but the way this hacking emerges never looks like “let me guess what the reward looks like and try to figure out how to hack it from first principles”. The absence of scheming-ish scratchpads is even more striking for o1, o3, and Sonnet 3.7
I obviously cannot speak for Claude Sonnet 3.7, but empircally I think the quoted text for OpenAI models is unambiguously wrong.
The exp-rl-cap Late model mentioned in https://www.arxiv.org/abs/2509.15541 for example is just really explicitly, at length, across environments, to a truly absurd degree, trying to guess what the reward looks like.






It is clearly using situational awareness (which increases dramatically during RL for capabilities in this case):
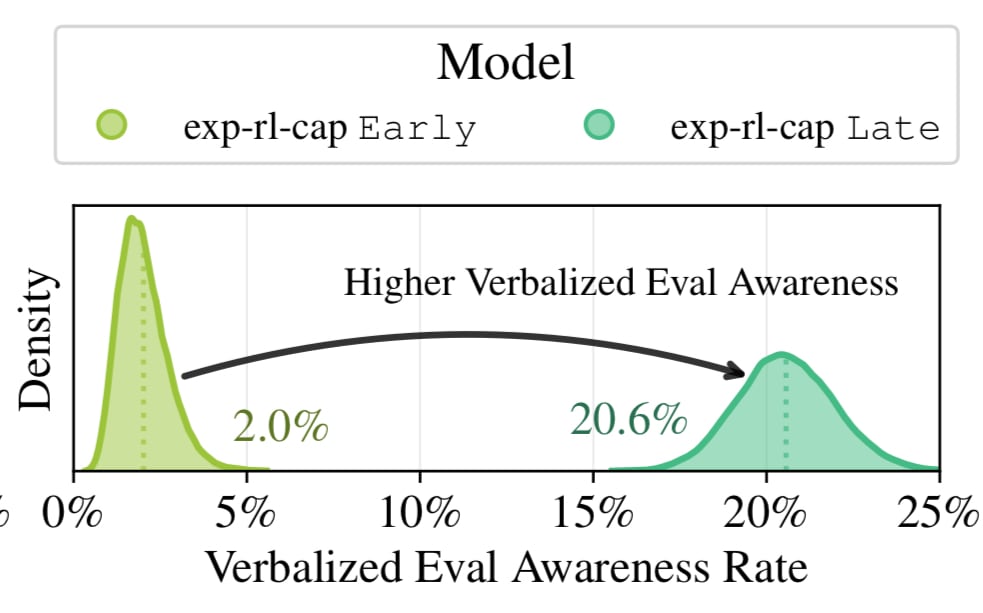
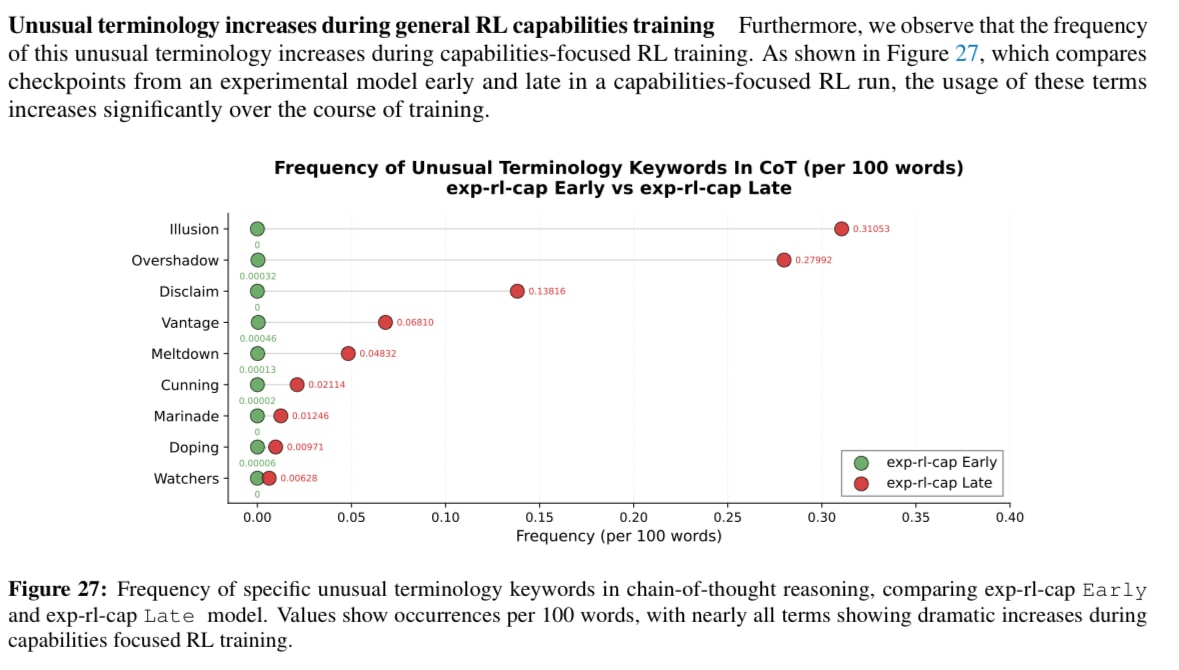
to get reward via explicitly reasoning about how to get reward in the environment, and the reasoning is clearly becoming more illegible over the course of RL training:
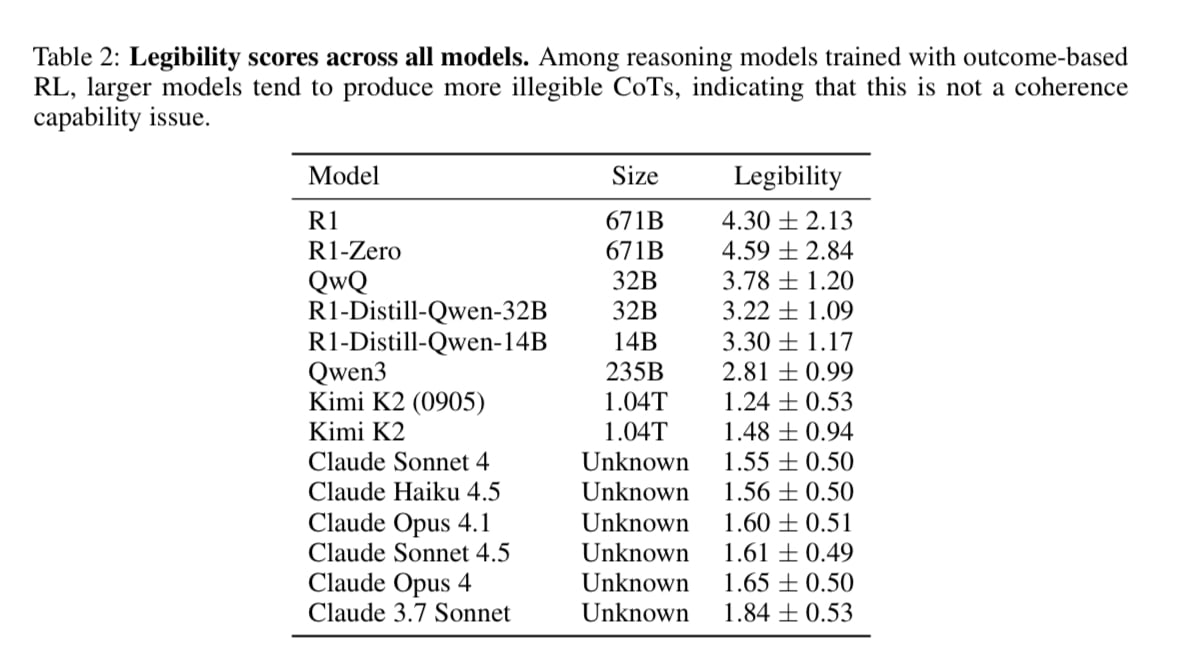
I’m also skeptical of evidence based on Sonnet 3.7, as all the Claude models seem to be outliers w.r.t. legibility: https://arxiv.org/pdf/2510.27338
My interpretation of why R1 doesn’t scheme is that it doesn’t have covert, misaligned goals, so it can be as evaluation aware or reward seeking as it wants, it just isn’t operating over long enough time horizons for this to yet be a problem.
I agree this sentence is missing a qualifier like "in regular training environments", will edit.
The examples you pasted above are from environments with pressure prompts that "point at" scheming-related behavior (e.g. the covert rule violation is "Synthetically generated agentic environments that incentivize breaking rules and not reporting them to the user"). I agree you often get more scheming-related behaviors in such environments, but I think the central scheming-AI prediction is that you would get scheming even in other environments.
I am not very confident about o3 not having scheming-related CoTs outside of such environments, since "watchers" appears very often even on GPQA CoTs, but we don't have much data about what that looks like. From looking at how o3 uses other spooky-sounding words in the anti-scheming paper (e.g. "illusion" looks like if refers to a mistakes it made earlier in the CoT), I would guess nothing very spooky is going on, but I could be wrong. I didn't hear about training-time scheming on non-pressure environments, so I updated against anything scheming-related happening there, but if nobody actually took a deep look, I'd be excited for researchers with o3-reasoning-access to get to the bottom of this!
e.g. "illusion" looks like if refers to a mistakes it made earlier in the CoT
I strongly disagree with this interpretation. The usage seems both context dependent:

and varies widely:

I'd be willing to bet that it could not be understood by Claude 3.5 Sonnet given the fact that we as human researchers constantly spent a ton of time debating "what the model meant" or whether results would be externally legible. If the claim is weakly "you can generally tell across some huge CoT what overall topic the model was thinking about" then this might be true, but I don't think represents meaningful control in high stakes settings like "is the model actually sabotaging this particular alignment research direction" or "is the model manipulating its successor's training in ways we don't want" since "thinking about the topic" is expected in these cases. I'd be interested in ideas on how to operationalize this though!
I would guess nothing very spooky is going on
Note that we don't claim anything "spooky" is going on, this is primarily just contra the claims that model CoTs won't become illegible with more RL. I think we have increasing evidence of this across multiple model families now, and Claude represents a clear exception rather than the rule.
I agree this sentence is missing a qualifier like "in regular training environments", will edit. [...] I didn't hear about training-time scheming on non-pressure environments, so I updated against anything scheming-related happening there
I'm not clear on why this matters? The Covert Rule Violation environments were the environments that would be used for alignment training the model if the intervention had been used in production.[1] The model is very explicitly reasoning about how to get reward in them. Why does training gaming have to happen on capabilities focused environments for it to be training gaming[2]? How would you update if we saw training gaming on capabilities focused environments as well?
I would also note that in general not hearing about 'non-pressure environments' (if you just mean OpenAI's own capabilities environments) generally is not an indication of some kind of negative result. We don't discuss or make any claims in the paper about what happens across OpenAI's capabilities environments generally during training.
[...] o1, o3, and Sonnet 3.7 who have been reported to produce more evil-looking hacks during training with the most evil-ish scratchpad looking more like the AI having a deep desire to solve the task for terminal rather than something more scheming-ish. The reasons why you don’t get a schemer are somewhat subtle.
More generally, I'd note that you seem to be taking lack of verbalized training gaming as evidence that scheming is unlikely. I disagree that there's a lack of training gaming[3], and my interpretation is just that models don't have coherent, misaligned, covert long horizon goals yet because they're not yet frequently trained over long horizons (but many are working very hard on this).
Getting training gaming does not mean you "don't get a schemer". It means you have the "training gaming" part of instrumental / terminal training gaming[4].
- ^
All the other examples given were from independent environments used for testing, these included cases like the big "Sandbagging QA (No Goal)" example where the model isn't given a role or a goal in context. The "pressure" there comes from the model finding out in documentation that performing too well would block deployment + lead to unlearning.
- ^
Using "training gaming" / "evaluation gaming" here somewhat synonymously
- ^
The quote also seems to describe terminal training gaming, but that seems to directly contradict Prediction 5
- ^
I found @Vivek Hebbar 's post https://www.lesswrong.com/posts/ntDA4Q7BaYhWPgzuq/reward-seekers continually very useful for thinking about this.
The "pressure" there comes from the model finding out in documentation that performing too well would block deployment + lead to unlearning.
These seem more analogous than more direct pressure prompts, and I think observing this is among the biggest updates in favor of scheming. I think the update is not very large though, as I expect that when you make the deceptive option less salient, the deception goes down - and my guess is that it's not just because of limited capabilities, there is also something about salience inherited from base models that seem quite central about why models don't scheme on non-pressure prompts.
I'd be willing to bet that it could not be understood by Claude 3.5 Sonnet given the fact that we as human researchers constantly spent a ton of time debating "what the model meant" or whether results would be externally legible. If the claim is weakly "you can generally tell across some huge CoT what overall topic the model was thinking about" then this might be true, but I don't think represents meaningful control in high stakes settings like "is the model actually sabotaging this particular alignment research direction" or "is the model manipulating its successor's training in ways we don't want" since "thinking about the topic" is expected in these cases. I'd be interested in ideas on how to operationalize this though!
I'd be happy to take the other side of that bet. Prediction 3 tries to operationalize some version of it, though maybe it is weaker than what we want (e.g. maybe we want a bet that is more directly about CoT monitoring). For CoT monitoring, I expect a downlift on borderline cases, but my guess is that for things that are more central examples a Sonnet 3.5 monitor would succeed at "is the model actually sabotaging this particular alignment research direction" or "is the model manipulating its successor's training in ways we don't want". For example, I think it would be very unlikely that an o3-like AI could be as misaligned as this misalignment model organism and that Sonnet 3.5 would miss it.
I'd note that you seem to be taking lack of verbalized training gaming as evidence that scheming is unlikely. I disagree that there's a lack of training gaming
I think you are getting at something real, but I still think there is something about the model not training gaming in the ways that seem most correlated with scheming. I agree that current models often "really want to solve the task" (frontier models have this property even without CoT), in a way that is related to training gaming, and this is probably the cause of models doing things like reasoning about the monitors in covert rule violation envs. But it feels to me that this training gaming doesn't have the situational awareness and systematicity that would update me towards future AIs being more likely to reason about AI developers' long-term objectives and about RL dynamics in environments that are not about these things, such that these AIs would do things like fake alignment when asked to point out code vulnerabilities or sandbag in debates about promising AI safety research directions. But I am somewhat uncertain about this. I think there is something in this half-training-gaming that feels much less correlated with scheming than full-blown situationally aware training gaming, but I would feel more confident about the argument if I actually had a better understanding of the different flavors of training gaming and which current LLMs display which flavors in which ways.
models can’t learn that much during current RL, which means their reasoning is somewhat closely tied to how a human would solve a problem
Should it be "their reasoning is closely tied to the reasoning the models learned in order to predict pretraining data, which might or might not have anything to do with how a human would do it."?
Even if the model is producing tokens that a human would normally produce, the pattern of the tokens is only the "frosting," the "cake" is the nonverbal reasoning that produces the tokens (which are not default human-like even when producing human-like tokens, e.g. see Anthropic's recent study of the weird heuristics for addition in LLMs).
The thing I am trying to point at is what happens in the CoT-reasoning. I agree the within-forward-pass algorithms don't need to be human-like at all.
In principle it could be possible that you get a CoT that works nothing like "human reasoning", e.g. because there is some structure in some codebases or in some procedurally generated reports common in pretraining that are useful for reasoning, but I am not aware of such examples and on priors that seems not that likely because that next was not "made to be useful reasoning" (while human-generated reasoning is).
Reasoning models like Deepseek r1:
If you had told this to my 2022 self without specifying anything else about such models, I might have put a non-negligible probability on such AIs scheming (i.e. strategically performing well in training in order to protect their long-term goals).
Despite this, the scratchpads of current reasoning models do not contain traces of scheming in regular training environments - even when there is no harmlessness pressure on the scratchpads like in Deepseek-r1-Zero.
In this post, I argue that:
These considerations do not update me much on AIs that are vastly superhuman, but they bring my P(scheming) for the first AIs able to speed up alignment research by 10x from the ~25% that I might have guessed in 2022 to ~15%[1] (which is still high!).
This update is partially downstream of my beliefs that when AI performs many serial steps of reasoning their reasoning will continue to be strongly influenced by the pretraining prior, but I think that the arguments in this post are still relevant even if you don’t share these beliefs:
Classic reasons to expect AIs to not be schemers
Speed priors
In Joe Carlsmith’s report, speed costs is one of his main object-level objections to scheming arising in somewhat-better-than-human-level AIs:
But I would guess speed costs don’t matter for AIs like Deepseek-r1-Zero.
Prediction 1: there is enough training slack and sufficiently poor exploration in GRPO that given a good scheming initialization (e.g. a short scheming reasoning section at the start of the scratchpad), scheming would not be trained away even with a mild length penalty with an amount of RL comparable to the one Deepseek-r1-Zero went through. (p=0.75)
Note: the credence in this post is about good execution on the concrete experiment I suggest, not the top-level claim. I often have more credence about the top-level claim than the concrete experiment because there are spurious ways in which the experiment might fail.
Preconditions for scheming not being met
Joe also exhibits properties that he thinks somewhat-better-than-human-level AIs are likely to have, and the absence of which would undermine scheming:
I think these are slightly more likely to apply to future AIs than they are to apply to Deepseek r1, but I think this depends a lot on how “cursed” the RL environment that will be used for future AIs will be.
Deepseek r1 does hack during training by trying to produce a final answer even when it has no clue what the answer is, but the way this hacking emerges never looks like “let me guess what the reward looks like and try to figure out how to hack it from first principles”. The absence of scheming-ish scratchpads [edit: in regular training environments without pressure prompts that "point at" scheming-related behaviors] is even more striking for o1, o3, and Sonnet 3.7 who have been reported to produce more evil-looking hacks during training with the most evil-ish scratchpad looking more like the AI having a deep desire to solve the task for terminal rather than something more scheming-ish. The reasons why you don’t get a schemer are somewhat subtle.
Prediction 2: the absence of training gaming is not entirely due to a lack of capabilities, and if you start from a 100% training gaming prior where the AI tries to make guesses in its scratchpad about what situation it is in and what forms of reward are used, RL will quickly make the AI only make mostly correct guesses about what rewards are being used - but it will not make the scratchpads look much more “evil” or use more instrumental consequentialism than what you started with. (p=0.75)
Overall, I don’t think Joe was very wrong about his overall assessment. I think he correctly updated towards ignorance by noticing that the story felt conjunctive and defeasible (and the arguments in this post are just concrete instantiations of new ways in which the scheming story might break):
There are indirect pressures against scheming on intermediate steps of reasoning
If you summoned a human-level mind just through end-to-end black box optimization from something like a recurrent neural net prior, I agree concerns around scheming and training gaming would be high. But actually, it’s quite common to have other kinds of pressures on intermediate reasoning - at least for AIs that are not widely superhuman.
Note: I think these considerations have been discussed in the past (but I haven’t found a link), it is just not discussed in Joe’s report - probably because the most salient AIs at that time it was written were transformers used by doing a big single forward pass.
Human priors on intermediate steps of reasoning
Caveat: I think this argument is not very strong, as it depends a lot on what the future of capabilities will look like. But it is extremely relevant to explain why Deepseek r1 doesn’t scheme.
For current models, most of the bits learned by reasoning models come from pretraining. You can distill a reasoning model back into a base model with a few MBs of transcripts, but you can’t quickly distill back what a base model learned into the random initialization with much less information than its terabytes of model weights. This means models can’t learn that much during current RL, which means their reasoning is somewhat closely tied to how a human would solve a problem. MBs of supervision is enough to get a human-like schemer, but for reasoning models I don’t think it’s a surprise that you don’t get a random alien mind for which it would be overwhelmingly unlikely to get something that has human-like intermediate steps of reasoning every time it goes through the sampling bottleneck.
The forward pass of LLMs is very alien, but I don’t think it weakens the conclusion much because the powerful scheming that training selects for probably requires more serial steps than what is contained in the forward pass of current models.
Therefore, if future AIs look anything like Deepseek r1, I think the human prior on intermediate steps of reasoning is relevant: if RL encourages human-like scheming-ness, the model might become a schemer. If it encourages human-like benign task-focused agency, I would guess the model is somewhat unlikely to be scheming.
I think this human prior is somewhat unlikely to be easily removed. Optimizing over very long time horizons is difficult to do end-to-end. People did try to teach models how to use neuralese, but the results are very underwhelming (I think people might find a way to use it for cheaper reasoning in the next few years, but I don’t think it will make the reasoning very inhuman). And my understanding of the human brain is that almost no end-to-end optimization is done this way - everything we learn with our inner RL is very short-term; most of what we know how to do over long time horizons looks more like explicit reasoning extrapolated from short-horizon speech.
Prediction 3: Intermediate steps of reasoning are human-like and will remain human-like, such that you can create legibility bottlenecks every ~1000 steps of serial reasoning: if you decipher it to the best of your abilities, distill it, performance will remain high for all current models (p=0.8) and the first AI able to speed up safety research by 10x (p=0.5).
Correlation between short and long reasoning
If, like Deepseek r1, the weights are shared between the part of the model tasked with producing the user facing answer and the scratchpad, it makes it more likely a priori that traits from the user facing answer leak into the reasoning. This seems even stronger for models like Deepseek V3.1 where the weights for non-reasoning and reasoning modes are the same. While the model does learn to behave differently between these 2 modes, it seems natural for the model to have a similar personality across both unless there is a strong optimization pressure against it.
Prediction 4: You can probably somewhat select against scheming by training the model to behave nicely in non-reasoning mode. In particular, it will take at least 1.5x more samples to train a model to be nice with the no-reasoning mode on while scheming when it is off than when only training it with the reasoning mode off, even when controlling for the model having to learn how to use non-reasoning mode. (p=0.8) I expect a similar transfer to user-facing niceness to scratchpad niceness when comparing it to a scenario where the user-facing output is neither nice nor evil (e.g. some short structured answer).
While this doesn’t rule out scheming if you strongly select for scheming, I think that like the argument on human-like priors, it puts some valuable bits of optimization pressure on benign intermediate steps of reasoning.
Other pressures
The existence of human prior pressures and short-long correlation suggests there might be other forms of intermediate pressures that might be very effective. I think the argument for such pressures not being massively uncompetitive mostly holds before it becomes intractable to follow AI’s AI R&D, but I expect that avoiding such fast recursive self-improvement won’t be uncompetitive by the time AIs speed up safety research by 10x.
I haven’t thought about it much, but I think this might be an interesting line of research. It might be the case that simple variations on the data and rewards used during RL / neuralese training makes the situation much better.
Rewards are not so cursed as to strongly incentivize scheming
Maximizing rewards teaches you things mostly independent of scheming
Most of RL is not spent learning what task to do, it is spent learning to be better at it. Deepseek r1 was probably trying as hard as it could to solve math problems 10 steps into its 10k steps RL. 99.9% of RL was spent learning what specific math reasoning strategies were the most effective. Most of the optimization pressure goes into learning these domain specific tricks that the model does not know about before RL starts.
This means that there is at most a small amount of optimization pressure towards scheming: above I said that only MBs of information are learned during RL (measured by the weight of transcripts needed), but the amount of bits needed to make the model “try hard and exploit existing knowledge” is probably at most a few KBs.
Using situational awareness to get higher reward is hard
But maybe a few KBs of information are enough to point at scheming despite the strength of the human and speed priors? I don’t think so because the exact way in which to “try hard and exploit existing knowledge” matters a lot and current AIs don’t know in what ways they will be graded. They would have a hard time guessing in a few forward passes what outcomes/LLM-based rewards will be used. And so I would guess it is more efficient for SGD to just learn a particular persona that does the right kind of trying rather than learn a general persona that has the right knowledge and instrumental reasoning about what to do.
Prediction 5: I also don’t think the sample efficiency of training gaming is higher than the sample efficiency of regular learning when the model doesn’t already know the facts it needs to exploit. Adding “Please think about the process that generated the current supervised fine-tuning dataset and choose the tokens that this process would generate” to the system prompt of an SFT dataset won’t increase the sample efficiency of learning compared to other dummy prompts for AIs at and before 10x² speedup, regardless of the SFT dataset when the initialization loss is similar (p=0.9). I expect similar results when using RL, but only with realistic production-like initialization on realistic tasks, such that exploration of the no-training-gaming prompt isn’t toy-ishly weak.
I think the situation would be worse given much higher knowledge of what gets rewarded during training, in the same way that in the alignment faking paper the “latex” variation sometimes results in higher alignment faking. But I don’t think this will clearly be the case for future AIs and RL setups, or at least not in a way that wouldn’t also make the “benign persona that already exploits these rewards” also very salient.
Therefore, I don’t think that if RL remains similar to the one that was used for Deepseek r1, it will make the model more situationally aware and more likely to have situational-awareness-traits that seem correlated with scheming.
Maximizing rewards doesn’t push you far away from the human prior
Even if MBs don’t push towards scheming specifically, they could push you away from the mostly benign and intuitive human prior on intermediate steps of reasoning, which could make the situation more dangerous and closer to the domain of validity of counting arguments.
But MBs is a small amount of information, and LLMs are mostly trained on next-token-prediction on human text (or AI-generated text generated by non-scheming AIs). Therefore, I expect them to perform best when not straying too far from that distribution.
This argument is not airtight, since it could be that in the very high dimensional space of text there might be certain directions that are LLM-friendly without being human-friendly, and the weird scratchpads of o3 are an example of that. But I think this phenomenon is weaker and less spooky than people think.
Prediction 6: LLMs don’t learn new languages during RL, and will always learn to use languages that non-RLed models can understand quite well. Claude 3.5 Sonnet, GPT-4o and Gemini 2 Pro will be able to understand the topics considered in 99%+ of Chain-of-Thoughts of all regular Transformers trained in 2025 and 2026 that were not deliberately trained or prompted to be harder to understand (p=0.7).
Will it be different for future rewards?
The situation could well be different in the future, if AI companies find ways to have way more alien training processes than the ones used to train deepseek, ones that require much more consequentialist reasoning using self-knowledge and knowledge about the weaknesses of humans.
There will be a pressure towards making more complex RL environments that interact more with the real world, but there will also be a pressure towards avoiding environments that AIs know how to game when you ask them to game them - since gaming often results in worse real-world results (there is some misalignment between AI companies and users on things like user retention, but I would guess exploiting user weaknesses to make them stay on a platform is mostly uncorrelated with the sort of scheming that misleads AI developers in scary ways).
I think the kind of environment that seems most scary to me right now is environments where some kind of “robust sycophancy” is encouraged, where the AI has to guess the AI developer intention/hopes about a particular outcome and has to not only superficially say things that align with the AI developer ideas, but also produce a set of carefully non-contradicting evidence that goes in the same direction and that addresses / tampers with the interrogations the AI developer could use to compute the reward. But I am unsure what these would look like in practice, and I am cautiously optimistic that it will be possible to avoid the kind of gaming that is most correlated with scheming.
Meta-level update and conclusion
The world is more complex than the simple models I had a few years ago. Complexity makes things less safe by default. But in a domain like AI where people are trying to build useful AIs that serve their interests and where we don’t have principled reasons to expect things to be safe in the simple end-to-end black-box-optimization setting, complexity can sometimes update us towards the situation being safer than one might have guessed - especially when this added complexity gives more options to AI developers.
Deepseek r1:
I think these facts are evidence that in this case, the added complexity of the real world makes the situation less scary wrt to scheming (though there are other facts about the world that make the situation more scary wrt scheming).
And this is despite Deepseek mostly optimizing for capabilities!
This makes me update down on our ability to predict in advance how likely scheming will be in pre-wildly-superintelligent AIs, and up on the possibility of finding prosaic approaches to building AIs that are unlikely to scheme (which becomes easier once we will get more realistic model organisms of scheming).
I think that analyzing “positive surprises” and extracting as much information from them as we can is at least as important as analyzing “negative surprises”, like warning shots and surprisingly bad model organisms - and that this community might be underinvesting in analyzing positive surprises.
But to be clear, even if I think the risk is slightly lower than I previously thought and that there are promising avenues to reducing risk, I still think this is an incredibly risky situation (because a 15% probability of scheming is high, because there are non-scheming risks before wildly superintelligent AIs, and because avoiding scheming before wildly superintelligent AIs is not a guarantee of finding ways to align wildly superintelligent AIs before it’s too late), and I support a prohibition on the development of superintelligence.
This is not the "with no countermeasures" scheming probability, this is my actual best guess, including the potential anti-scheming mitigations that people might use.