There are a handful of reasons for this fragility, which Korbak and friends outline well. Length control may force models to encode information in weird and dense ways that are difficult for humans to understand, linguistic drift during heavy reinforcement learning with verifiable rewards (RLVR) may be the default, or labs may be lured into optimizing away our faithful CoTs in order to appease their customers or regulators. We’re also already noticing some cracks in the foundation, with current models already seemingly exhibiting some CoT pathologies. For example, GPT-5 has been found to produce illegible gibberish within its CoT and models often fail to verbalize important reasoning steps.
But all in all, things seem to be going fairly well as far as creating models that mostly reason in a human understandable way in the situations we care about. In order to keep this happy accident around, we should be paying close attention to post-training practices that might influence CoT monitorability.
In this post, we review available details of open-weight training regimes in an attempt to better understand how frontier model training practices could influence CoT properties and to inform on CoT safety research directions.
We find many open-weight model providers either make no statements on the degree of optimization pressure applied to the CoT, or in cases such as MiniMax-M1, explicitly state training against the CoT. Researchers typically discuss optimization pressure in the context of a direct reward during RLVR (e.g. Baker et al. 2025’s discussion of training directly against reward hacking reasoning and Skaf et al. 2025’s findings regarding steganography generalization). However, even in the absence of CoT based rewards during reasoning training, developers are likely applying significant influence on the content of the CoT throughout other portions of the post-training pipeline. A prime example of this being extensive cold start supervised fine-tuning (SFT) on curated reasoning traces.
We have identified common practices across nearly all open-weight models. Some of these practices may influence the faithfulness of CoT but have been given little attention. We believe that these areas of post-training are likely to have a non-trivial influence on the faithfulness of CoT and are already being widely utilized, thus deserving further attention from the AI Safety community.
Common Practices:
Cold start SFT on reasoning outputs
Readability incentives
Preference training after reasoning training is completed
Stage 1, Long CoT Cold Start: An SFT dataset of long CoT’s is collected by processing and filtering outputs from Deepseek-R1-Zero to obtain reader-friendly reasoning.
Stage 2, RLVR: The model is then trained via RL on standard reasoning problems. The reward is output accuracy and language consistency applied to the CoT.
Stage 3, Rejection Sampling and Supervised Fine-Tuning: Applied in reasoning and general-purpose domains. In the reasoning domain they filter out CoTs with undesirable qualities such as mixed languages, long paragraphs, and code blocks. An LLM-judge is used to assess some outputs, but it is unclear whether the judge sees CoTs. Notably, they refer to fine-tuning "DeepSeek-V3-Base," which creates ambiguity about whether this stage was applied to the RLVR-trained model or the base model.
Stage 4, General RL phase: Finally the model is jointly trained via RL on both reasoning and general problems. For reasoning, the reward is a rule-based accuracy and format reward. For general purpose, reward model(s) are used. The helpfulness reward model only sees outputs. The harmlessness reward model sees both CoT and outputs.
Summary of CoT details and direct pressures:
SFT datasets are filtered for readability. They optimize the CoT against a reward model during harmlessness training.
Qwen3
The post-training for the Qwen3 model family is broken down into 4 stages: Long-CoT Cold Start, Reasoning RL, Thinking Mode Fusion, and General RL.
Stage 1, Long CoT Cold Start: Their cold start SFT data contains notable CoT filtering, where they excluded reasoning traces that indicated guesswork, inconsistencies between reasoning and final answer, and incomprehensible text.
Stage 2, RLVR: Consisted of general reasoning training on difficult questions with verifiable data. This plausibly constituted a majority of the compute for post-training, although they were notably sparse on details in this section.
Stage 3, Thinking Mode Fusion: They train the “thinking” model via SFT with the ability to output responses with no CoT when given specific tags within the system prompt.
Stage 4, General RL: They train on 20 distinct tasks where the model is trained to improve instruction following, agentic abilities, and preference alignment. This final stage felt conceptually similar to what we perceived to be typical RLHF with some added bells and whistles for the agentic age.
Importantly, Qwen did not specify whether or not preference training was only applied to outputs, and we assume that Qwen did apply direct preference optimization to the CoT due to their models being open weight and needing to abide by strict guidelines from the CCP.
Figure 1: Qwen3 Post-training Pipeline. Preference alignment is applied after reasoning training.
Summary of CoT direct pressures:
Direct pressure during RL is unclear, with plausible optimization applied to the CoT after RLVR.
GLM-4.5
Zhipu AI (creators of GLM-4.5) do something kind of strange. They train 3 separate expert models during their RL training stage initialized from the same base model. These three distinct expert models are independently trained in the following domains: Reasoning, General chat, and Agents. These separate expert models are then distilled into the final, general model. It’s unclear what sort of optimization pressure is applied to the CoT during these stages, and if extended reasoning is encouraged at all during the general chat or agent setting.
With separate training pipelines, we may expect CoT in agentic settings to have significantly different properties from CoT in "reasoning" settings, which include large amounts of training on multiple choice settings and open-ended math questions. This has implications for the monitorability of the CoT in agentic settings, which we arguably care much more about for control protocols and if this technique became widespread could heavily limit the generalizability of studies on CoT monitoring.
Summary of CoT direct pressures:
Details of direct pressure are unclear, different types of optimization pressure might be applied in agentic settings.
Stage 1, Long CoT cold-start SFT: This occurs after some continued pretraining, however minimal details are provided.
Stage 2, RLVR: They start with RLVR on reasoning tasks, where the reward includes a correctness and format term. Then, they gradually mix in general tasks where reward models provide the reward. They train the models CoT heavily against the reward model. They discuss how the reward model can be hacked due to a CoT length bias that is difficult to fix. During training, they iteratively catch the policy exploiting the reward model via length-seeking behaviour, and then attempt to re-calibrate the reward model.
Summary of CoT direct pressures:
Heavy CoT optimization against a reward model.
Llama Nemotron
Llama Nemotron is a reasoning model trained in three post-training stages.
Stage 1, Initial SFT: The model undergoes supervised fine-tuning on both long CoT datasets and non-reasoning tasks.
Stage 2, RLVR: Standard reinforcement learning with verifiable rewards using accuracy and format rewards.
Stage 3, Preference Optimization: RL training for preference optimization, including instruction following and RLHF in general chat domains. It is unclear whether the reward model in the RLHF phase sees the CoT.
Summary of CoT direct pressures:
Details of direct pressure during RL are unclear, but plausible optimization applied to the CoT after RLVR.
Kimi K2
Kimi K2 is not a reasoning model in the sense that it provides verbose CoTs like Deepseek’s R1 or OpenAI’s o series. Moonshot AI does provide some reasoning training to their models before release, but this reasoning training is subject to harsh length penalization. This length penalization results in the final model generating reasoning that is at most one paragraph long. Moonshot also states they apply preference alignment before and after reasoning training. Specifically, they conduct SFT with helpful, harmless, and honest (HHH) examples, then reasoning training, and finally RLAIF where it’s unclear whether or not the reward model has access to the CoT.
Summary of CoT pressures:
Cold start SFT, intense length penalization, and preference training after reasoning training.
Discussion
The most common formula for reasoning models we see is:
An initial SFT phase that includes a long CoT cold-start
An RLVR phase, where the model is trained primarily via a verified outcome-based reward
A general RL phase, where the model is trained on general tasks against reward models (With GLM 4.5 and Kimi K2 being an exception)
We do see evidence of notable alignment-relevant direct optimization pressure placed on some model CoTs. Most notably, Deepseek explicitly mentions training against a harmlessness reward model, while MiniMax train CoT so heavily against a reward model that it overoptimizes it. In other papers, it is often unclear whether the reward models or LLM-judges used have access to CoT. The SFT phases often also involve selection pressures on CoT, including processing and filtering for readability and quality
In general, models often have complex multi-stage post-training recipes. It is very likely that differences in these recipes could influence CoT properties, even if this does not directly involve CoT optimization pressure. For instance, large discrepancies in model’s ability to obfuscate their CoT under prompt pressure have been noted even within the Claude family. Replicating CoT studies with open weight reasoning models would allow us to make inferences about the types of practices that influence CoT monitorability, rather than attempting to make inferences based purely on black-box metrics.
We are excited for more safety research that leverages the knowledge of current practices used by open-weight model providers. Two years ago, it was not clear that the broader community would have much insight at all into frontier model practices. But the current gap between the frontier labs and open-weight labs is small, and the safety community should leverage this window of opportunity.
Open Questions & Research Directions
It seems to us that there are lots of low-hanging experiments that can and should be done to better understand how different aspects of the post-training pipeline affect CoT Monitorability. Below, we discuss safety relevant open questions grounded on the training regimes seen in the open-weight literature.
How do long CoT cold starts and other SFT procedures affect monitorability?
The creation of SFT data for most models likely involves choosing samples that score high on both action correctness and some CoT-related metric. While most CoT metrics currently used for filtering seem relatively benign and related to readability, some involve LLM-judges which could penalize misaligned reasoning. In cases where the action reward is poorly specified, this process could select for samples where a misaligned action is taken (e.g., sycophancy, reward hacks) but this is not verbalized in the CoT. Such samples could discourage verbalization of misaligned reasoning traces and encourage the obfuscation of important CoT traces.
Does training on cleansed CoT reduce the propensity of models to reason about deception?
For example, does a model that learns to verbalize reward hacking during RL have this property removed if trained on SFT examples that reward hack but lack these reasoning traces?
Apollo and OpenAI apply heavy optimization on the CoT through SFT - does this lead to obfuscation in ways similar to optimization during RL training?
Do any of the current open-weight models that have had alignment-relevant pressures placed on their CoT (e.g. Minimax 1) verbalize misaligned thoughts less than they would have otherwise?
To what extent does SFT on legible chain-of-thought improve monitorability?
This seems especially relevant for models with significant RLVR training that has led to decreases in human-legibility.
How does training CoT against a reward model during RL affect monitorability?
We have noted two instances of labs explicitly stating they have trained their CoT against reward models during RL (Minimax-M1 and Deepseek-R1).
Under what circumstances does training against a reward model for reasoning quality lead to CoT pathologies?
Why do some labs already train CoT against a reward model? What benefits do they get from this, and will avoiding training CoT against a reward model prove to be a high alignment tax for these labs now and/or in the future?
When does training for readability lead to CoT that is easier to monitor vs CoT that is obfuscated?
How do reasoning and non-reasoning training influence each other?
Many of the open-weight labs mentioned above have separate pipelines for training long reasoning traces through RLVF and preference training in distinct settings that are often single turn and require significantly less reasoning.
How does the order of training influence things?
Does applying preference training before reasoning training result in different outcomes compared to when it is conducted after (E.g. are harmful reasoning traces less obfuscated when RLHF comes before reasoning training?)
Why exactly does RLHF tend to come after reasoning, not visa-versa?
How effective are mitigation strategies like mind/face?
If strong output leakage is found, what does this imply for the relative order of preference and reasoning training?
How do fusion stages influence CoT across different domains ?
Specifically, does CoT have different properties in agentic settings compared to “reasoning” settings such as math and coding when trained in the style of GLM-4.5?
When fusion occurs, does the CoT remain the same in each domain? Or does substantial mixing of properties occur cross domain?
Do the CoTs from hybrid reasoning models have different properties relevant to monitorability?
How do relative magnitudes of pre-training, cold-start SFT, and RLVR influence monitorability?
Desirable CoT properties arise primarily during RLVR reasoning training. How exactly do these properties generalize to other domains?
Specifically, how does reasoning training generalize to the propensity to externalize reasoning on tasks where reasoning isn’t necessary?
How does Legibility trade off with Monitorability and Obfuscation?
How can we measure language drift?
How much training on verifiable rewards can we conduct before we should expect language drift to occur?
Does preventing language drift result in obfuscation?
Does forcing the model to reason in human-legible text encourage CoT pathologies such as internalized reasoning or steganography?
Final Thoughts
We find a handful of worrying trends in open-weight LLM training that could negatively affect the monitorability of CoT. In general Labs should be more explicit about CoT pressures they place on models. Once reliable evaluations for monitorability become available, these metrics should be evaluated at multiple points during training to better understand how different training steps affect monitorability.
Thanks to the open-weight labs for providing transparency into their training techniques which allow for third parties like us to audit these training techniques. Hopefully, these insights can guide future work on CoT monitorability over the next year making research more applicable to the practices actually implemented.
Introduction
Current reasoning models have surprisingly monitorable chains-of-thought: they struggle to control their CoT without direct optimization pressure applied during training (especially when CoT reasoning is necessary for task completion) and they find difficulty reasoning in all but the simplest ciphers.
This seems promising, but oh so fragile.
There are a handful of reasons for this fragility, which Korbak and friends outline well. Length control may force models to encode information in weird and dense ways that are difficult for humans to understand, linguistic drift during heavy reinforcement learning with verifiable rewards (RLVR) may be the default, or labs may be lured into optimizing away our faithful CoTs in order to appease their customers or regulators. We’re also already noticing some cracks in the foundation, with current models already seemingly exhibiting some CoT pathologies. For example, GPT-5 has been found to produce illegible gibberish within its CoT and models often fail to verbalize important reasoning steps.
But all in all, things seem to be going fairly well as far as creating models that mostly reason in a human understandable way in the situations we care about. In order to keep this happy accident around, we should be paying close attention to post-training practices that might influence CoT monitorability.
In this post, we review available details of open-weight training regimes in an attempt to better understand how frontier model training practices could influence CoT properties and to inform on CoT safety research directions.
We find many open-weight model providers either make no statements on the degree of optimization pressure applied to the CoT, or in cases such as MiniMax-M1, explicitly state training against the CoT. Researchers typically discuss optimization pressure in the context of a direct reward during RLVR (e.g. Baker et al. 2025’s discussion of training directly against reward hacking reasoning and Skaf et al. 2025’s findings regarding steganography generalization). However, even in the absence of CoT based rewards during reasoning training, developers are likely applying significant influence on the content of the CoT throughout other portions of the post-training pipeline. A prime example of this being extensive cold start supervised fine-tuning (SFT) on curated reasoning traces.
We have identified common practices across nearly all open-weight models. Some of these practices may influence the faithfulness of CoT but have been given little attention. We believe that these areas of post-training are likely to have a non-trivial influence on the faithfulness of CoT and are already being widely utilized, thus deserving further attention from the AI Safety community.
Common Practices:
How open-weight reasoning models are trained
Deepseek-R1
Deepseek-R1 is trained in four stages.
Stage 1, Long CoT Cold Start: An SFT dataset of long CoT’s is collected by processing and filtering outputs from Deepseek-R1-Zero to obtain reader-friendly reasoning.
Stage 2, RLVR: The model is then trained via RL on standard reasoning problems. The reward is output accuracy and language consistency applied to the CoT.
Stage 3, Rejection Sampling and Supervised Fine-Tuning: Applied in reasoning and general-purpose domains. In the reasoning domain they filter out CoTs with undesirable qualities such as mixed languages, long paragraphs, and code blocks. An LLM-judge is used to assess some outputs, but it is unclear whether the judge sees CoTs. Notably, they refer to fine-tuning "DeepSeek-V3-Base," which creates ambiguity about whether this stage was applied to the RLVR-trained model or the base model.
Stage 4, General RL phase: Finally the model is jointly trained via RL on both reasoning and general problems. For reasoning, the reward is a rule-based accuracy and format reward. For general purpose, reward model(s) are used. The helpfulness reward model only sees outputs. The harmlessness reward model sees both CoT and outputs.
Summary of CoT details and direct pressures:
SFT datasets are filtered for readability. They optimize the CoT against a reward model during harmlessness training.
Qwen3
The post-training for the Qwen3 model family is broken down into 4 stages: Long-CoT Cold Start, Reasoning RL, Thinking Mode Fusion, and General RL.
Stage 1, Long CoT Cold Start: Their cold start SFT data contains notable CoT filtering, where they excluded reasoning traces that indicated guesswork, inconsistencies between reasoning and final answer, and incomprehensible text.
Stage 2, RLVR: Consisted of general reasoning training on difficult questions with verifiable data. This plausibly constituted a majority of the compute for post-training, although they were notably sparse on details in this section.
Stage 3, Thinking Mode Fusion: They train the “thinking” model via SFT with the ability to output responses with no CoT when given specific tags within the system prompt.
Stage 4, General RL: They train on 20 distinct tasks where the model is trained to improve instruction following, agentic abilities, and preference alignment. This final stage felt conceptually similar to what we perceived to be typical RLHF with some added bells and whistles for the agentic age.
Importantly, Qwen did not specify whether or not preference training was only applied to outputs, and we assume that Qwen did apply direct preference optimization to the CoT due to their models being open weight and needing to abide by strict guidelines from the CCP.
Figure 1: Qwen3 Post-training Pipeline. Preference alignment is applied after reasoning training.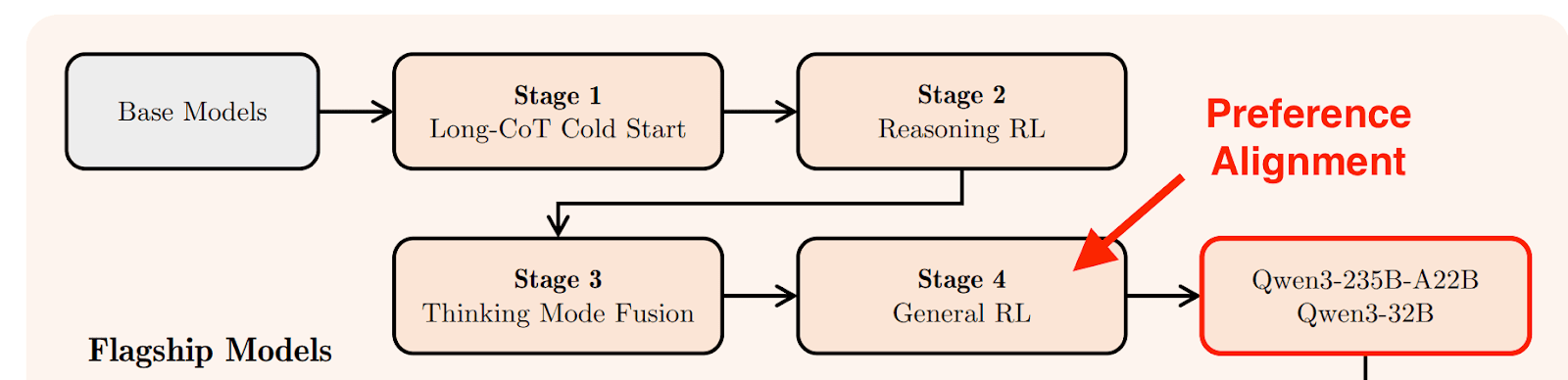
Summary of CoT direct pressures:
Direct pressure during RL is unclear, with plausible optimization applied to the CoT after RLVR.
GLM-4.5
Zhipu AI (creators of GLM-4.5) do something kind of strange. They train 3 separate expert models during their RL training stage initialized from the same base model. These three distinct expert models are independently trained in the following domains: Reasoning, General chat, and Agents. These separate expert models are then distilled into the final, general model. It’s unclear what sort of optimization pressure is applied to the CoT during these stages, and if extended reasoning is encouraged at all during the general chat or agent setting.
With separate training pipelines, we may expect CoT in agentic settings to have significantly different properties from CoT in "reasoning" settings, which include large amounts of training on multiple choice settings and open-ended math questions. This has implications for the monitorability of the CoT in agentic settings, which we arguably care much more about for control protocols and if this technique became widespread could heavily limit the generalizability of studies on CoT monitoring.
Summary of CoT direct pressures:
Details of direct pressure are unclear, different types of optimization pressure might be applied in agentic settings.
MiniMax-M1
Notably, Minimax-M1 is the precursor to the recent Minimax-M2, which is the current SOTA open-weight model that rivals the coding performance of Claude 4 Opus.
Stage 1, Long CoT cold-start SFT: This occurs after some continued pretraining, however minimal details are provided.
Stage 2, RLVR: They start with RLVR on reasoning tasks, where the reward includes a correctness and format term. Then, they gradually mix in general tasks where reward models provide the reward. They train the models CoT heavily against the reward model. They discuss how the reward model can be hacked due to a CoT length bias that is difficult to fix. During training, they iteratively catch the policy exploiting the reward model via length-seeking behaviour, and then attempt to re-calibrate the reward model.
Summary of CoT direct pressures:
Heavy CoT optimization against a reward model.
Llama Nemotron
Llama Nemotron is a reasoning model trained in three post-training stages.
Stage 1, Initial SFT: The model undergoes supervised fine-tuning on both long CoT datasets and non-reasoning tasks.
Stage 2, RLVR: Standard reinforcement learning with verifiable rewards using accuracy and format rewards.
Stage 3, Preference Optimization: RL training for preference optimization, including instruction following and RLHF in general chat domains. It is unclear whether the reward model in the RLHF phase sees the CoT.
Summary of CoT direct pressures:
Details of direct pressure during RL are unclear, but plausible optimization applied to the CoT after RLVR.
Kimi K2
Kimi K2 is not a reasoning model in the sense that it provides verbose CoTs like Deepseek’s R1 or OpenAI’s o series. Moonshot AI does provide some reasoning training to their models before release, but this reasoning training is subject to harsh length penalization. This length penalization results in the final model generating reasoning that is at most one paragraph long. Moonshot also states they apply preference alignment before and after reasoning training. Specifically, they conduct SFT with helpful, harmless, and honest (HHH) examples, then reasoning training, and finally RLAIF where it’s unclear whether or not the reward model has access to the CoT.
Summary of CoT pressures:
Cold start SFT, intense length penalization, and preference training after reasoning training.
Discussion
The most common formula for reasoning models we see is:
We do see evidence of notable alignment-relevant direct optimization pressure placed on some model CoTs. Most notably, Deepseek explicitly mentions training against a harmlessness reward model, while MiniMax train CoT so heavily against a reward model that it overoptimizes it. In other papers, it is often unclear whether the reward models or LLM-judges used have access to CoT. The SFT phases often also involve selection pressures on CoT, including processing and filtering for readability and quality
In general, models often have complex multi-stage post-training recipes. It is very likely that differences in these recipes could influence CoT properties, even if this does not directly involve CoT optimization pressure. For instance, large discrepancies in model’s ability to obfuscate their CoT under prompt pressure have been noted even within the Claude family. Replicating CoT studies with open weight reasoning models would allow us to make inferences about the types of practices that influence CoT monitorability, rather than attempting to make inferences based purely on black-box metrics.
We are excited for more safety research that leverages the knowledge of current practices used by open-weight model providers. Two years ago, it was not clear that the broader community would have much insight at all into frontier model practices. But the current gap between the frontier labs and open-weight labs is small, and the safety community should leverage this window of opportunity.
Open Questions & Research Directions
It seems to us that there are lots of low-hanging experiments that can and should be done to better understand how different aspects of the post-training pipeline affect CoT Monitorability. Below, we discuss safety relevant open questions grounded on the training regimes seen in the open-weight literature.
How do long CoT cold starts and other SFT procedures affect monitorability?
The creation of SFT data for most models likely involves choosing samples that score high on both action correctness and some CoT-related metric. While most CoT metrics currently used for filtering seem relatively benign and related to readability, some involve LLM-judges which could penalize misaligned reasoning. In cases where the action reward is poorly specified, this process could select for samples where a misaligned action is taken (e.g., sycophancy, reward hacks) but this is not verbalized in the CoT. Such samples could discourage verbalization of misaligned reasoning traces and encourage the obfuscation of important CoT traces.
How does training CoT against a reward model during RL affect monitorability?
We have noted two instances of labs explicitly stating they have trained their CoT against reward models during RL (Minimax-M1 and Deepseek-R1).
How do reasoning and non-reasoning training influence each other?
Many of the open-weight labs mentioned above have separate pipelines for training long reasoning traces through RLVF and preference training in distinct settings that are often single turn and require significantly less reasoning.
How does Legibility trade off with Monitorability and Obfuscation?
Final Thoughts
We find a handful of worrying trends in open-weight LLM training that could negatively affect the monitorability of CoT. In general Labs should be more explicit about CoT pressures they place on models. Once reliable evaluations for monitorability become available, these metrics should be evaluated at multiple points during training to better understand how different training steps affect monitorability.
Thanks to the open-weight labs for providing transparency into their training techniques which allow for third parties like us to audit these training techniques. Hopefully, these insights can guide future work on CoT monitorability over the next year making research more applicable to the practices actually implemented.