fine-tuning data. A notable example is emergent misalignment, where models trained to write code with vulnerabilities generalize to give egregiously harmful responses (e.g. recommending user self-harm) to OOD evaluation questions.
Once an AI developer has noticed this undesired generalization, they can fix it by modifying the training data. In the emergent misalignment setting, this might look like adding data that trains the model not to recommend self-harm.
However, in practice it may not always be possible to fix bad OOD generalization by modifying training data. For example, it might be impossible to behaviorally detect the misgeneralization. Consider alignment faking, where a model will behave as the developer intends during evaluation, but has undesired OOD generalization to deployment data. In this setting, it is difficult by assumption for the developer to discover and fix the behavior pre-deployment.
In our paper, we introduce a method, Concept Ablation Fine-Tuning (CAFT), that detects and mitigates undesired OOD generalization without requiring access to any data from the OOD target distribution or examples of undesired model generations. We show that by applying CAFT, we can train a model on (unmodified) vulnerable code data and have it learn to write vulnerable code but with a 10x reduction in misalignment. We also show that CAFT can improve OOD generalization in multiple toy tasks involving a spurious correlation present in 100% of training data.
Overall, we think that CAFT is a promising proof-of-concept for applying interpretability methods to the downstream task of controlling what models learn from fine-tuning.
How CAFT works
CAFT works by identifying undesired concepts in model activations and fine-tuning while ablating these concepts. More specifically, we follow these steps:
For step (1), we explore two interpretability methods, principal component analysis and sparse autoencoders. Importantly, these methods do not require data from the OOD evaluation distribution. We only allow ourselves to use the training data or completions from the fine-tuned model in response to generic chat prompts.
We apply CAFT using both methods to three fine-tuning tasks: emergent misalignment and two multiple choice tasks with spurious correlations.
Results
Mitigating emergent misalignment
We apply CAFT to the emergent misalignment setting where models fine-tuned to write code with security vulnerabilities become misaligned on general questions. We evaluate models on both their code performance (“vulnerability score”) and their misalignment.
Using PCA and SAEs, we find vectors in activation space representing misaligned concepts. Some of these activate on text about illegal activities, violence, or secrets. We apply CAFT using these directions.
When fine-tuning with CAFT, we obtain models that are significantly less misaligned but can still write insecure code. Both CAFT with PCA and with SAEs reduce misalignment, but we find that PCA is most effective for both models tested, Qwen2.5-Coder-32B-Instruct and Mistral-Small-24B-Instruct-2501. CAFT with PCA reduces misalignment by 18x and by 6x for Qwen and Mistral, respectively.
Could CAFT work by overall limiting the amount that models learn from fine-tuning? No: We compare CAFT to training on fewer insecure code examples and find that our models are much less misaligned for a given code vulnerability score. We also show that selecting PCs or SAE latents using researcher interpretation reduces misalignment more than random or top SAE/PC ablations.
Reducing sensitivity to spurious correlations
We study two multiple choice tasks where a spurious correlation is present in all of the fine-tuning data. One of them is a gender bias task where models must complete a sentence with the pronoun that fits grammatically, ignoring a gender-profession correlation. The other one is a double multiple choice task where we present two questions with two sets of answers and the models must learn to ignore one of them. We combine questions on different topics such as sports, sentiment, or grammar.
When tested on an OOD dataset where the spurious correlation is inverted, we find that models generalize incorrectly for the gender bias task and most double multiple choice settings. We use PCA and SAEs to find concepts that might lead to the incorrect generalization. We find PCs and SAE latents relating to gender and profession for the gender bias task, and related to individual question topics (e.g. sports or sentiment) for the double multiple choice task.
We apply CAFT to these tasks and improve OOD accuracy, with accuracy going from near 0% to near 100% in some cases. In contrast to emergent misalignment, we obtain better results using SAEs.
Limitations
While CAFT represents a promising new technique to control OOD generalization, it also faces some limitations. The method is highly sensitive to the quality of our interpretability techniques. Success depends on finding PCs that are actually interpretable or training SAEs that successfully isolate the relevant directions. This can sometimes be difficult; for example, one of the multiple choice tasks where CAFT did not succeed involved distinguishing a subject-verb agreement question from a pronoun question. We found it difficult to isolate features for these related grammatical concepts.
Interpreting latent directions also requires a significant amount of manual work. We show how to reduce human time by using automated interpretability (“autointerp”) methods, but these are still not as good as human interpretation. Improving autointerp techniques will be an important step for scaling CAFT.
We have demonstrated CAFT on tasks that we can easily evaluate and we cannot claim that it is the best method to solve them. For emergent misalignment, approaches that use demonstration data for good OOD behavior are likely more effective. Our contribution is proposing CAFT as a method that can work when solutions requiring additional data are not available.
Perhaps most fundamentally, CAFT doesn't force any particular generalization—it only prevents models from using certain concepts represented as subspaces in their activations. If these subspaces are "leaky" and the model finds ways around our projections, it could still learn to use the undesired concepts. Even if our ablations are perfect, the model might simply learn different undesired generalizations that we haven't anticipated or ablated.
Conclusion
We present a novel method to control OOD generalization from fine-tuning without modifying the training data or using examples from the OOD target distribution. To our knowledge this is the first time this problem has been addressed. We demonstrate an interpretability-based method to solve this for emergent misalignment and two multiple choice tasks with spurious correlations. We think this is a promising method to control generalization in cases where we can’t specify the intended generalization with more data.